來源:財經E法

AIGC快速發展帶來對算力的需求極速增長,疊加美國對中國AI芯片的出口管制,導致中國的算力受到嚴重制約。通過創新的硬件架構、高效的軟件算法、硬軟件系統協同優化,以及對算力產業的整體战略部署,中國未來有望突破算力瓶頸。
今年以來,以ChatGPT爲代表的AI大模型的出現標志着一個嶄新時代的开啓。大模型技術的快速迭代催生出一批如Midjourney、Character.AI等類型的AIGC(Artificial Intelligence Generated Content)應用,爲辦公、電商、教育、醫療和法律等領域帶來了革命性的改變。
復雜的AI算法需要大量的計算資源來實現,算力是支撐AI算法運行的基礎。AI芯片是專門用於處理AI計算相關任務的協處理器,爲AI算法提供了高效的算力,可以顯著提升深度學習等AI算法模型的訓練和推理效率。
AIGC產業的發展,對算力的需求不斷提升,但中國在算力領域面臨諸多挑战。
2023年10月17日,美國商務部工業安全局(BIS)公布最新半導體管制規則(下稱“1017新規”),升級了BIS於2022年10月7日發布的《對向中國出口的先進計算和半導體制造物項實施新的出口管制》(下稱“107規則”)。1017新規分爲三個部分:一是調整先進計算芯片出口管制規則,二是調整半導體制造設備出口管制規則;三是公布了新增的實體清單企業名單。包括A100、H100、A800、H800等在內的GPU芯片對華出口都將受到影響。A100、H100是英偉達的高性能GPU,廣泛應用於AI、數據分析等工作場景。A800和H800是A100、H100的替代產品,也即在去年美國107規則下,英偉達特供給中國大陸市場的,降低傳輸速率以符合規定的替代產品,但在今年1017新規後被禁售。上述產品均是目前最適合AI算法研發和部署的高算力芯片。
中國在AI領域對算力有着強大的需求,依賴高性能AI芯片來支持其應用和研究。1017新規取消了“互聯帶寬”參數限制,同時新增“性能密度”的參數限制。該新規旨在進一步收窄高端計算芯片的出口範圍;在大模型AI時代,限制中國計算能力,將會限制AIGC在中國的發展和創新。
本文將逐一解讀中國算力面臨的主要挑战,包括芯片架構的性能提升到達瓶頸、現有芯片的算力利用率不足、美國出口管制帶來的供應鏈風險。進而分析破局之策,在軟件方面優化模型和算法,降低算力需求;在硬件方面开發新架構,提高AI芯片能效比;在系統方面協同整合軟硬件,提升系統效率,減少能源消耗;在產業方面加強生態鏈建設與多方協作,推動共同投入。
01
AIGC迭代加快
當前中國大模型技術仍處於研發和迭代的早期階段,但產業潛力巨大。中國的高校、互聯網科技企業、初創科技公司等都紛紛加入AI大模型的浪潮,已誕生超過100個各種類型的大模型。
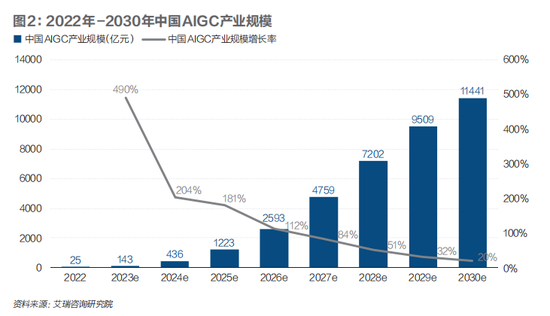
根據艾瑞咨詢的預測,2023年中國的AIGC產業規模將達到143億元,未來幾年增長迅速。預計到2028年,中國AIGC產業規模將達到7202億元,在重點領域和關鍵場景完成技術落地。
AIGC技術在NLP(自然語言處理)和CV(計算機視覺)領域經歷了顯著的演進。AIGC技術和能力的提升,會爲各行業帶來更多的創新和應用機會,主要表現在:
從單一任務到多任務。初始AIGC技術主要關注單一任務,如自然語言生成、圖像生成和翻譯。但未來趨勢是訓練模型同時處理多種任務,並提高模型的泛化能力。
從單模態到多模態。單模態生成式模型通常專注於一種數據類型,如文本或圖像。多模態生成式模型能夠同時處理多種數據類型,如文本和圖像的聯合生成,爲增強現實、智能對話系統和自動文檔生成等多領域的應用帶來新機會。
