
技術進化放緩引起的連鎖反應。
文丨賀乾明 王與桐 徐煜萌
編輯丨程曼祺
“Mayday” 可直譯爲 5 月天,它也是國際通用的無线電求助信號。當飛機有墜落危險時,飛行員會對着對講機大喊 “Mayday”!
這個 5 月,可能是 ChatGPT 發布至今大模型行業最熱鬧的時候:OpenAI、Google、微軟、字節跳動、阿裏巴巴等中美兩國公司至少舉辦了 13 場與大模型相關的發布會,介紹了 10 多款新模型,拿出了一堆新產品。
熱鬧中的風險與失望是:不少從業者認爲技術沒有重大進步。
OpenAI 本月新發布的 GPT-4o 處理語言的能力停留在 GPT-4 水平,被期待已久的 GPT-5 仍未登場。
多模態成爲頂尖 AI 公司的技術焦點:從 OpenAI、Google 到微軟,發布能同時處理語音、圖像,甚至理解現實世界的模型。但這些能力支持的產品和應用都還在 Demo 階段,沒正式發布就引出了侵權、隱私隱患等各種麻煩。
唱衰大模型創業機會的金沙江創投主管合夥人朱嘯虎有一個觀點:如果語言能力的進化速度變慢,“這波熱潮就到頭了”。
“沒什么令人興奮的。” 一位在中國大公司帶隊研發大模型的人士說,一系列發布會讓他更相信,开發能力更強的小模型才是未來。
一位 AI 創業者說 GPT-4o 不是顛覆性技術,“對 AGI 沒幫助”,但它基於一些頂級單點技術構建了組合式創新,“交互能力提升,能幫助普及應用”。
比技術競爭更吸引關注的是大模型價格战。OpenAI 和 Google 都在 5 月的發布會上宣布核心模型價格打 5 折。
在中國,量化交易公司幻方在 5 月初扣動降價扳機,拿出比行業水平低了超 90% 的模型;大模型獨角獸智譜 AI 快速跟進。之後的兩周,字節、阿裏、百度和騰訊等大公司也接連降價甚至免費。
一家中國大公司人士這個月在一個座談會上說:“如果這種降價變成了燒錢,變成了下一場社區买菜,不利於技術發展。” 他們自己也是降價的一員。
關於如何監管大模型的爭論也在這個月達到新高潮。
美國和歐洲政府都選擇更強的監管。美國國會开始考慮提出限制开源大模型出口的法案;歐盟在 5 月中旬正式批准起草 3 年的《歐盟人工智能法案》。
OpenAI 首席科學家伊利亞·蘇茨克維(Ilya Sutskever)和旨在確保 AI 安全的超級對齊團隊負責人揚·萊克(Jan Leike)等數名人員在 5 月離職。萊克在社交媒體上指責 OpenAI 不重視 AI 安全,他們團隊分得的資源嚴重不足:“我們迫切需要弄清楚如何控制比我們聰明得多的人工智能系統。”
圖靈獎得主楊立昆(Yann LeCun)針鋒相對地評論:在控制 AI 之前,“我們先要找到一點能設計比家貓更聰明的系統的跡象”。他認爲大模型遠不如一些人渲染的強大。
