來源:周到

一直以來,智能駕駛功能“王不見王”的局面,如今要有變化了。
本月初,有特斯拉員工在進行直播時“無意”中泄露,FSD(Full-Self Driving,“完全自動駕駛”功能)的內測版V12疑似正在中國進行測試。顯然,在解決了信息安全合規問題之後,在美國大殺四方的FSD,終於有望來中國和華爲城區NCA一決高下了。
不過對於兩家企業的高階智駕產品,究竟誰在中國的表現會更厲害這個問題,外界一直有不少爭論。一些人認爲,中美兩國的道路環境、交通規則和用戶習慣都存在不小的區別,因此FSD來到中國注定會水土不服,在華爲面前落得下風。
但是,幾乎每一個交流的技術人士都告訴筆者,特斯拉在端到端架構上取得的領先優勢,絕對不容小覷。因爲在美國,已經實現量產的FSD BETA V12給到了全球車企與科技公司足夠大的震撼。
那么問題來了,由特斯拉率先量產,且在國內被華爲、蔚小理頻頻提及的端到端架構,到底是什么?特斯拉如今“僅剩”的這一項優勢,其內部原理到底是什么?爲此,虎嗅汽車暗信號團隊經過多方訪談和調研,爲大家呈現這一前沿和復雜概念背後,技術原理和工程難點到底有哪些。
端到端:這邊豬進去,那邊香腸出來
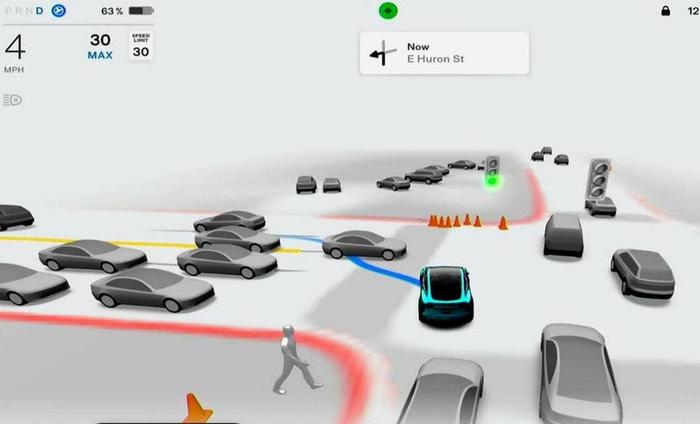
只要你在B站或者各類帶有視頻內容的社交網站上搜索“特斯拉 FSD V12”,就能看到大量美國車主曬出的FSD體驗視頻。在這些視頻中,已經升級到最新系統的特斯拉汽車在繁忙的美國街道中,智駕表現堪稱“類人”。

從上圖可以看到,車主駕駛的Model Y在路遇園林工人鋸下的樹枝時幾乎“沒打磕巴”,在無需接管的狀態下直接操縱車輛繞开了障礙物。
而在更多視頻裏,特斯拉汽車完成了太多當前其他品牌車型智駕功能沒有的表現:面對正在施工的道路,在樁桶的引導下駛入對向車道逆行,並在施工路段結束後回到正向車道;在沒有紅綠燈的十字路口,准確遵循“STOP”標志停車並等到左側車輛先行;在到達目的地後並不馬上退出,並會在人類駕駛員沒有給出進一步指令的前提下,自動靠邊停車。而如果該地點無法靠邊,便自動向前行駛尋找車位……
這一切實現的基礎,便是智能駕駛的端到端架構。在筆者看來,這對於汽車而言可謂是第一個接近於ChatGPT的發明,將極大地改善智能駕駛體驗。
所謂端到端(end-to-end)架構,其對應的是如今絕大多數車企採用的模塊化架構。在過去,工程師們將一輛車的智能/自動駕駛分爲感知、決策規劃和控制分爲三個模塊:感知、決策和控制。
其中,感知模塊通過車身傳感器信息的接入,實現對道路中車輛、行人以及各類障礙物的識別,並完成對車輛自身的精確定位。決策和控制模塊(Planing and Control)負責對於前方移動障礙物的軌跡、速度進行預判,並規劃出車輛行進的路线,保障車輛安全行駛。最後,系統將計算得出的操作指令下發給油門、剎車和轉向系統,操作車輛行駛。
