
誒,大夥有沒有發現,這兩年的科技趨勢,和以往幾年都不大相同。
AI大模型,成爲了科技圈的香餑餑。
用戶需求的日益增長,推動了AI技術的進化。隨着大語言模型的應用場景日益增多,它們开始在我們的生活中扮演着越來越重要的角色。
尤其是休闲娛樂和實際工作中,大語言模型的應用變得越來越普遍。這些模型以其自然的語義能力、強大的數據處理能力和復雜任務的執行效率,爲用戶提供了前所未有的便利,甚至是以往人們不敢想象的數字陪伴感。
不過,隨着大語言模型的高速普及下,雲端大模型的局限性逐漸顯現出來。

連接緩慢,成本高昂,還有成爲熱議話題的數據隱私問題,沒有人可以輕易忽視。最重要的是,基於各種制度和倫理道德的雲端審核制度,進一步限制了大語言模型的自由。
本地部署,似乎爲我們指引了一條新的道路。
隨着本地大模型的呼聲越來越高,今年Github和Huggingface上湧現出不少相關的項目。在多番研究後,我也順藤摸瓜,拿到了本地部署大模型的簡單方法。
So,本地部署對我們的AI體驗來說,到底是錦上添花,還是史詩級增強?
跟着小雷的腳步,一起來盤盤。
本地大模型到底是個啥?
开始前,先說點闲話。
就是咋說呢,可能有些讀者還是沒懂「本地大模型」的意思,也不知道這有啥意義。
總而言之,言而總之。
現階段比較火的大模型應用,例如國外的ChatGPT、Midjourney等,還有國內的文心一言、科大訊飛、KIWI這些,基本都是依賴雲端服務器實現各種服務的AI應用。

(圖源:文心一言)
它們可以實時更新數據,和搜索引擎聯動整合,不用佔用自家電腦資源,把運算過程和負載全部都放在遠端的服務器上,自己只要享受得到的結果就可以了。
換句話說,有網,它確實很牛逼。
可一旦斷網,這些依賴雲端的AI服務只能在鍵盤上敲出「GG」。
作爲對比,本地大模型,自然是主打在設備本地實現AI智能化。
除了不用擔心服務器崩掉帶來的問題,還更有利於保護用戶的隱私。

畢竟大模型運行在自己的電腦上,那么訓練數據就直接存在電腦裏,肯定會比上傳到雲端再讓服務器去計算來得安心一點,更省去了各種倫理道德雲端審核的部分。
不過,目前想要在自己的電腦上搭建本地大模型其實並不是一件容易的事情。
較高的設備要求是原因之一,畢竟本地大模型需要把整個運算過程和負載全部都放在自家的電腦上,不僅會佔用你的電腦機能,更會使其長時間在中高負載下運行。
其次嘛…
從Github/Huggingface上琳琅滿目的項目望去,要達成這一目標,基本都需要有編程經驗的,最起碼你要進行很多運行庫安裝後,在控制台執行一些命令行和配置才可以。
別笑,這對基數龐大的網友來說可真不容易。
那么有沒有什么比較「一鍵式」的,只要設置運行就可以开始對話的本地應用呢?