一批受限於資金壓力、技術進步和變現困難的大模型明星創業公司在 5 月集體尋求賣身,如致力於开發 AI Agent 的獨角獸 Adept,參與开發了文生圖开源模型 Stable Diffusion 的 Stability AI 和开發了 AI Pin 的硬件公司 Humane 等。
“高科技產品推廣過程中,最危險的時刻就是從早期市場過渡到主流市場的階段。” 美國組織理論家傑弗裏·摩爾(Geoffrey Moore)在《跨越鴻溝》一書中寫道,這個階段存在經常被人忽視的鴻溝。
最早使用新技術的群體的立場和需求並不能代表主流群體,甚至還會讓开發新產品的公司產生錯覺,認爲自己已經觸達了主流人群。摩爾認爲,只有成功跨越鴻溝,新技術才能創造財富,否則會一敗塗地。
大模型正在接近鴻溝邊緣。全球最知名的 AI 產品 ChatGPT 的日活已橫在數千萬多時。早期嘗鮮用戶後,所有公司都亟需跳上有海量大衆用戶的鴻溝彼岸。
熱鬧的 5 月,放緩的模型進展
相比 ChatGPT、GPT-4、Sora 發布時引發的全球震動,OpenAI 在 5 月 13 日推出的 GPT-4o 更像是給過去一年多大語言模型的性能狂飆點了一腳剎車。
據 OpenAI 公布的評測數據,他們投入數百人研發的 GPT-4o 相比之前的 GPT-4 Turbo ,文本處理能力提升不大:MMLU(本科生水平的知識)得分提升 2.5%、HumanEval(編程能力)提升 3.6%、MGSM(跨語言數學能力)提升 2.3%、DROP(文本段落分析推理)還下降了 3%。
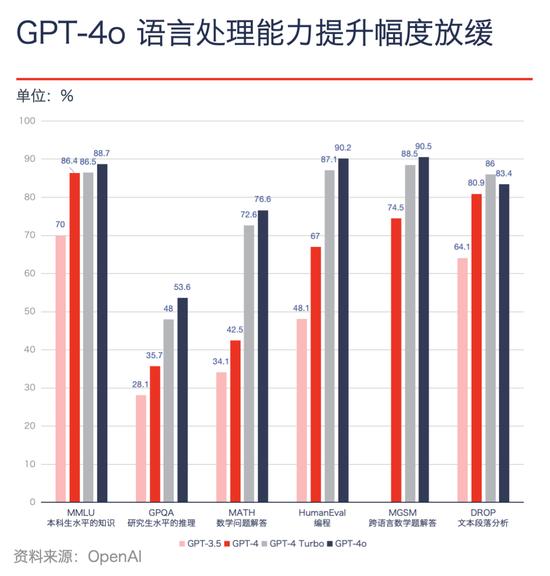
“這個趨勢大概率會延續下去。” 國內大模型獨角獸 MiniMax 的天使輪投資人、雲啓資本合夥人陳昱說,一個關鍵原因是能夠訓練大語言模型優質數據已接近耗盡。
GPT-4o 的提升主要在文本之外的語音、圖像等多模態功能上,其中最受關注的是語音能力,它用上了端到端架構——輸入端是語音,輸出端也是語音,不需要在中間用文本做轉換。
端到端的最大提升是把語音對話產品的回應時間從數秒減少到了數百毫秒,延時低得人耳無法察覺。它也能讓人在對話中隨時打斷機器人,而不是一輪輪地你問我答,這更符合人與人聊天時的習慣。
一位中國大模型獨角獸創始人說,OpenAI 最強的地方在於,就是它不見得是第一個發明某種技術的公司,但總能把優化做到最後,比如楊立昆領導的 META AI 實驗室幾年前就做出了語音端到端模型,但效果一直不如傳統的語音轉文字再轉語音,“OpenAI 在這個工程問題上解決得還挺驚豔的。” 他說。
另一位考慮开發端到端語音模型的創始人認爲,語音就是語言的外化,OpenAI 已經證明了這條路在技術和提升產品體驗上是可行的。
不過 OpenAI 尚未將端到端語音對話能力开放給用戶,他們稱 “還有一系列問題要解決”,語音和視頻功能要幾周後才會上线。