從通用模型到垂域模型。通用生成式模型在各領域表現出色,但未來趨勢是朝着更專業化和垂域化的方向前進。
02
算力供應不足
隨着AIGC的發展,模型越來越復雜,參數量越來越大,導致算力需求的增長速度已遠超芯片的性能增長速度。在AIGC算法模型部署早期,算力消耗主要集中於大模型訓練,但隨着大模型用戶量增長,推理成本將成爲主要算力开支。
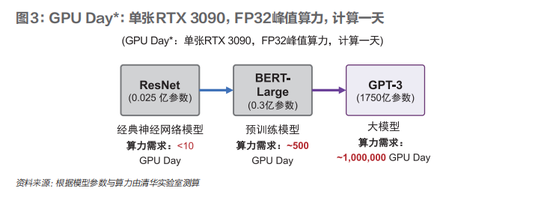
AIGC對算力的具體需求,以三個典型應用場景加以說明:
若Google採用GPT等大模型用於推薦搜索:Google每天接受搜索請求35億次,按照GPT-4 API 0.14元/次的價格,Google每年需要支付1788億元人民幣的API費用。若採用自建算力集群的方案,需要提供每秒約10萬次的峰值訪問能力,一輪GPT-4對話涉及200多萬億次浮點運算,在計算資源利用率約60%的情況下,需要約10萬塊A100集群。
若每個MicrosoftOffice用戶都採用大模型用於辦公:微軟使用基於大模型的Copilot賦能辦公軟件、操作系統與代碼編輯場景,有潛力重構未來辦公場景。未來的軟件开發、文案寫作、藝術創作將在與AI的頻繁互動對話中完成。根據信息技術研究公司的報告《中國數據分析與AI技術成熟度曲线》,中國的學生與白領人群達到2.8億人,按每人每天10次的訪問需求計算,每年具有1.02萬億次訪問需求,需要8萬塊A100的算力支持。
若人人都有一個定制化的AI個人助理(大模型原生應用),AI個人助理向中國12億網民提供定制化的教育、醫療、政務、財務管理等服務。在每人10次的日訪問條件下,需要34萬塊A100算力支持。
根據AMD全球CEO(首席執行官)蘇姿豐在2023年的主題演講,從單一算力中心的角度看,過去十年,超級計算機發展迅速,芯片架構創新與制造工藝的進步使得計算機性能每1.2年翻一番。而計算機的能量效率(即單位能量下的計算次數)增長速度僅爲每2.2年翻一番。在保持這個趨勢的情況下,到2035年,一個高性能的超級計算機功率將達到500MW,約爲半個核電站的發電功率。
AIGC嚴重依賴於高算力,但目前中國在算力方面卻遇到了極大挑战。
1)推動芯片性能提升的摩爾定律難以繼續維系。
半導體器件的尺寸已逼近物理極限,而制程進步帶來的性能提升幅度在收窄。芯片能效比增速明顯放緩,更高的晶體管密度也帶來更大的散熱挑战與更低的生產良率。目前AIGC對算力的需求遠遠超過AI芯片的發展速度,現有的芯片硬件性能的提升速度難以滿足算法模型急劇增長的算力需求,需要新的硬件架構突破。
2)GPU利用率低。
大模型在處理大量數據時,由於算力調度、系統架構、算法優化等諸多問題,很多大模型企業的GPU算力利用率不足50%,造成了巨大的浪費。
3)軟件生態不成熟。
目前主流的AI算法都是基於英偉達CUDA進行適配,英偉達的CUDA軟件自2006年問世以來,經過十多年的積累,形成了包括驅動、編譯、框架、庫、編程模型等在內的成熟生態。目前主流AIGC算法訓練,大多基於CUDA生態進行开發,壁壘極強。AIGC公司若要更換英偉達GPU,面臨極高的遷移成本和穩定性的風險。因此國產GPGPU產品想要大規模部署,軟件生態是一個極大挑战。
4)高性能AI芯片供應量不足。
大算力芯片是大模型研發的基礎設施,英偉達高性能GPU芯片具有兩個核心優勢:一是更大的顯存配置與通信帶寬。高帶寬的芯片之間互聯對提升大模型訓練效率至關重要。二是更高的大模型訓練耐用性。消費顯卡面向個人應用,故障率和穩定性遠差於服務器版本。千億參數大模型訓練需要數千GPU長周期同步運算,任何單一顯卡的故障均需要中斷訓練、檢修硬件。相比於消費級顯卡或其他芯片,高性能GPU可以減短60%-90%大模型訓練周期。