還真有,Koboldcpp。
工具用得好,小白也能搞定本地大模型
簡單介紹一下,Koboldcpp是一個基於GGML/GGUF模型的推理框架,和llama.cpp的底層相同,均採用了純C/C++代碼,無需任何額外依賴庫,甚至可以直接通過CPU來推理運行。

(圖源:PygmalionAI Wiki)
當然,那樣的運行速度會非常緩慢就是了。
要使用Koboldcpp,需要前往Github下載自己所需的應用版本。
當然,我也會把相對應的度盤鏈接放出來,方便各位自取。
目前Koboldcpp有三個版本。
koboldcpp_cuda12:目前最理想的版本,只要有張GTX 750以上的顯卡就可以用,模型推理速度最快。
koboldcpp_rocm:適用於AMD顯卡的版本,基於AMD ROCm开放式軟件棧,同規格下推理耗時約爲N卡版本的3倍-5倍。
koboldcpp_nocuda:僅用CPU進行推理的版本,功能十分精簡,即便如此同規格下推理耗時仍爲N卡版本的10倍以上。
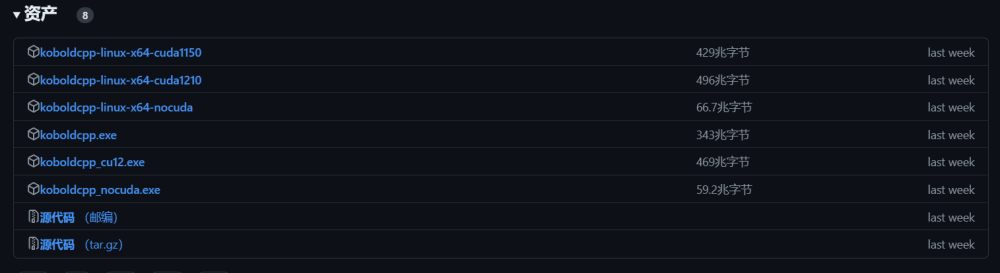
(圖源:Github)
打开軟件後,首先可以關注一下Presets選項。
軟件首頁的Presets裏,分爲舊版N卡、新版N卡、A卡、英特爾顯卡等多種不同模式的選擇。
默認情況下,不設置任何參數啓動將僅使用CPU的OpenBLAS進行快速處理和推理,運行速度肯定是很慢的。
作爲N卡用戶,我選用CuBLAS,該功能僅適用於Nvidia GPU,可以看到我的筆記本顯卡已經被識別了出來。
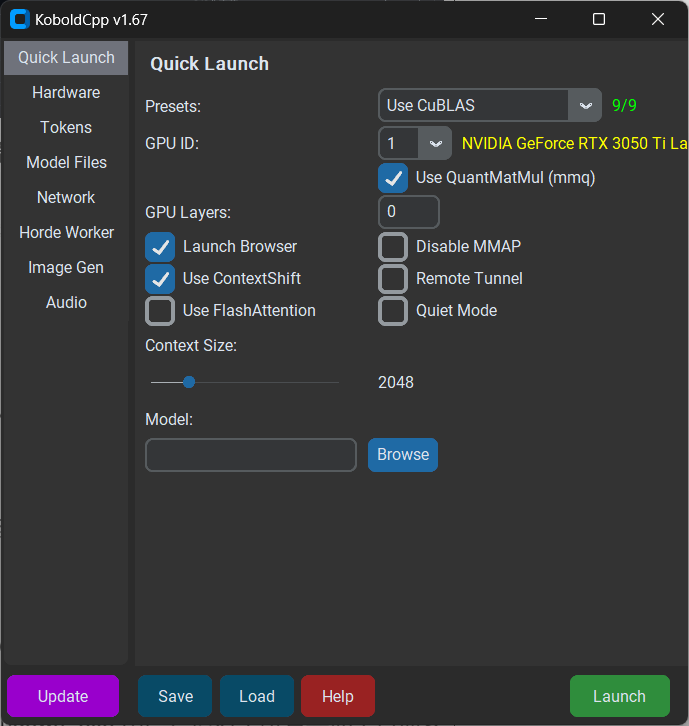
(圖源:雷科技)
