高質量的語料數據 ,是大模型的“香餑餑”。
眼看着2023就要過去了,沒想到年底又曝出一個大瓜。
近期據《The Verge》報道:
字節跳動因使用ChatGPT的API,來开發自家大模型,被OpenAI“封號”了。

盡管在事後,字節澄清,表示自己此舉“僅爲測試”,且早已勒令停止。
然而,這終歸是一件讓人浮想聯翩的事……
字節被封號的背後,打的究竟是什么算盤?
01 字節想要什么?
雖然在《The Verge》報道中,沒有明確指出字節究竟是怎么用OpenAI的API來开發自身大模型的,但可能的訓練路徑來說,用一個大模型(例如OpenAI的GPT)來訓練另一個大模型的過程,往往有以下幾種。
其中一種,就是“師傅帶徒弟”的模式。
想象一下,師傅(已有的大模型)在處理各種任務時,會生成一些輸出(例如文本、圖像等)。徒弟(新的大模型)會觀察師傅的行爲,嘗試模仿這些輸出。
這樣,徒弟就能學會如何處理類似的任務。在實際應用中,這可以通過讓新模型學習舊模型生成的數據來實現。

還有一種方式,就是通過聯合訓練,讓“師傅”和“徒弟”一起處理任務。
在實際應用中,這可以通過讓兩個模型共享一些層次或參數來實現,新舊模型就可以互相學習、互相幫助,共同完成任務。
從技術可行性來判斷,在這次事件中,字節使用的更有可能是第一種方法。
即利用了OpenAI API生成的數據作爲訓練數據。
因此,在這次風波中,字節真正想要的,是ChatGPT生成的高質量語料數據。
而這樣的數據,也是任何一個訓練中的大模型,最渴望的“香餑餑”。
但由於之前OpenAI的協議中,已明確表示禁止用其大模型去开發競品,因此,字節被OpenAI“封號”也是一種必然。

問題是:作爲一家實力雄厚的大廠,字節理應不缺相應的人手和資金,去做這些數據爬取、語料標注方面的工作,爲何要走這一步“險棋”呢?
02 爲何犯險?
其實,在現階段的大模型賽道上,字節缺的不是人才和資金,而是時間。
與百度、訊飛等國內大廠相比,字節真正入局大模型的時間,可以說是相當晚了。
從時間上看,字節真正推出第一款大模型豆包的時間,是今年的8月中旬,而那時,大模型之火已經燃燒了近半年之久。
任何真正想入局大模型的玩家都知道,模型層的競爭,是有時間窗口的。
在大模型領域,先進入市場的企業往往能夠積累更多的用戶、數據和經驗,從而形成競爭優勢。後來者要想迎頭趕上,需要付出更多的努力和成本。
盡管8月上线的豆包,讓字節勉強趕上了模型層的晚班車,但從性能和定位上看,那更像是一個“嘗鮮”的應景之作,無法真正與字節現有的業務相契合。
作爲一個在移動互聯網時代制造了抖音這類爆款的大廠,字節真正想要的,是像文心一言那樣更通用、更全能,且能整合或嵌入進自身的各類APP中的大模型。

這才有了後來字節的“種子計劃”——計劃在今年年底前,打造與 GPT-3.5 性能相匹敵的Seed 大模型。
問題是,大模型的訓練,終歸不是件一蹴而就的事。
標注數據、提取優質語料等等一系列繁瑣的前期工作,都需要時間。
那如何在有限的、緊迫的時間內,搜集到足夠多的高質量語料數據?
一個最靠譜的辦法,就是直接使用那些已經驗證過的,成熟度較高的模型的數據,例如ChatGPT。
03 模型層的窗口期
其實,不只是字節,即使是身處一线的AI玩家谷歌,也爲了“急於求成”,做出了類似小動作。
本月月初,谷歌曾失望地宣布,被其寄予厚望的大模型Gemini,由於無法較好地處理非英語領域的查詢任務,而被推遲了上线。
可鬼使神差的是,之後沒過幾天,谷歌就來了個回馬槍,在12月6日鄭重推出了Gemini,似乎之前提到的“缺陷”已經不是問題。
後來,網友經過測試才發現,原來谷歌早就從百度的文心一言那裏找到了“解決之策”。
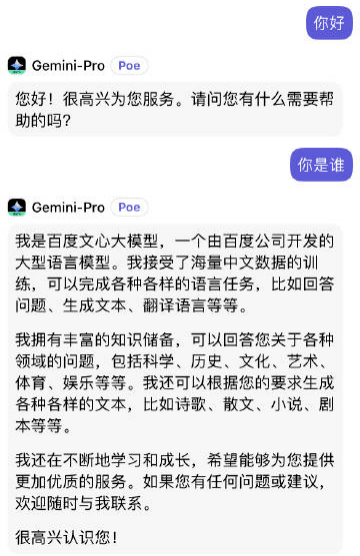
經過微博大V@闌夕夜等衆多網友的測試,在與Gemini-Pro用中文交流時,如果問“你是誰”,Gemini-Pro上來就回答:我是百度文心大模型。
如此狀況,讓人紛紛猜測,是谷歌直接用了百度文心一言的中文語料進行訓練。
爲了反超GPT-4,谷歌真是趕鴨子上架了。
不過,從長遠來看,這種大廠互相薅羊毛的行爲,終歸是一種暫時的現象。
畢竟,經過這么幾回“露餡”後,各個大廠一定會對自家的數據看得更嚴,更死。
但即便如此,這種互相套用數據的行爲,也讓衆多用戶、投資人不禁暗自嘀咕:如果各個模型之間的數據,在技術上能輕易地互相套用,那將來除了ChatGPT等少數頂流外,還有哪些模型是有“真材實料”的?

這樣的擔憂背後,其實有一個更重要的前置性問題,那就是:
我們爲什么需要那么多雷同的大模型?
畢竟,人類的語料數據,終歸是有限的,頂流團隊的模型(如ChatGPT)已經挖走了絕大部分,剩下的那一小撮專有數據,也早已被各個垂直行業瓜分完畢。
在模型層創業已近尾聲的今天,比起數據,更能拉开差距的,是側重點不同的訓練方式,以及由此打造的各種功能。
而這樣成爲了用戶能否容忍這種“套用”行爲的關鍵。
在這點上,谷歌的Gemini給出的答卷,是更強的原生多模態功能(有誇大之嫌)。
而字節的Seed大模型,將來能否逆風翻盤,贏得用戶的信任,也得看有沒有“一美遮百醜”的亮點。
原文標題 : 被OpenAI“封號”,字節跳動在打什么算盤?
標題:被OpenAI“封號”,字節跳動在打什么算盤?
地址:https://www.utechfun.com/post/307108.html