另一個可能被忽視的進步是 GPT-4o 的圖像生成能力。在能力評測數據集上,GPT-4o 的圖片理解能力得分相比 GPT-4 Turbo 和同行們的 Gemini Ultra、Claude Opus 有大幅提升。一些從業者認爲,部分指標幾乎相當於 GPT-3.5 到 GPT-4 的變化。
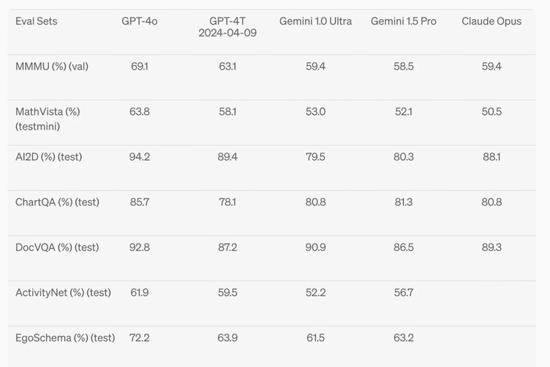
OpenAI 發布會沒有展現的一點是,GPT-4o 現在已可以生成圖片中的文字。之前,讓大模型生成出正常的文字,難度不亞於讓模型生成正常的人手,現在也沒幾個模型能做到。
Google 5 月 14 日的 I/O 大會甚至沒提太多大模型處理文本能力的新進展。能處理圖像、語音的模型 Project Astra 和 Gemini 1.5 Flash 成爲重點。
Astra 可以通過攝像頭識別現實環境、解讀代碼、做數學題,幾乎實時地與人語音交互。Gemini 1.5 Flash 則是一款規模更小的模型,Google 沒公布它的具體參數,只強調它可發揮不輸更大參數模型的能力:能高效處理文本、圖像和視頻數據。
6 天後的微軟 Build 大會上,OpenAI 不再像一年前那樣是唯一的大模型主角。除了介紹多個公司的大模型,微軟還發布了只有 42 億參數的自研模型 Phi-3-Vision。這也是一個能理解圖像的多模態模型。而且因爲參數足夠小,它可以用到移動設備中。
OpenAI、Google 和微軟發布會上展現出的技術趨勢,是當前大模型發展的縮影:文本處理能力進步放緩;處理語音、圖像的多模態能力成爲重點;开發參數更小但性能更強的模型。
它們服務同一個目標:用更低的成本、更豐富的功能,推動大模型進入更多商業場景,讓更多人高頻使用。
一年多過去,還在尋找殺手級應用
想要達到讓更多人高頻使用產品的鴻溝彼岸,只靠技術不夠。“AI 並不意味着可以輕松开發一個偉大的產品、公司或服務,只靠 AI 無法打破一些商業規則。” 沒在 OpenAI 發布會上亮相的OpenAI CEO 山姆·阿爾特曼(Sam Altman) 在微軟的發布會上說。
OpenAI 靠着更強的模型和先發優勢,去年賣會員帶來 10 多億美元收入,跟他們過去和未來需要的投入顯然不是一個量級。
據美國紅杉資本估算,大模型行業購买英偉達的 GPU 就投入了 500 億美元,收入只有 30 億美元。與過去的互聯網、移動互聯網、雲計算技術變革相比,大模型的商業化進展弱上幾分。蘋果推出 App Store 兩年後,Instagram 就出現了。
即使如此,微軟、Google、Meta 等公司今年仍打算花數百億美元买英偉達的 GPU,訓練更強的大模型,爲未來可能的大模型應用爆發做准備。
它們設想中的爆發方向包括語音助手、搜索引擎、操作系統等。這些產品在 5 月的發布會中頻繁亮相。