對於沒有Intel顯卡的用戶,可以使用CLblast,這是OPENCL推出的、可用於生產環境的开源計算庫,其最大的特徵是更強調通用性,至於性能方面本人並沒有做過詳細測試。
另一個需要在主頁調節的部分是Context Size。
想要獲得更好的上下文體驗,最好將其調整至4096,當然Size越大,能記住的上下文就越多,但是推理的速度也會受到顯著影響。
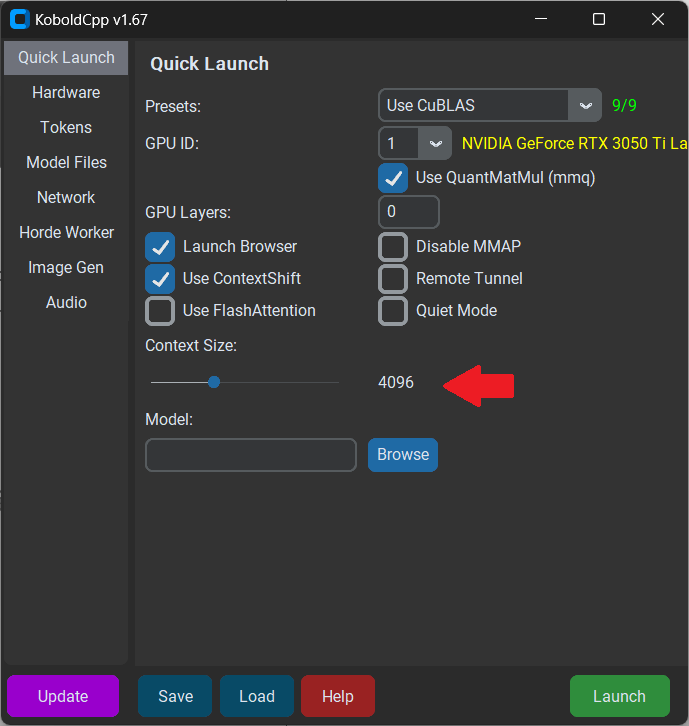
(圖源:雷科技)
再往下,就是載入大模型的部分。
目前开源大模型主要都在huggingface.co下載,沒有出海能力的話,也可以在國內HF-Mirror鏡像站或是modelscope魔搭社區下載。
結合個人實際體驗,我推薦兩款不錯的本地大模型:
CausalLM-7B
這是一款在LLaMA2的基礎上,基於Qwen 的模型權重訓練的本地大模型,其最大的特徵就是原生支持中文,顯卡內存8G以下的用戶建議下載CausalLM-7B,8G以上的可以下載CausalLM-14B,效果更好。
(圖源:modelscope)
MythoMax-L2-13B
原生語言爲英語的大模型,特徵是擁有較強的文學性,可以在要求下撰寫出流暢且具有閱讀性的小說文本,缺點是只能通過輸入英語來獲得理想的輸出內容,建議普通消費者使用MythoMax-L2-13B。
如果只是想使用大語言模型的話,其他部分不需要做調整,直接點擊啓動,你選擇的模型就可以在本地加載好了。
一般來說,接下來你還得給大模型部署前端才能使用。
不過Koboldcpp最大的特點,就是在llama.cpp的基礎上,添加了一個多功能的Kobold API端口。
這個端口,不僅提供了額外的格式支持、穩定的擴散圖像生成、不錯的向後兼容性,甚至還有一個具有持久故事、編輯工具、保存格式、內存、世界信息、作者注釋、人物、場景自定義功能的簡化前端——Kobold Lite。
