生成式人工智能革命已經來臨
⼈⼯智能在各⾏各業的蓬勃發展推動了35%以上的市場增⻓,預計⾄2032年,僅⽣成式⼈⼯智能⼀項的市場規模就將達到1.3萬億美元。 (Precedent Research, 2023)
先進的人工智能要求重新考量數據中心的設計
加速生成式人工智能和機器學習模型由訓練型(學習新能力)和推理型(將能力應用於新數據)組成。這些深度學習和神經網絡模仿人腦的架構和功能,在分析大量復雜數據集的模式、細微差別和特徵的基礎上,學習和生成新的原創內容。大型語言模型(LLM),如ChatGPT和Google Bard,就是這些生成式人工智能模型的例子,這些模型在海量數據的基礎上進行訓練,以理解和生成合理的語言反應。
按順序執行控制和輸入/輸出操作的通用CPU無法有效地從多種來源並行提取大量數據並進行快速處理。因此,加速機器學習和生成式人工智能模型依賴於圖形處理單元(GPU),後者使用加速並行處理來同時執行數千次高吞吐量計算。單個基於GPU的服務器的計算能力可媲美數十個基於CPU的傳統服務器的性能!
獨特的機器學習和生成式人工智能特性
⾮常⾼的帶寬 – 服務器端100G、200G、400G,甚至是800G的速率,交換機至交換機連接快速遷移至800G和1.6T速率。