據市場消息,蘋果已與 OpenAI 籤訂協議,用 GPT-4o 的語音處理能力改進 Siri,將在下個月的 WWDC(蘋果全球开發者大會) 上宣布。一同被蘋果考慮的還有 Google、Anthropic 开發的模型。
除了手機,耳機也成爲硬件焦點之一。OpenAI 發布會之後,字節跳動被報道花 5000 萬美元收購了一家耳機公司,字節可能會把大模型與耳機做結合。
“GPT-4o 讓我們看到了語音交互效果提升後的情況。” 近期投資了另一家國內智能耳機創業公司的投資人說,當前市場上的 AI 硬件都不算成功,很大原因在於它們與手機的重復度太高,“它們能做的,手機上也可以,但大多數人都需要一個單獨的耳機。”
微軟設想的一個殺手級產品是植根於 Windows 11 操作系統中的 Recall 功能。它可以 “記住” 用戶過去 3 個月內在設備上用過什么程序、處理過什么內容。用戶只需要一句話就可以搜出自己處理過的信息。
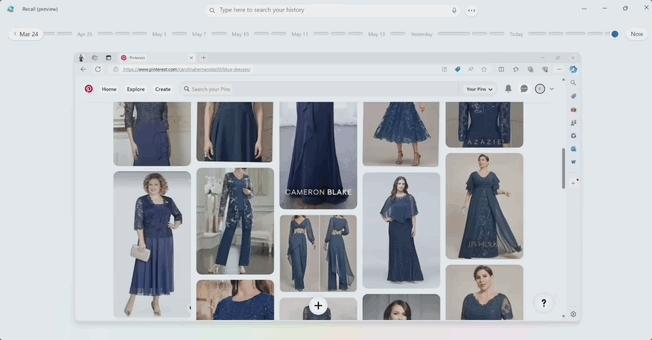
在上方文本框輸入 “blue dress ” 後,Recall 功能可以搜出來用戶在電腦上看過和輸入過的相關信息。圖片來自微軟。
Google 也終於把大模型與搜索引擎結合起來,推出了一個叫 AI Overviews 的功能。用戶搜索時,大模型會拆解問題,再去搜索各種網頁,自動生成能用的答案,並附上鏈接。
不過這些產品在證明有拓展大衆用戶的潛力前,都遇到了一些風波。
OpenAI 的 4o 語音功能因使用了一款與科幻電影《她》(Her)的配音者、演員斯嘉麗·約翰遜非常相似的聲音,被她本人抗議。這款聲音已下架。
微軟的 Recall 功能則需要每隔幾秒自動截屏一次,以記錄設備上進行的各個操作。這種經常被一些互聯網公司用來監控員工的手段,現在成了使用新鮮大模型功能的前提。盡管微軟強調數據會被加密存在設備上,但還是引起了隱私風波。
Google 的 AI Overviews 更是會輸出匪夷所思的結果:建議苦惱披薩上的奶酪總是掉下來的用戶在披薩上塗膠水;告訴用戶過去 20 年美元的通脹率是-43.49%(實際爲 77%);人眼可以直視太陽 15 分鐘。
至於 OpenAI 的 GPT-4o 和 Google Astra 虛擬助手展現的大模型理解圖片、視頻和現實世界的能力,則還需要找到具體產品形態和應用場景。一位中國大模型獨角獸公司創始人說 “如果模型只是看到三個人在喝咖啡,沒有什么商業價值。如果沒有應用,模型又怎么持續優化?” 把多模態模型用到機器人身上(具身智能)可能是一個有價值的方向,但想要做好太難。
“跨越鴻溝的基本原則,是找准一個具體的細分市場作爲攻擊點,集中所有資源全力進攻,以最快的速度拿下領導地位。” 傑弗裏·摩爾在《跨越鴻溝》一書中寫道。現在大模型公司都還在尋找:這個准確的攻擊點到底在哪兒?