然而,英偉達GPU產能不足,且美國逐漸加碼對中國高性能芯片禁售力度。去年10月,美國對出口中國的AI芯片實施帶寬速率限制,其中,涉及英偉達A100和H100芯片。此後,英偉達向中國企業提供替代版本A800和H800。根據1017新規,英偉達包括A800和H800在內的芯片對華出口都將受到影響,國內的高性能AI芯片供給出現嚴重短缺。
目前大模型訓練主要依賴於英偉達高性能GPU,禁售對於國內大模型研發進度,帶來極大影響。例如,使用符合1017新規的V100 GPU替代A100,算力和帶寬的下降將使得大模型訓練時間增加3到6倍,顯存的下降也將使能訓練模型的最大參數量下降2.5倍。
5)自研AI芯片難以量產。
美國將先進芯片的出口許可證要求增加到22個國家。繼先前限制EUV光刻機出口到中國之後,也开始限制更低一代的DUV光刻機。此外,美商務部將中國本土領先的GPU芯片企業加入到實體清單中,這將會導致國內自研芯片難以使用最新的工藝制程進行流片量產。
6)高能源消耗帶來的電力系統壓力。
算力中心的計算、制冷與通信設施均爲高能耗硬件。中國電子節能技術協會數據顯示,目前中國數據中心的耗電量平均增長率超過12%,2022年全國數據中心耗電量達2700億千瓦時,佔全社會用電量的3%。在大模型時代,中國數據中心耗電量會加大增長幅度,並在2025年預計達到4200億千瓦時耗電量,約佔社會總用電量的5%。數據中心的電力供應以及系統散熱,都將給現有的電力系統帶來很大的壓力。
03
技術如何破局?
面對不利局面,中國的算力瓶頸需要以系統觀念統籌謀劃,逐步突破,主要包含技術和產業兩個層面,方式主要是“开源”和“節流”。
技術層面,我們的建議如下:
1)發展高效大模型。
通過精簡模型參數的方式降低對算力的需求。壓縮即智能,大模型旨在對數據進行無損壓縮。今年2月28日OpenAI核心研發人員Jack Rae表示,通用AI(AGI)的目標是實現對有效信息最大限度的無損壓縮。隨着大模型發展,在AI復雜性提升的同時,相同參數規模下,算法模型能力也會持續提升。未來或出現具有更高信息壓縮效率的大模型,以百億級參數規模獲取媲美萬億級參數規模GPT-4的算法能力。
此外,大模型可以面向特定業務場景做領域適配和能力取舍,減少算力开支。例如在政務問答場景中,模型可以謝絕回答非業務請求。原本依靠千億參數通用模型才可以解決的任務,有望使用百億參數量模型即可完成。
2)基於現有模型的軟件優化。
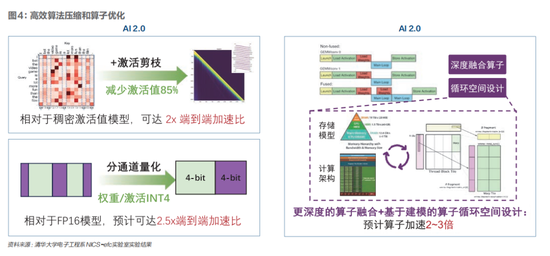
如果將GPT-3前後的AI發展劃分成1.0與2.0時代,那么AI 1.0時代的軟件優化核心任務是使深度學習模型可以在邊緣、端側的低功耗設備上運行,實現自動化與智能化,以在AIoT、智能安防與智能汽車等領域大面積應用。而AI 2.0時代的模型壓縮則是規模化、集中化算力需求的整體優化,應用場景需要從“中心”側开始,然後向邊、端側輻射。
模型壓縮是最直接降低算法算力需求的方法,這一AI1.0時代的技術在AI2.0時代也將得到繼承與發展。
剪枝利用了深度學習模型參數冗余的特點,將對准確率影響小的權重裁剪,保留網絡主幹並降低整體計算开支。在AI2.0時代中,Transformer算法模型在長序列輸入的情況下,計算延時的瓶頸在注意力機制算子,通過對注意力機制算子的激活值進行裁剪,目前可達到2倍的端到端的加速比,未來有望進一步加速。
參數量化利用了GPU處理定點數的等效算力顯著高於浮點數計算算力的優勢,利用16比特、8比特、4比特定點數替代32比特浮點數,有望同步降低推理算力需求。