超低延遲 – 實時(< 20 毫秒)節點間東西向數據傳輸。
功耗⼤幅增加 – 基於GPU的服務器需要10倍以上的電力,導致機櫃功率密度達到30-100kW甚至更高。
先進的冷卻技術 – 數據中心正在評估更高效的冷卻方法,如芯片級液冷和浸入式液冷,以處理服務器產生的高熱量。
InfiniBand和以太⽹協議 – InfiniBand的高吞吐量和低延遲性能在後端的GPU間連接中佔主導地位,而以太網的兼容性、安全性和管理功能則是前端接口的理想選擇。以太網的不斷進步將使二者在後端並存。
⾼密度、⾼性能的布线系統 – 節點之間、以及用於存儲、管理和交換的高速連接需要更多的高帶寬布线。
人工智能網絡向高速遷移(後端)
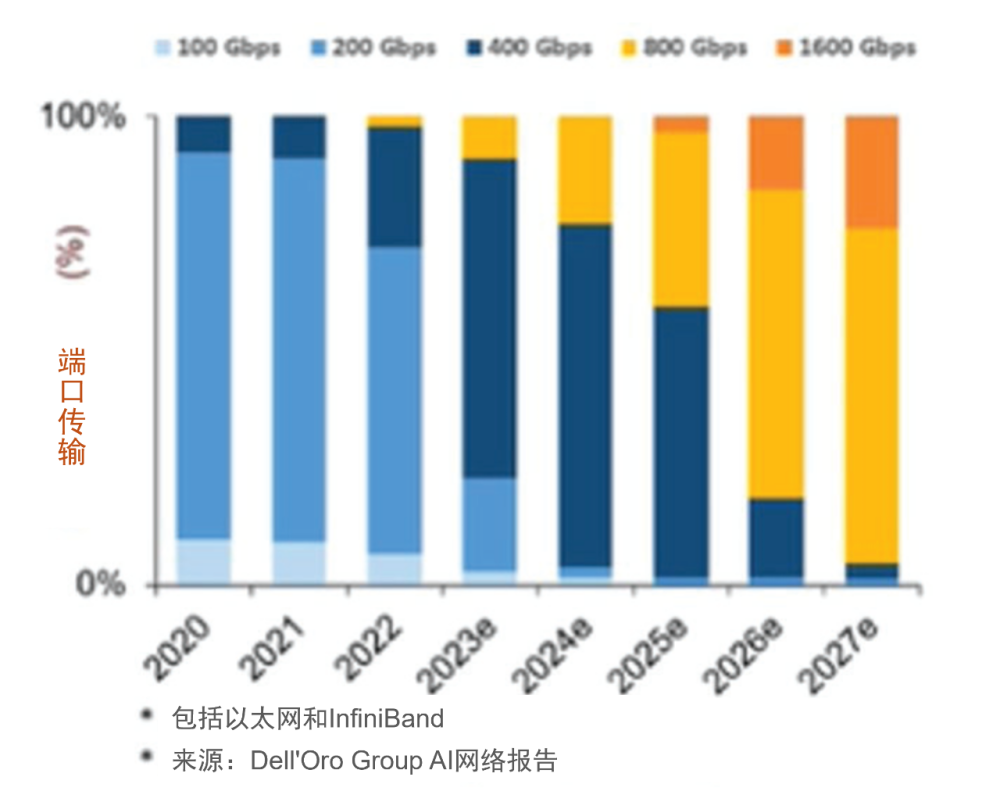
初步預測(2023-2027)
InfiniBand和以太網將共存。 到2027年,幾乎所有端口將達到800G及以上的速率。 網絡帶寬達到三位數的復合年增長率。
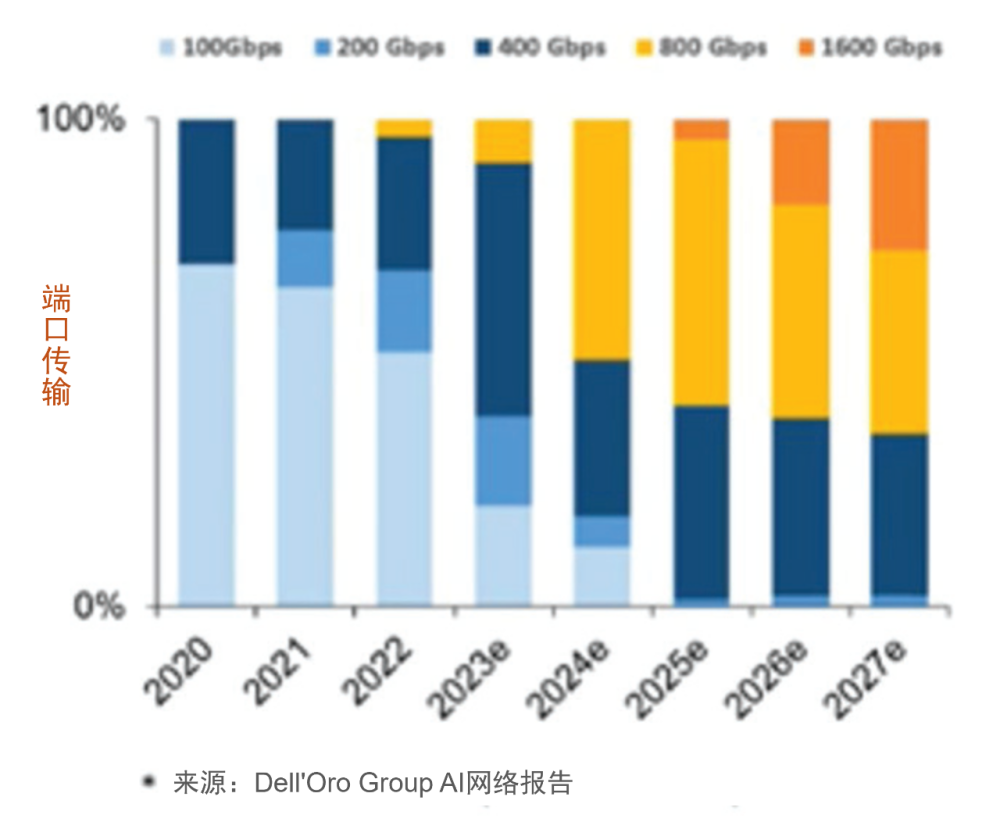
所有端口爲以太網。 到2027年,幾乎2/3的端口將達到800G及以上速率。