降價不只來自技術優化,也來自敢虧錢
價格战是 5 月的另一個 AI 主題。
發布 GPT-4o 時,OpenAI 宣布調用 GPT-4o 模型 API (編程接口)的價格比 GPT-4 Turbo 下降一半,處理 100 萬 Token 的輸入只用 5 美元。Google 也跟着把其主力模型 Gemini 1.5 Pro 的調用價格調低了一半,處理 100 萬 Token 只要 3.5 美元。
但與中國大模型公司動輒降價超 90% 的激烈競爭相比,它們只打五折的降價幅度還是太小。
5 月 7 日,量化交易公司幻方發布對標 GPT-4 的模型 DeepSeek-V2,API 價格只有 GPT-4 Turbo 的近百分之一:處理 100 萬 Tokens 輸入 1 元人民幣,輸入 2 元(32K 上下文)。
5 月 11 日,國內大模型創業第一梯隊的智譜 AI 也降價 80%,入門級產品 GLM-3 Turbo 模型調用價格從 5 元/百萬 Tokens 降到 1 元/百萬 Tokens。
5 月 15 日,字節的豆包大模型對外提供服務,並將處理輸入文本的價格定在 0.8 元 / 百萬 Tokens,也就是處理 1500 多個漢字只要 8 釐錢,宣稱比行業水平便宜了 99.3%。
一周後的 5 月 21 日,阿裏更進一步,把對標 GPT-4 的 Qwen-Long API 輸入價格降到 0.5 元 / 百萬 Tokens。
當天下午,百度宣布主力模型文心一言 ERNIE Speed 和 Lite 模型宣布免費。
第二天,騰訊宣布輕量大模型 “混元-lite” 免費,最高配置的萬億參數模型 “混元-pro” 降至 300 元 / 百萬 Tokens,降幅 70%。
一些公司是降低最高端模型的價格:如阿裏、字節跳動和幻方;百度、騰訊和智譜則主要在更輕量、更小的模型上降價或免費。
低價和免費也有一定限制條件。企業或开發者真正調用模型开發產品時,想提高調用大模型處理文本的頻率或者處理更多文本時,還要多花錢。
阿裏通義大模型降價的那個上午,我們正在採訪使用阿裏通義大模型做兒童繪本的創業公司童語故事。被問及豆包降價後是否會考慮切換,童語創始人張華說:“如果只考慮降價,那么阿裏肯定也會降,所以不用換。”
不到一小時後,交談還未結束,張華的手機上就彈出了一條新聞:阿裏通義也降價了。
降價部分來自技術優化。字節跳動旗下火山引擎總裁譚待在 5 月發布模型和宣布降價的發布會上說,他們有多個降價技巧,如調整模型架構、把在單個設備上做推理改成在多個設備上分布式推理,集中處理模型調用任務,提升芯片的利用率。
整個大模型行業的降本共識還有:用更多優質數據訓練參數規模小的模型,參數少推理成本就低;訓練 MoE 架構的大模型,處理文本時不用所有參數都運行一遍,節省算力。
芯片也在降價中扮演重要角色。英偉達年初宣稱,靠着改進推理框架等方法,一年時就把大模型推理成本減少到了原本的四分之一。今年 3 月,英偉達發布新產品 GB200 ,宣稱它能把大模型推理性能再提高 30 倍。
中國大公司的降價預計還會持續。它們同時做雲計算和大模型,降價的商業合理性是可以用模型當引子賣雲服務,比如存儲、數據庫等。
一位雲計算廠商人士說,相比降價,GPU 空置才是雲廠商更大的成本:“一套 8 塊的英偉達高端 GPU 服務器,現在一個月租金要大幾萬,如果卡买得多,租不出去、空置才是虧錢。”
他推測阿裏通義降價後仍有利潤:“現在訓練模型的需求變少了,空出來的高端 GPU 也可以去做推理,理論上綜合成本都一樣,因爲資源已經虛擬化了。” 中國體量最大、機房最多阿裏雲有成本優勢。另一位阿裏雲人士也表示,阿裏雲大模型降價後並不虧錢;降價也不是應對價格战,是既定战略。
創業公司則持觀望態度。百川智能創始人王小川在 5 月下旬的一場媒體溝通會上多次被問及怎么看大公司的大模型價格战。“你們去問他們,我們有自己的節奏。” 王小川說,百川不會加入價格战,他認爲降價的雲廠商賣的不是模型本身,是背後的整套雲服務,和大模型創業公司邏輯不同。
零一萬物創始人李开復也在 5 月下旬的分享會上說不加入價格战:“如果中國市場就是這么卷,大家寧可賠光、通輸也不讓你贏,那我們就走國外市場。”
雲啓資本陳昱對比了過去的打車和 O2O 大战,當時創業公司激進價格战的邏輯是把對手燒死,最後獲得壟斷。但大模型不需要繁重的地推掃街,大公司下場容易。
“創業公司能燒的錢有限,就算融了 10 億美元,大公司單個季度的利潤都比這多多了。” 他認爲價格战打到最後還是大公司贏,“除非創業公司另闢蹊徑,走與大公司不同的產品和商業化路线。”