算子融合(Operator Fusion)將多個算子融合成一個算子,提高中間張量數據的訪問局部性,以減少內存訪問,解決內存訪問瓶頸問題。算子循環空間的設計與尋優則通過將計算圖中的算子節點進行並行編排,提升整體計算並行度。
總之,通過對現有大模型進行壓縮和量化,可以顯著減少模型參數量、降低模型計算復雜度,節約存儲空間,目前可提升2倍-3倍的計算效率。在降低大模型響應用戶的延遲的同時,模型優化技術更可以將大模型高效部署在汽車、個人電腦、手機、AIoT等邊、端側設備中,支持具有高實時、隱私保護、安全性等特點的本地大模型應用。
3)高能效、高算力密度的新架構芯片。
傳統計算芯片的能效到達瓶頸,需要通過對芯片架構、互聯、封裝的改進,從而實現更高的能效。目前主要的方式是數據流架構、存算一體、Chiplet技術等。
數據流架構:通過數據流流動次序來控制計算順序,消除指令操作導致的額外時間开銷。數據流架構能夠實現高效流水线運算,同時可並行執行數據訪問和數據計算,進一步減少計算單元的空闲時間,充分利用芯片的計算資源。與指令集架構不同的數據流架構,使用專用數據通道連接不同類型的高度優化的計算模塊。利用分布式的本地存儲,數據讀寫與計算同時進行,節省了數據傳輸時間和計算時間。
存算一體:存算一體芯片的核心是將存儲與計算完全融合,利用新興存儲器件與存儲器陣列電路結構設計,將存儲和計算功能集成在同一個存儲芯片上,消除了矩陣數據在存儲和計算單元中的數據搬運,從而高效支持智能算法中的矩陣計算,在同等工藝上大幅提升計算芯片的“性能密度”。
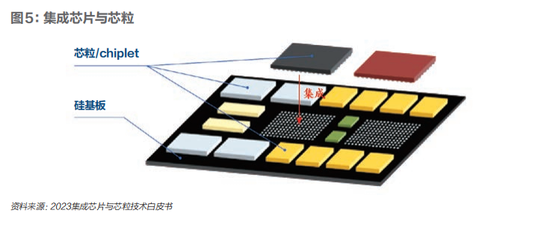
Chiplet技術:傳統集成電路將大量晶體管集成制造在一個硅襯底的二維平面上,從而形成芯片。集成芯片是指先將晶體管等元器件集成制造爲特定功能的芯粒(Chiplet),再按照應用需求將芯粒通過半導體技術集成制造爲芯片。Chiplet技術可以實現更大的芯片面積,提升總算力;通過chiplet/IP等的復用和組合,提升芯片的設計效率;把大芯片拆成多個小尺寸chiplet,提升良率,降低成本;不同芯粒可以通過不同工藝完成制備,通過異構實現更高性能。
全新的計算架構,可以打破現有芯片的存儲牆和互聯牆,將更多算力單元高密度、高效率、低功耗地連接在一起,極大提高異構核之間的傳輸速率,降低數據訪問功耗和成本,從而爲大模型提供高算力保障。
4)軟硬件協同優化,提高計算系統的利用率。
在大模型系統中,軟硬件協同對於實現高性能和高能效至關重要。通過稀疏+混合精度+多樣算子的高效架構設計、算法優化、系統資源管理、軟件框架與硬件平台的協同以及系統監控與調優等技術,可以更好發揮整個算力系統的優勢。
在大模型訓練方面,由於訓練所需的算力與存儲开銷巨大,多卡互聯的高性能集群計算系統是大模型訓練的必然途徑。英偉達高性能GPU的供應鏈在中國受到制約,國產化芯片單卡性能受工藝限制,如何使用萬卡規模的國產化芯片進行可靠、穩定的大模型訓練將是一個必須解決的關鍵問題。除了提高計算系統規模外,還需开展軟硬件協同的高效微調方案研究,降低大模型訓練與微調的硬件資源开銷。
在大模型系統中,有效的系統資源管理對於確保高性能和高效率至關重要。這包括合理分配計算資源(如CPU、GPU等),優化內存管理和數據傳輸策略,以降低延遲和提高吞吐量。
爲了實現軟硬件協同,深度學習軟件框架需要與硬件平台緊密配合。這包括針對特定硬件平台進行優化,以充分利用其計算能力和存儲資源,以及提供易用的API和工具,以簡化模型訓練和部署過程。
5)構建異構算力平台。
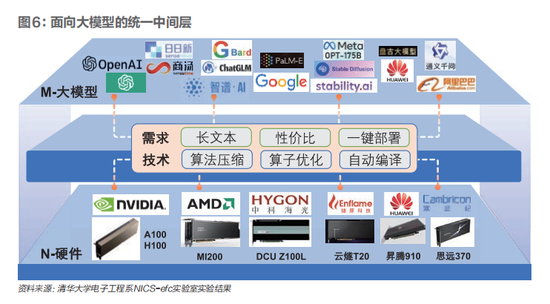