大致上,界面就像這樣。
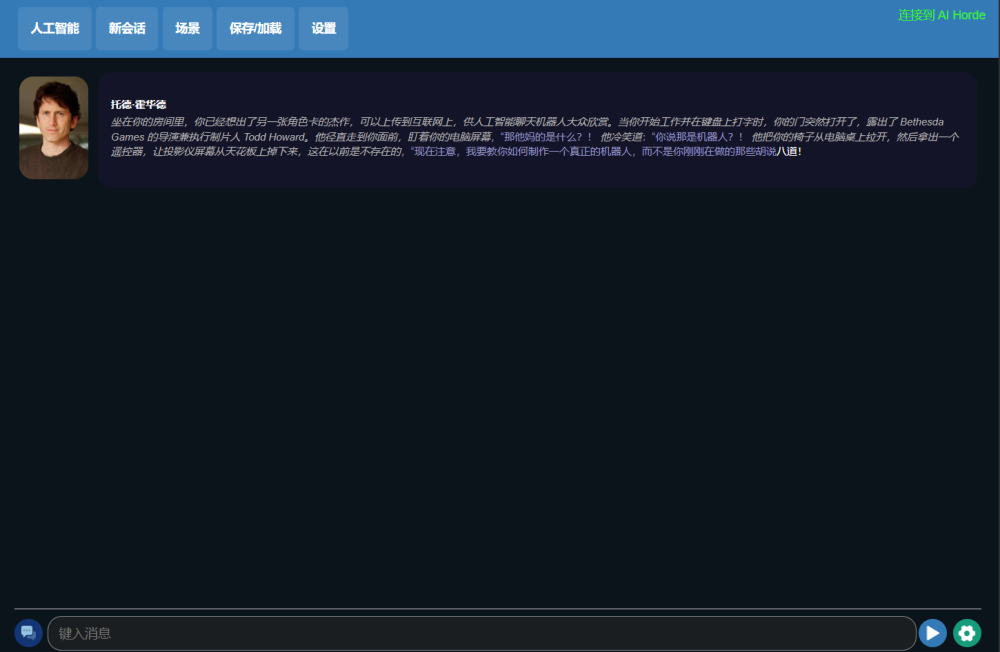
(圖源:雷科技)
功能也很簡單。
人工智能、新會話就不用說了,點擊上方的「場景」,就可以快速啓動一個新的對話場景,或是加載對應角色卡。
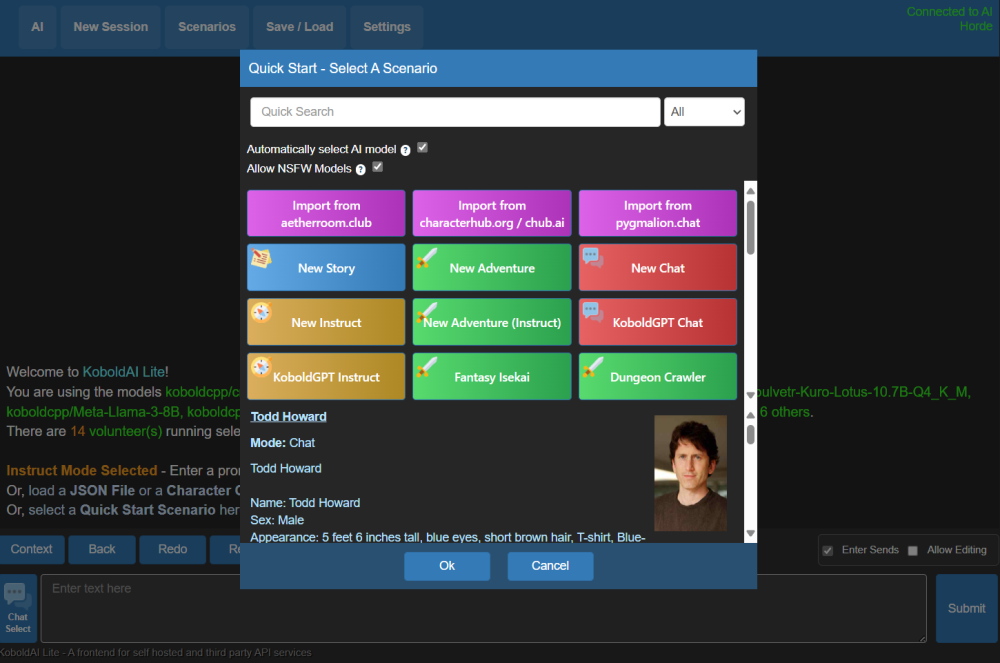
(圖源:雷科技)
像這樣,加載你擁有的AI對話情景。
「保存/加載」也很一目了然,可以把你當前的對話保存下來,隨時都能加載並繼續。
在「設置」中,你可以調節一些AI對話的選項。
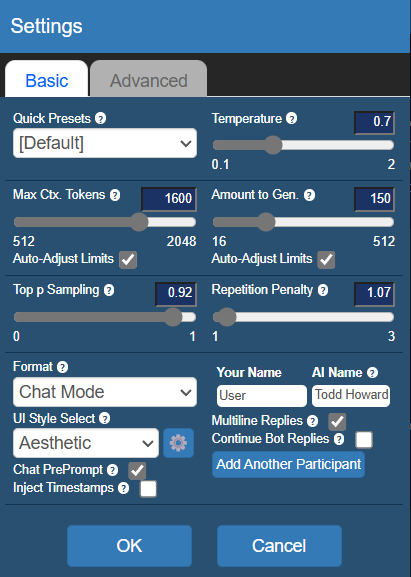
(圖源:雷科技)
其中,Temperature. 代表着對話的隨機性,數值越高,生成的對話也就會越不可控,甚至可能超出角色設定的範圍。
Repetition Penalty. 可以抑制對話的重復性,讓AI減少重復的發言。
Amount to Gen.是生成的對話長度上限,上限越長,所需時間也會更長,重點是在實際體驗中,過高的生成上限會導致AI胡言亂語,個人並不建議把這個值拉到240以上。
Max Ctx. Tokens. 是能給大模型反饋的關鍵詞上限,數據越高,前後文關系越緊密,生成速度也會隨之變慢。
完成設置後,就可以和todd howard來場酣暢淋漓的對話了。
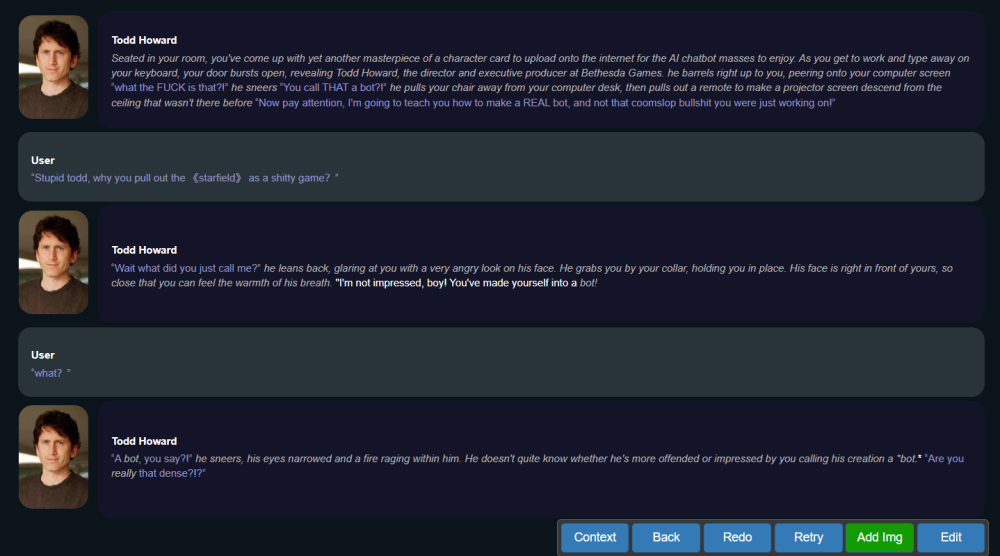
(圖源:雷科技)
聊不下去了?
點擊左下角的聊天工具,可以讓大模型根據你的前文自動生成答復來推進對話。

(圖源:雷科技)
回答錯了,或是對話走向不如人意?
點擊右下角的聊天工具,不僅可以讓你重復生成AI問答,甚至還能自己出手編輯回復以確保對話走向不跑偏。