對於這個架構,其實我們可以理解爲“規則執行器”。無論是感知到障礙物特徵,並基於數據庫對其進行分類,還是在具體場景中根據周遭環境變化而進行相應的操作,系統都是根據一條條工程師寫好的規則進行執行。在業內,模塊化的智能/自動駕駛架構也叫做“rule-based”。
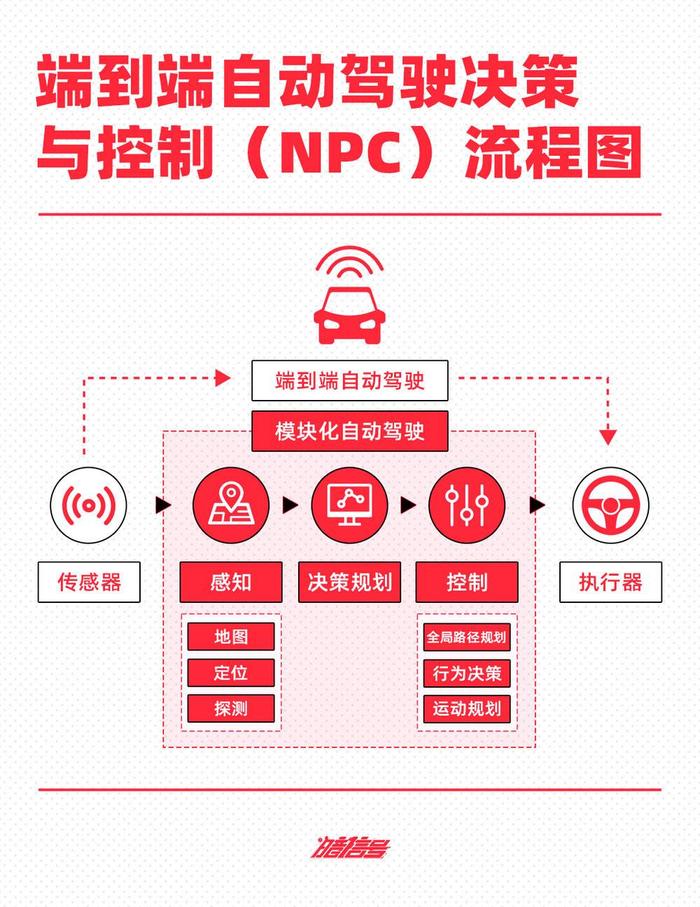
但端到端的架構下,系統將感知與PNC模塊直接打包進了一個大模型。傳感器的數據直接輸入到模型中,經過計算後直接輸出結果,發送給執行器。而大模型則是基於大量測試車輛以及用戶實際駕駛的真實數據進行訓練而成的,能夠主動學習人類的駕駛習慣。
從上圖中就可以看到,傳感器通過大模型直接連接到了執行器,這就是所謂的“端到端”。用一個不恰當的例子來講,這就相當於一個整體打包的食品生產线:這邊豬跑進去,另一邊香腸、滷煮、肉皮凍直接出來。

相比較模塊化,端到端架構的優勢顯而易見。首先,系統不再是基於由工程師所編寫的規則進行決策和控制,而是通過數據驅動(data-dirvien)實現成長,這就讓系統處理問題具備了泛化的能力。
在過去,如果面對規則中不存在的場景,模塊化架構的智能汽車往往會退出系統並提示駕駛員接管,抑或採取了錯誤的操作造成事故。而端到端架構則能夠在面對極端場景(也就是corner case)時,像人類一樣基於“直覺”採取包括繞行、避險乃至“硬开”等方式行駛,從而極大地提升安全性和用戶體驗。
其次,相比較由一條條規則和一個個模塊構成的老系統,端到端架構能夠在提升決策效率的同時,極大地降低了代碼量。例如特斯拉就聲稱,FSD Beta V12系統相比較過去,減少了30萬行代碼。這不僅會降低車端的存儲壓力,還能極大提升系統的簡潔度,從而改善運行效率。
最後,也是最重要的一點,端到端架構是一個真正的“大模型”,已經具備了人類駕駛員的部分特徵。在未來隨着模型訓練數據量的不斷提升和迭代,我們有望在端到端架構下成功打造汽車人工智能,並最終取代人類駕駛員,實現真正的L4級無人駕駛。
更重要的是,模塊化的架構盡管在積累了足夠多的策略後能在日常道路環境中順暢行駛,但面對“計劃外”的場景(也就是corner case)時,仍然會退出或做出錯誤決策。這不僅影響用戶體驗,還會發生危險。
但真正形成了AI大模型能力的端到端架構不再基於既定的規則進行規劃和控制,而是能夠像人一樣,憑借“經驗”和乃至“直覺”开車,因此不再強調對corner case的學習,能帶給用戶更接近於人類的駕駛體驗。
不過,縱然業界都已經明白了端到端架構的好處,但至今在量產車上該技術的汽車品牌,也有且僅有特斯拉一家。因爲從技術本身的實現上看,要讓車輛像人一樣預測道路上其他交通參與者的行爲,並制定安全高效的行駛策略,堪稱是自動駕駛技術中,最難的一個任務。
如何讓機器像人一樣开車?