由於AI算法模型參數量與計算復雜度急劇提升,大模型訓練需要大規模跨節點的多卡集群,其硬件挑战來自計算、存儲、通信。構建一個千卡規模的大模型數據中心,成本高達上億元,很多初創公司難以承受。爲解決上述難題,降低數據中心建設成本,亟待構建集中算力中心,整合不同架構的異構芯片,實現滿足各類應用場景需求的大算力平台。統一的大模型中間層,向上可以適配不同垂直領域大模型,向下可以兼容不同國產AI芯片,從而提升異構算力平台的使用效率,降低用戶在不同模型、不同芯片之間的遷移成本,是解決大模型時代算力挑战的關鍵方向之一。
6)布局先進工藝。
“性能密度”這一核心指標,是由制造工藝、芯片設計水平、先進封裝等多個層面協同之後的作用。在當前國內對3nm/5nm等先進制造工藝獲取受限的背景下,需要持續攻關先進制造工藝環節中的重要設備和材料,如DUV/EUV光刻機、光刻膠等。
7)能源的優化利用
在碳中和背景下,應對算力中心極高的能耗需求,“數據中心+清潔電力+儲能”將是必要發展的路徑。數據中心將成爲負荷可變、可調的復合體,以便於響應發電、電網側需求,並通過參與電力交易實現智能化“削峰填谷”套利,降低運營成本。
根據《數據中心能源十大趨勢白皮書》,高能耗算力中心無法依靠風冷實現有效散熱,液冷將成爲標配,供水效率也成爲算力中心的關鍵。傳統數據中心散熱的水資源消耗極大,對缺水地區的生態環境造成影響。水資源利用效率(WUE)成爲國際關注的重要參考指標,無水或少水的制冷技術是未來的發展趨勢。
04
產業如何應對?
產業層面,我們則有以下建議:
1)加強頂層設計,謀劃算力產業的战略部署;日前,工信部等六部門聯合印發《算力基礎設施高質量發展行動計劃》,加強對算力產業的頂層設計,但仍需要進一步加強整體性謀劃。建議在現有相關領導小組中設置算力發展委員會(或聯席會),秉持適時適度幹預立場,加強算力發展的頂層設計,健全信息交換機制,形成統一協調的決策機制。
2)優化空間布局,整體性推進算力基礎設施建設;在貫徹落實“十四五”相關規劃的基層上,加強一體化算力網絡國家樞紐節點建設,針對京津冀、長三角、粵港澳大灣區等關鍵算力節點,有序按需推進算力基礎設施建設,着力推動已建及新建算力設施利用率。
3)布局引領項目,提升行業共性關鍵技術儲備。發揮國家科技計劃的標志性引領性作用,可考慮在國家自然科學基金啓動一批項目,开展計算架構、計算方式和算法創新等基礎研究;同時,在國家重點研發計劃中設立一批項目,开展算力關鍵技術的應用示範研究,加強算力與相關產業融合應用。
4)探索多元投入,助推算力產業高質量發展。充分發揮產業引導基金的撬動作用,鼓勵地方政府通過引導基金加大對算力產業的投入,培育更多好企業、好項目。探索新型科技金融模式,加大對算力重點項目的金融支持。創新算力基礎設施項目的社會融資模式,支持社會資本向算力產業流動。
5)營造开放生態,共同構築新業態新模式。算力的高投入、高風險、高壟斷性決定了算力的競爭是少數大國的少數企業才能參與的遊戲。政府要大力推動產學研深度融合,引導龍頭企業在算力相關的關鍵技術上下功夫,提升研發能力,搭建开放平台,吸引上下遊企業有效銜接,共享算力創新成果。鼓勵國內企業、高校等組織與境外有關組織拓展合作。
總結而言,破局算力瓶頸,需要硬件、軟件、系統的耦合,基金、生態、產業的協作,具備多層次、多學科大體系的特點。需要把產業應用、科學研究、人才培養、基礎平台等結合起來,推動相應的研究及最終商業化落地。
 海量資訊、精准解讀,盡在新浪財經APP
海量資訊、精准解讀,盡在新浪財經APP
責任編輯:楊紅卜
標題:中國如何突破算力“卡脖子”
地址:https://www.utechfun.com/post/301284.html