再小的模型都需要推理成本。現在百度、騰訊等公司對部分模型已經走到了免費這步,字節也給出了超出一般降本速度的降價幅度。這把 to B 賣大模型 API 的競爭也帶向了前期虧損換用戶的 to C 產品競爭。
錢不夠了,一批大模型公司尋求退場
新模型、新產品密集發布,價格战你追我趕之時,一批明星 AI 創業公司正在退場。
今年 5 月,Transformer 作者之一參與創辦的 Adept 被報道考慮出售,已接觸了 Meta;參與开發开源文生圖模型 Stable Diffusion 的公司 Stability AI 去年就在尋求出售,現在仍在與不同买家接觸;大模型开發商 Reka 正在以 10 億美元估值尋求被收購;AI Pin 背後的 Humane 也正以 7.5 到 10 億美元的價格尋找买家。
在中國,一些立志追趕 OpenAI 的大模型公司已許久沒有拿到新融資了。還有一些公司迅速調整方向,比如面壁智能現在研發能用在手機等終端上的小語言模型,今年 4 月完成了由華爲旗下哈波基金領投的一輪數億元新融資。
到今年 5 月,中國頭部大模型公司的單輪融資額已經達到數億美元,能拿到新融資的公司越來越少;能接得住大模型公司後續融資的投資方也越來越集中於大型互聯網科技公司。
一位小型投資機構的投資人說:我們這樣管着十億元規模的公司已經沒有投模型層的機會了。在某次見大模型創業公司時,他提出想要一些額度,對方沒給:“我反而松了一口氣,因爲我知道我們投不起。”
大模型應用層仍有新公司和新交易。美國紅杉資本合夥人索尼婭·黃(Sonya Huang)認爲,當前還沒有哪個大模型應用的用戶留存達到流行的移動應用水平,仍對於大模型應用創業者來說,窗口期仍在。
據了解,去年曾被認爲將被大語言模型取代的祕塔,在今年 3 月推出祕塔搜索並取得了超 500% 的用戶增長後,多個互聯網大公司向它拋來投資橄欖枝。曾做出妙鴨相機的張月光,在新創業方向尚未明朗時,就已獲得了近 3 億元人民幣的融資。
模型層的價格战客觀上減少了部分基於大模型做應用的新玩家的試錯成本。整個 5 月,快手、網易、字節跳動接連有 AI 產品或技術負責人離職、投身創業。如網易副總裁及研究院院長汪源在社交媒體公开宣布:會回到 To C 市場,招募有海外 AI 或生產力工具類軟件的產品、運營、算法和應用开發人才。
應用公司獲得初始融資的門檻不如大模型公司高,但競爭難度不小於資源集中的模型層。
“出來得太晚了。”一位投資人評價 5 月密集的創業新動向:“更重要的是,他們能有什么新想法呢?現在硅谷普遍的反饋就是,受限於大模型能力進展,這半年沒有新東西出來。”市場上仍能看到早期投融資交易的原因是:“第一輪的錢好拿,大家缺資產,總想賭一下。但後面就得看產品數據了。”
全球範圍內對 AI 的投正在下降。安永(愛爾蘭)在 5 月中旬預測,今年全球風投投資生成人工智能的金額將達到 120 億美元,在已經過去的一季度,這個數字是 30 億美元。而 2023 年全年的總投資額是 213 億美元。
那些正尋求出售的大模型公司,現在更難找到合適的买家。去年市場上還有 Datebricks 以 13 億美元收購 MosaicML。而新近尋求收購的一批 AI 公司的潛在买家往往都已建立了自己的 AI 團隊,或此前已收購了一些公司。
如 Reka 的潛在买家之一是它的投資人 Snowflakes,據 The Information 報道,接近 Snowflake 的人士透露,Reka 和 Snowflake 間的收購談判已破裂;接近 Meta 的人士也稱,Meta 不太可能收購 Adept。
入場要抓住時機,退場也是。
還未繁榮就被監管,怎么防範大模型的爭吵仍在繼續
圍繞現在的 AI 是否已強大到要被關進籠子的爭論也在這個月進一步發酵。
5 月 20 日,25 位科學家在《科學》(Science)的政策欄目上發布題爲《在人工智能飛速發展進程中管理極端風險》(Managing extreme AI risks amid rapid progress)的文章,署名作者包括約書亞·本吉奧(Yoshua Bengio)、傑弗裏·辛頓(Geoffrey Hinton) 和姚期智(Andrew Yao)三位圖靈獎得主。
這些科學家認爲 “毫無准備的代價遠遠大於過早准備的代價”,呼籲各國政府更有力地規範 AI,並警告 “近六個月所取得的進展還不夠”。
另一位圖靈獎得主、Meta AI 首席科學家楊立昆覺得這種想法可笑。兩派觀點的核心分歧是,AI 到底有多強?