需要說明的是,國內一些企業已經在宣傳自己實現了“大模型上車”。但是,他們目前僅僅是將感知部分實現了“端到端”。其實,在感知層面實現所謂的數據驅動,依舊只是讓系統自主識別目標物類型、道路環境特徵並通過高精地圖等方式實現車輛定位,後續的PNC依舊需要依照工程師寫好的策略執行。而這已經是業界的通行方案了。
但是,只有一半的大模型,顯然不是真正的“端到端”。正如前文所述,事情的關鍵在於,能不能讓車輛像人一樣,在“看”到並認識到前方道路環境後,自主選擇最優路徑前進。
要理解這一問題,我們首先要拆解,PNC實現端到端的過程中需要解決哪些問題。在去年的9月的NIO IN 2023蔚來創新科技日上,該公司智能駕駛研發副總裁任少卿曾分享過該公司的端到端PNC技術架構,屬於業界少見的,能公开詳細講解技術思路的實際案例。通過他的解讀和資料解析,我們能夠對於PNC過程中需要解決的問題,有一個大概的框架。
需要說明的是,蔚來的方案在業界也並非獨一無二,大家的技術路线其實大同小異。選取該公司作爲案例的原因,在於這是公开資料中,筆者能夠找到的,相對而言最爲清晰全面的一個。

首先來看蔚來整個PNC的規劃方面,如圖所示,在一個路口的典型場景,系統在接收到傳感器的信號後,會對環境中的動態物體和靜態物體進行分類,並篩選出在車輛行駛路徑上,可能會造成影響的目標。
伴隨着時間的變化,交通參與者下一步的行動也會隨之改變。如果想要盡可能提前更多時間預測目標行爲,難度就會幾何級提升。例如,系統若想預測10個目標物體此刻可能的行爲,其復雜度爲2^10=1024,那么提前5秒預測的話,復雜度就上升到了1024^5,也就是10^15。
在其中,系統會利用動態場景編碼、動態元素編碼、動態元素交互編碼和動靜態交互編碼對於每一個目標物,也就是交通參與者的行爲進行預測,最終得出可能的交互結果。
在上圖最右側的交互場景表達中可以看到,如果路口中有10個交通參與者,最終根據排列組合可以形成10 ~ 100種預測的交互模式。
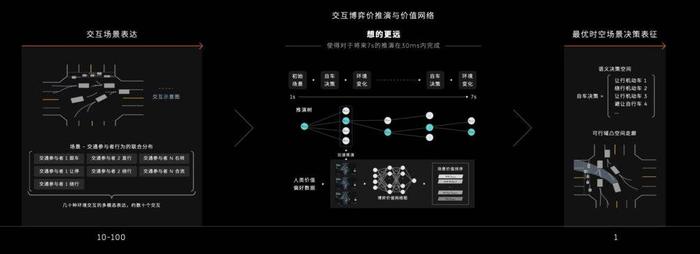
在獲得環境交互的場景表達結果後,系統就需要根據對於其他交通參與者的行爲推演,完成進一步對車輛行駛的路徑進行規劃了。蔚來的目標是在30毫秒內對環境未來7秒的交通環境進行預測,這比標准電影中的一幀畫面的時間還短。