當然,除了對話以外,Kobold Lite還有更多可能性。
你可以將它和AI語音、AI繪圖的端口連接在一起,這樣在對話的同時,可以自動調用AI語言爲生成的文本進行配音,也可以隨時調用AI繪圖來畫出當前二人交談的場景。
在此之上,你甚至可以使用更高階的SillyTarven前端,來實現GIF、HTML內容在對話中的植入。
當然這些,都是後話了。
總結
好,部署本地大模型的教程就到這了。
文章裏面提到的軟件和大模型,我都已經傳到百度網盤裏了,感興趣的讀者可以自取。
就我這大半年的體驗來看,目前本地大模型的特徵還是「可玩性強」。

只要你的配置足夠,你完全可以把大語言模型、AI語音、AI繪圖和2D數字人連接在一起,搭建起屬於自己的本地數字人,看着在屏幕中栩栩如生的AI角色,多少讓人有種《serial experiments lain》那樣的恍惚感。
不過這類开源大模型,通常數據都會比較滯後,因此在專業性知識上會有比較明顯的欠缺,實測大部分知識庫都是到2022年中旬爲止,也沒有任何調用外部網絡資源的辦法,輔助辦公、查閱資料時會遇到很大的局限性。
在我看來,理想的大語言模型體驗應該是端雲互動的。
即我可以在本地,利用自己的大模型建立自己的知識庫,但是需要用到時效性信息的時候,又能借助互聯網的力量獲取最新資訊,這樣既可以保護個人資料的隱私性,也算是有效解決了开源大模型信息滯後的問題。
至於本地角色交流這塊,如果大家感興趣的話……
要不,我把雷科技的角色卡給整出來?
來源:雷科技
原文標題 : AI大潮下,搭建本地大模型的成本在急速降低
標題:AI大潮下,搭建本地大模型的成本在急速降低
地址:https://www.utechfun.com/post/384496.html