• 高密度、端到端的LightVerse單模和多模MTP光纖系統,可爲後端、前端和存儲架構提供高達800G及以上的高性能超低損耗(ULL)傳輸。

• 全面的直接銅纜(DAC)和有源光纜(AOC)系列,用於以太網、RoCE和InfiniBand網絡人工智能集群內的後端點對點高速、低延遲連接。
• 能夠在ToR和EoR/MoR配置中同時支持InfiniBand和以太網協議。
• 憑借專業知識和經驗,幫助企業設計和部署優化的人工智能InfiniBand和以太網銅纜和光纖基礎設施,以滿足計算、存儲、帶外和帶內管理等所有網絡的需求。
• 數據中心服務,根據具體用例、預算、現有基礎設施和未來需求來提供基礎設施設計建議。
兩大數據中心巨頭強強聯手


西蒙數據中心設計服務
無論您是受托爲多個客戶提供IT服務並履行SLA(服務水平協議)的服務提供商,還是投資人工智能和高性能計算(HPC)網絡以加速業務發展的企業,數據中心的底層網絡基礎設施都是您發展壯大的不二法寶。
數據中心的布线基礎設施是滿足內部和外部客戶對頂級人工智能網絡和高性能計算可用性和性能期望的核心。您的團隊還需要無憂的正常運行時間、可靠性和可擴展性保證,這樣他們才可以專注於取得成功的必要條件。
我們如何幫助您?
我們將數據中心的專業知識集中到全球服務網絡中,旨在指導您選擇和設計所需的底層物理基礎設施,以確保您的數據中心爲人工智能做好准備,同時爲您提供所需的持續支持,以快速響應不斷變化的需求、防止宕機並保持最高性能。
數據中心布线合規檢查服務
數據中心設計服務
技術服務團隊
業界領先的合作夥伴提供支持
多年來,我們建立了一個由數據中心合作夥伴組成的體系,他們都是各自領域的專家。西蒙以與全球人工智能和高性能計算領導者合作爲榮,他們提供的互補性產品和服務與我們一流的IT基礎設施解決方案相結合,爲我們的客戶提供額外的價值和支持。


對超低損耗連接的需求
後端和前端人工智能網絡中的InfiniBand和以太網鏈路利用了經濟高效的多模和短距單模光收發器技術的帶寬能力。對於高速結構化布线鏈路,多模光纖可支持200G和400G至50米,而短距單模光纖可支持更長的500米和2000米距離。對於以太網部署,多模(SR和VR)和短距離單模應用(DR和FR)有嚴格的插入損耗要求,多模的最大信道損耗爲1.9 dB,DR單模爲3dB,FR單模爲4dB。
對於人工智能網絡內的結構化布线,超低損耗(ULL) MPO/MTP連接可確保最大信道長度,同時確保留有余量以適應安裝變量,並提供支持便捷跳接的靈活性,從而有助於提高可管理性、可擴展性和部署速度。在選擇連接時,不同供應商的損耗值可能會有所不同,許多供應商提供標准損耗、低損耗和超低損耗連接。由於存在差異,因此必須確保第三方驗證的最大插入損耗值能夠真實反映性能。
西蒙的ULL LightVerse® MTP多模和單模布线系統已通過第三方驗證,可提供相當大的插入損耗余量,從而提高人工智能網絡的性能,傳輸速度可達100G、200G、400G和800G。

對多模和單模APC連接的需求
除了嚴格的插入損耗要求外,高速400G和800G應用以及未來的1.6T應用由於信噪比(SNR)較高,更容易受到反射率的影響。短距離DR和FR單模應用尤其容易受到影響,因此行業標准規定了基於信道中光纖耦合數量的反射率(回波損耗)值。
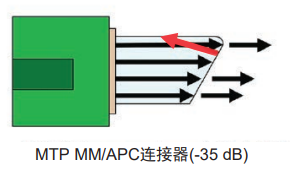
反射性能差會對信道插入損耗和傳輸性能產生不利影響。因此,除了用於高速AI鏈路的傳統單模MTP連接外,許多雲數據中心還指定使用多模斜面物理接觸(APC)連接器。與採用圓形光纖端面的超物理接觸(UPC)連接器不同,APC連接器採用8度角研磨,以減少反射信號量。多模MTP/UPC連接器的反射值通常爲-20dB,而多模MTP/APC連接器的反射值提高到-35dB。