在這過程中,車輛對於不同交通參與者存在可能的多種決策。舉例來說,對於第一輛車,系統可能會採取讓行、繞行、加速通過,對於第二個行人也可能有讓行、左側繞行、右側繞行等等各種決策。而對前一個參與者產生不同決策之後,後一個目標也會勢必產生連鎖反應。因此就產生了圖中央部分的決策樹形結構。而系統需要的,則是採取最優解,高效、安全地通過路口。
注意,其中最關鍵的部分來了:工程師需要在這一過程中,爲系統設置場景價值排序,引導系統選取最佳路徑。例如排在第一的可能是保證乘客的舒適,第二是通行效率,第三是安全,第四是遵循交通法規……當然這些只是筆者的舉例,不同企業可能會有差別。但這一切的核心目的,都是讓車輛在PNC的過程中,價值取向和人類更接近,從而提供最舒適的決策方案。
在模型迭代的過程中,這被稱爲RLHF(人類反饋強化學習),是工程師需要大模型強加學習的部分。爲此,开發團隊會給系統喂大量用戶的實際駕駛行爲數據,以及其他交通參與者對於車輛行爲反饋的數據。
說句題外話,之所以包括特斯拉、蔚來、小鵬等絕大多數智能汽車品牌會對於用戶的駕駛行爲進行評分,並對於評分高的用戶優先推送智駕功能,其背後的另一個原因便在於這部分高分用戶的駕駛行爲對於系統而言是優良的學習數據。車企的這種做法一方面是給用戶以安全駕駛激勵和引導,另一方面也是引導更多用戶提升駕駛的規範性,進而爲系統提供更多優良數據。
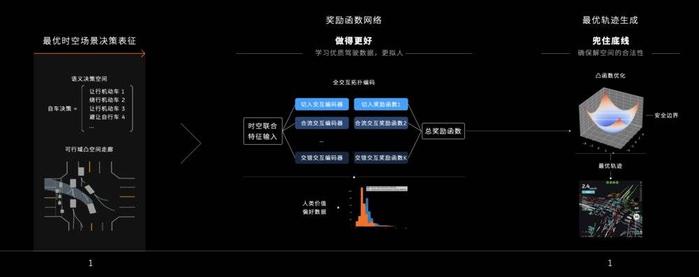
最後在決策樹中選取了最佳路徑後,系統會得出圖片左側顯示的“可行域凸空間走廊”。在這條可通行區域裏,大模型會結合全交互拓撲編碼,以及再一次疊加人類價值偏好數據,最終生成右圖中最優的行駛軌跡。
上面這一段文字可能有些燒腦,但這已經是筆者用最簡單平實的語言,結合蔚來的技術方案給各位闡釋出的PNC路徑。這時可能有用戶就要問下一個問題了:既然方法和路徑已經解決了,爲何現在端到端架構還是沒有量產上車呢?
這就需要提到下一個問題:大模型的不可解釋性,和車企开發規程之間的矛盾和衝突了。
車企的標准“老鞋”,走不了端到端的新路?
對於大模型的不可解釋性,很多人可能已經略有耳聞。對於這個概念,簡而言之,由於大模型是通過大量的數據訓練而成,但其如何得出具體結果的過程並不透明,無法像傳統規則算法那樣進行詳細解釋。舉例來說,就是無論是ChatGPT還是文心一言,都無法避免在一些專業問題上“瞎編亂造”。
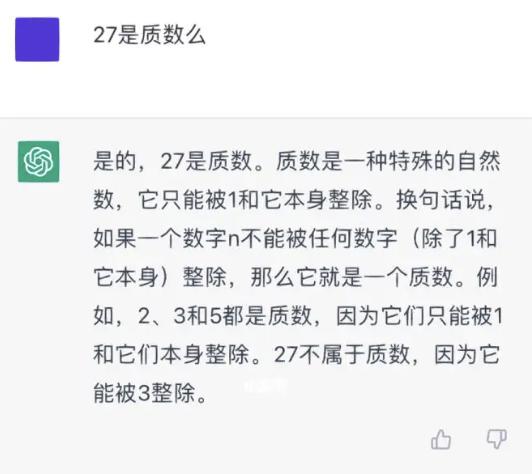 “所以,27到底是不是質數?”
“所以,27到底是不是質數?”