寫聯名信的科學家看到,AI 已經在玩策略遊戲和預測蛋白質結構上超過了人類,它還能復制數百萬個自己:“在這個十年或下個十年內,將开發出在許多關鍵領域超越人類能力的高度強大的 AGI 系統。那時會發生什么?”
楊立昆則認爲家貓都比現在最優秀的大模型聰明,大模型並不能真正理解邏輯和做因果推理,現在就急迫地討論 AI 的安全性,就好像有人在 1925 年說:“我們迫切需要弄清楚如何控制能夠以接近音速運送數百名乘客的飛機。”
人工智能科學家李飛飛和斯坦福人工智能研究所的聯合主任約翰·艾克曼迪(John Etchemendy)也在 5 月下旬於《時代》雜志發表文章稱,大模型 “只是在概率性地完成任務而已”。
政府寧可未雨綢繆。2021 年 4 月,歐盟委員會就提出人工智能法案草案,以 “風險爲本”(risk-based approach)、從政府層面規制 “人工智能的應用邊界” —— 盡管他們尚不知道邊界在哪。
該草案提出兩年內都沒有太大進展。直到去年 ChatGPT 席卷全球,該草案增加了大模型監管內容,並於去年被正式投票通過。
今年 5 月,歐盟理事會正式批准該法案生效。法案要求在歐盟提供服務的大模型公司披露訓練模型時用了哪些有版權的數據、哪些內容是人工智能生成的,還要防止模型生成有害內容。
去年通過關於人工智能的監管法令的美國政府,在這個月又在推進一項新法案。與之前強調規避大模型 “國家安全、國家經濟安全等構成嚴重風險” 不同,新法案作爲 2018 年《出口管制改革法案》的修訂版,核心目標是方便限制开源模型出口:“保護美國人工智能及其他支持技術免受外國對手的利用。”
該法案 5 月 23 日通過了衆議院外交事務委員會的投票,後續立法流程還有:衆議院、參議院投票和總統籤署。
如果說各國政府對互聯網的監管和反壟斷是後知後覺,對 AI 的提防則來得早得多。這是一個還未進入商業應用大繁榮就被監管的行業。
OpenAI、Google、Anthropic 在內的大模型領先者和大公司傾向推動監管。過去一年,多封強調大模型風險的公开信中都有這幾家公司高層的名字。更嚴格的監管有利於領先者,不利於資源有限的中小公司和非主流方向的探索與創新。
不過相比公司間的競爭,現在整個大模型領域更需要新的技術 “興奮劑”,要么更快地褪去黑科技光環,开始落地、賺錢。
去年 5 月,借着 GPT-4 剛剛發布引發的關注,山姆·阿爾特曼开啓全球旅行,與多國家與政要交流怎么監管大模型。
一年過去,OpenAI 安全團隊負責人離开了。阿爾特曼也不再怎么談論大模型的風險,參加各種活動講的最多的就是:更強大的 GPT-5 就要來了。
題圖來源:pixabay
· FIN ·
標題:大模型的 5 月:熱鬧的 30 天和鴻溝邊緣
地址:https://www.utechfun.com/post/377858.html