人工智能應用的布线解決方案





西蒙的優勢
西蒙成立於1903年,在爲全球客戶制造和創新高質量、高性能數據中心解決方案方面是值得信賴的行業領導者。西蒙高級數據中心解決方案從底層开始設計,以滿足當前和未來人工智能和高性能計算環境的苛刻需求。我們對數據中心需求的深刻理解推動了我們應對最新人工智能革命的战略轉移。所有這些都以西蒙行業領先的質量、性能和可靠性爲後盾,幫助您降低風險,最大限度地延長正常運行時間,並成功交付新的人工智能應用和服務。
西蒙已經成功地爲其他幾家公司設計並部署了HDR 200G和NDR 400G InfiniBand算力系統。 西蒙對行業領先的硬件廠商的參考架構設計有深刻理解,能爲特殊用例場景提供布线設計建議。 西蒙針對AI低延遲需求有獨特的解決方案,簡化部署,並提供初始安裝後的靈活性。 西蒙可以支持所有的通用網絡:算力、存儲、帶外管理和帶內管理。 不斷優化提升的產品线以滿足不斷變化的數據中心需求,得益於持續改進、大量研發投入和對行業標准的領先參與的企業文化。 全球銷售覆蓋和完善的數據中心合作夥伴體系,以一系列領先的產品和服務爲客戶帶來增值方案。 我們廣泛的解決方案涵蓋了InfiniBand和以太網光纖、銅纜、DAC和AOC,支持端到端安裝。
雖然高性能計算集群中的長距離鏈路得益於結構化布线,但GPU的短距離低延遲連接通常依賴於DAC等點對點解決方案。但是,鋪展GPU和機櫃的人工智能集群已經超出了DAC的長度極限。AOC和單根光纜可提供長達100米的機櫃到機櫃連接,但在大型集群中管理成百上千根光纜就成了一件麻煩事。使用結構化布线的一些好處如下:
增加靈活性: 使用配线架和光跳线來連接任意兩個GPU, 更容易適應你不斷變化的AI需求。
密集交換機連接: 無縫管理高密度leaf至spine交換機連接的线路優化設計。
保護關鍵設備: 在移動、增補和變更操作中避免觸及重要的、昂貴的設備端口。
經濟⾼效且可擴展: 簡化日後的運維工作,可擴展至更高速率而無需重新布线,節約時間和費用。
易於查障排錯: 配线架上的標准化標籤和文檔可簡化故障排除工作,減少宕機時間。
改善⽓流和空間: 減少线纜擁塞,改善氣流,方便設備訪問。
認證的性能: 符合行業標准的系統保證布线性能。
與領先協會共同开拓人工智能
西蒙是很多塑造人工智能未來的領導組織的活躍成員。

“西蒙與InfiniBand的合作加強了我們在全球推進網絡基礎設施解決方案的承諾。我們認識到InfiniBand在滿足人工智能和加速卡不斷升級的需求方面發揮着關鍵作用。西蒙致力於提供創新的布线和連接解決方案,以促進該技術的發展和應用。”
– Gary Bernstein | 西蒙全球數據中心高級銷售總監

“以太網聯盟長期以來一直致力於通過行業標准和多廠商互操作性來支持以太網的發展。這與西蒙長期參與行業標准制定並致力於提供基於標准的優質解決方案的理念不謀而合。”
– John Siemon | 西蒙公司首席技術官

“IEEE802.3工作組負責制定以太網網絡標准。西蒙積極參與所有重要工作組的工作,爲衆多人工智能網絡制定200、400、800G和1.6T標准。”
– Dave Valentukonis | 西蒙公司北美技術服務經理
標題:生成式人工智能解決方案指南——超越新興人工智能網絡的要求
地址:https://www.utechfun.com/post/351020.html