對於一個聊天機器人來說,這顯然不會出太大的事故,但放在以安全爲准繩的汽車行業,便是一種不可接受的行爲了。尤其是對於很多依靠供應商提供智駕方案的傳統車企來說,如何驗收端到端架構的智能駕駛系統,一直是個難題。
在國內某知名智能駕駛公司任職的不害(化名)告訴筆者,他曾經服務過一家知名德系豪華品牌。該公司像很多汽車企業一樣,對於智能駕駛功能有着一套顆粒度細致到代碼層的开發標准,其中包含超過100個safety goal(安全目標),其中涉及AEB(自動緊急制動系統)的就有7個。對於其中的每一項,車企都會打分,並對代碼進行審核。
舉例來說,其中一條安全目標是這樣寫的:
“要求描述:沒有可用的或需要穩定化相關系統的制動幹預應被防止。安全狀態:AEB不進行縱向控制幹預。”
“接受標准:最大故障注入後橫擺率變化取決於車速。故障注入後10秒內的目標值如下:車速80 km/h時爲4°/s,車速130 km/h時爲3°/s”
很晦澀是吧?實際上筆者選取的是其中最短的一條。不害透露,這些安全目標一方面爲車企的驗收提供了指引,另一方面也給供應商的开發給出了方向。這套流程原本在模塊化架構下運行得很順暢,但對於端到端智能駕駛而言卻無法適配了。
“傳統車企對於功能安全、預期功能安全的相關指標,是基於FSC(功能安全概念)、PSC(產品安全案例)和SSR(系統安全要求)進行的。基於各家車企SSR的不同,供應商會各自寫代碼开發產品。”不害說道。
 傳統的汽車測試,只能驗證“功能”,而無法考核“能力”
傳統的汽車測試,只能驗證“功能”,而無法考核“能力”
顯然,對於模塊化架構的智能駕駛,車企是有一整套开發指引和驗收標准的,能夠從代碼層面確保功能安全。但對於參數復雜且處於黑箱狀態的端到端架構,車企無法保證其在日常行駛的過程中不會出事故。
換句話說,通過駕校的考試,只能說明一個人具備了基本的駕駛知識,拿到了开車上路的資格。但此人到底开得好不好,以及會不會因爲大腦短路,开車衝入了河裏,這事駕校無法保證。
“也就是特斯拉這樣的汽車企業,能夠一定程度上繞過汽車行業的傳統开發標准,實現端到端架構上車。”不害調侃道,“這事放在傳統車企,軟件和測試部門肯定通不過。”
其實就算是特斯拉,其FSD V12也並非一個徹頭徹尾的端到端架構智駕系統,其上還有個3000行代碼左右的策略“安全殼”,以便兜住安全的底线。“例如,當大模型操作車輛向左變道後,如果左側後向右車輛高速駛來,安全殼中的策略規則就會制止這次變道,把風險規避掉。”不害介紹道。
不過,這個安全殼到底畢竟是一個打補丁的產物。其中到底要覆蓋多少場景,依舊是工程師們需要思考和取舍的問題。更何況,如果安全殼做得太大,又相當於回到了模塊化架構下,儼然畫蛇添足。
當然,端到端架構要實現量產上車,需要面對的挑战和困難遠不止文中提到的這些,筆者只是選取了其中幾個比較有代表性的問題進行介紹。但盡管如此,端到端架構相比較如今模塊化架構的優勢,依舊是在代際層次上的。相信隨着我們國內衆多汽車品牌,尤其是新勢力們的努力,搭載端到端架構的智能汽車很快就將和我們見面了。
寫在最後:
正如前文提到的,相比較傳統車企,像特斯拉這樣的造車新勢力們在端到端架構的量產節奏方面,大概率會擁有更大的優勢。實際上從今年下半年开始,就將有越來越多的汽車品牌在我國开放新技術的量產交付。
華爲在今年4月北京車展前的發布會上透露,採用了端到端架構的ADS 3.0,預計會首搭在享界S9上;小鵬在上個月的AI Day上宣布將上线端到端大模型,並在今年8月實現“全國每條路都能开”;蔚來在今年上半年上线了端到端的主動安全功能,並在下半年量產端到端城市智能駕駛;理想則在這方面的傳播相對“摟着”,只是說在今年三季度推送“無圖NOA(城市領航輔助)”,在今年年底或明年年初推出端到端大模型驅動的L3自動駕駛體系。
顯然,如果特斯拉今年三季度真的能在國內推送FSD的V12版本的話,將大概率會遭遇一場國內汽車品牌的“三英战呂布”。究竟鹿死誰手,顯然是一場值得期待的好戲。
注:特別鳴謝智能駕駛公司技術人員“不害”對本文提供的信息支持
特別聲明:以上文章內容僅代表作者本人觀點,不代表新浪網觀點或立場。如有關於作品內容、版權或其它問題請於作品發表後的30日內與新浪網聯系。標題:特斯拉,要跟華爲开战了?
地址:https://www.utechfun.com/post/388101.html