來源:財聯社
財聯社2月16日電,OpenAI公布了一種新的人工智能系統,該系統可以根據用戶的文本提示創建逼真的視頻,使其成爲最新一家採用生成視頻技術的人工智能公司。該公司周四在一篇博客文章中表示,這款名爲Sora的人工智能系統可以快速制作長達一分鐘的視頻,這些視頻可以呈現“具有多個角色、特定類型的動作、以及主題和背景的准確細節的復雜場景”。
相關新聞
效果炸裂!OpenAI首個視頻生成模型發布,1分鐘流暢高清,網友:整個行業RIP(量子位)
奧特曼發布OpenAI首個視頻生成模型Sora。
完美繼承DALL·E 3的畫質和遵循指令能力,能生成長達1分鐘的高清視頻。
AI想象中的龍年春節,紅旗招展人山人海。
有緊跟舞龍隊伍擡頭好奇觀望的兒童,還有不少人掏出手機邊跟邊拍,海量人物角色各有各的行爲。

雨後東京街頭,潮溼地面反射霓虹燈光影效果堪比RTX ON。

行駛中的列車窗外偶遇遮擋,車內人物倒影短暫出現非常驚豔。

也可以來一段好萊塢大片質感的電影預告片:

豎屏超近景視角下,這只蜥蜴細節拉滿:

網友直呼game over,工作要丟了:

甚至有人已經开始“悼念”一整個行業:
AI理解運動中的物理世界
OpenAI表示,正在教AI理解和模擬運動中的物理世界,目標是訓練模型來幫助人們解決需要現實世界交互的問題
根據文本提示生成視頻,僅僅是整個計劃其中的一步。

目前Sora已經能生成具有多個角色、包含特定運動的復雜場景,不僅能理解用戶在提示中提出的要求,還了解這些物體在物理世界中的存在方式。
比如一大群紙飛機在樹林中飛過,Sora知道碰撞後會發生什么,並表現其中的光影變化。
一群紙飛機在茂密的叢林中翩翩起舞,在樹林中穿梭,就像候鳥一樣。
Sora還可以在單個視頻中創建多個鏡頭,並依靠對語言的深入理解准確地解釋提示詞,保留角色和視覺風格。
美麗、白雪皚皚的東京熙熙攘攘。鏡頭穿過熙熙攘攘的城市街道,跟隨幾個人享受美麗的雪天並在附近的攤位購物。絢麗的櫻花花瓣隨着雪花隨風飄揚。
對於Sora當前存在的弱點,OpenAI也不避諱,指出它可能難以准確模擬復雜場景的物理原理,並且可能無法理解因果關系。
例如“五只灰狼幼崽在一條偏僻的碎石路上互相嬉戲、追逐”,狼的數量會變化,一些憑空出現或消失。

該模型還可能混淆提示的空間細節,例如混淆左右,並且可能難以精確描述隨着時間推移發生的事件,例如遵循特定的相機軌跡。
如提示詞“籃球穿過籃筐然後爆炸”中,籃球沒有正確被籃筐阻擋。

技術方面,目前OpenAI透露的不多,簡單介紹如下:
Sora是一種擴散模型,從噪聲开始,能夠一次生成整個視頻或擴展視頻的長度,
關鍵之處在於一次生成多幀的預測,確保畫面主體即使暫時離开視野也能保持不變。
與GPT模型類似,Sora使用了Transformer架構,有很強的擴展性。
在數據方面,OpenAI將視頻和圖像表示爲patch,類似於GPT中的token。
通過這種統一的數據表示方式,可以在比以前更廣泛的視覺數據上訓練模型,涵蓋不同的持續時間、分辨率和縱橫比。
Sora建立在過去對DALL·E和GPT模型的研究之上。它使用DALL·E 3的重述提示詞技術,爲視覺訓練數據生成高度描述性的標注,因此能夠更忠實地遵循用戶的文本指令。
除了能夠僅根據文本指令生成視頻之外,該模型還能夠獲取現有的靜態圖像並從中生成視頻,准確地讓圖像內容動起來並關注小細節。
該模型還可以獲取現有視頻並對其進行擴展或填充缺失的幀,請參閱技術論文了解更多信息(晚些時候發布)。
Sora 是能夠理解和模擬現實世界的模型的基礎,OpenAI相信這一功能將成爲實現AGI的重要裏程碑。
奧特曼在线接單
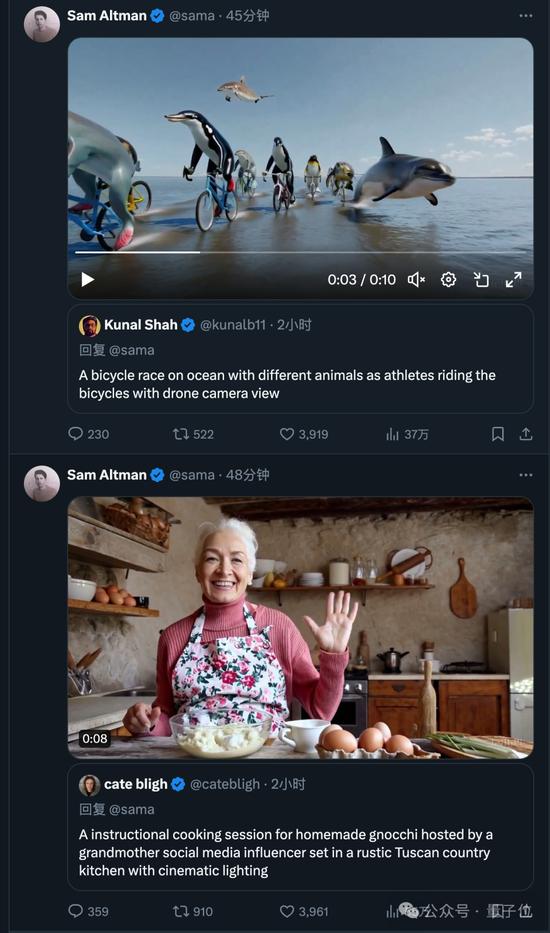
目前已有一些視覺藝術家、設計師和電影制作人(以及OpenAI員工)獲得了Sora訪問權限。
他們开始不斷po出新的作品,奧特曼也开始了在线接單模式。
帶上你的提示詞@sama,就有可能收到生成好的視頻回復。
責任編輯:劉鵬林
標題:OpenAI推出AI系統 將文本轉換爲逼真的視頻
地址:https://www.utechfun.com/post/332692.html