前言:
存算一體架構正受到學界、產界等各方的熱議。
智能化時代的算力需求和計算服務業態正在發生變革的背景下,巨頭IDM廠商和國內新銳的算力芯片廠商都在探索存算一體芯片,並衍生出不同的架構和技術路线。
作者?| 方文三
圖片來源?|??網 絡?
存算一體底層創新
目前市面上的芯片都是基於馮諾依曼架構,其特點是處理單元和存儲單元分離,各不相幹,需要運算的時候,計算單元再從存儲單元讀取數據進行處理,處理完再還回去。
而存算一體則是把存儲單元和處理單元合二爲一,去掉了中間傳輸路徑,所以可以大幅減少數據搬運,消過程中不必要的延遲和功耗,能耗可降至 1/10-1/100,能效可提升 10-100TOPS/W。
因爲存儲一體是以存儲器爲介質,在裏面加入計算單元,所以可以直接利用存儲單元進行邏輯計算提升算力,在特定區域可提供 1000TOPS 以上的算力。
存算一體芯片目前發展難點
傳統架構是計算和存儲相分離,現在兩者要合二爲一,這就對存儲器本身和存算一體的設計提出更高的要求,是需要技術人員從頭探索的新領域。
基於存算一體是把計算和數據高度耦合,因此一旦其中一方出問題,另一方幾乎也會遭到極大影響,這都是需要處理的難題。
其中最重要一點便是生態與編程框架不完善,缺乏相應的指令集與軟件工具。
一方面,各單位、公司开發的存算一體芯片均基於自行定義的編程接口,缺乏統一的編程接口,造成了存算一體軟件生態的分散,不同廠商开發的上層軟件無法互相通用,極大的影響了存算一體芯片的大規模使用。
另一方面,除了高效的硬件設計,神經網絡模型面向存算一體架構時,計算任務如何映射、調度,也是發揮神經網絡加速器性能和能效的關鍵。
存算一體國內外玩家盤點
存算一體技術可有效突破芯片性能瓶頸,是解決算力提升放緩和算力需求快速增長之間尖銳矛盾的一種關鍵技術路徑,目前存算技術正處在從學術到工業產品的躍遷的關鍵時期。
三星
三星2021年2月發布HBM2-PIM,將4片常規DRAM die和4片具有計算功能的DRAM die通過TSV通孔垂直組合在一起。其中具有計算功能的DRAM die內部集成了計算邏輯單元,即將A引擎引入每人存儲子單元,從而將處理操作轉移到HBM。每個存儲子單元都有一個嵌入式可編程計算單元(PCU) ,其運行頻率爲300 MHz,每個裸片上 (PIM-DRAM die) 有32個PCU。
Mythic
Mythic2021年5月獲得 7000 萬美元的 C 輪融資,累計融資金額1.652 億美元產品特點: 基於區塊的A 計算架構一一內存計算、數據流架構和模擬計算。
2021年6月發布由72個AMP切片構成,每個切片內部集成一系列閃存單元、ADC陣列、1個32位RISC納米處理器、1個16位SIMD矢量處理器、SRAM和1個片上網絡 (NOC) 路由器,算力達25TOPS。
阿裏達摩院
達摩院研發的存算一體芯片是全球首次採用混合鍵合(Hybrid Bonding)的 3D 堆疊技術,將計算芯片和存儲芯片 face-to-face 地用特定金屬材質和工藝進行互聯。
得益於整體架構的創新,達摩院的存算一體AI芯片同時實現了高性能和低系統功耗。
在實際推薦系統應用中,相比傳統CPU計算系統,該芯片的性能提升10倍以上,能效提升超過300倍。
後摩智能
後摩智能由吳強博士與多位國際頂尖學者和芯片工業界資深專家聯合組建,是全球存算一體智駕芯片的先行者。
後摩智能發布了首款存算一體芯片——鴻途 H30,最高物理算力 256TOPS,功耗僅爲 35W,碾壓國內一衆智駕芯片。
蘋芯科技
蘋芯科技已开發實現多款基於SRAM的存內計算加速單元,致力於爲人工智能行業提供了低成本、高效率、低能耗、高性能的芯片解決方案。
與此同時,面向多元化的場景,公司也正在开發利用新型存儲器爲底層技術,爲客戶提供便捷的AI硬件加速方案。
此方向突破了傳統馮·諾伊曼架構所帶來的局限,可廣泛應用於衆多人工智能行業領域,包括但不限於智慧城市、智能家居、工業物聯網,以及各類智慧終端、可穿戴設備、自主無人系統等領域。
知存科技
知存科技專注存內計算芯片領域,創新使用Flash存儲器完成神經網絡的儲存和運算,解決AI的存儲牆問題,提高運算效率,降低成本。
公司旗下WTM2101芯片適配低功耗AIoT應用,可使用微瓦到毫瓦級功耗完成大規模深度學習運算,可應用於智能語音、智能健康等市場領域,目前已完成批量生產和市場應用。WTM8系列芯片面向6-48Tops算力產品,應用於4K-8K視頻的實時處理。
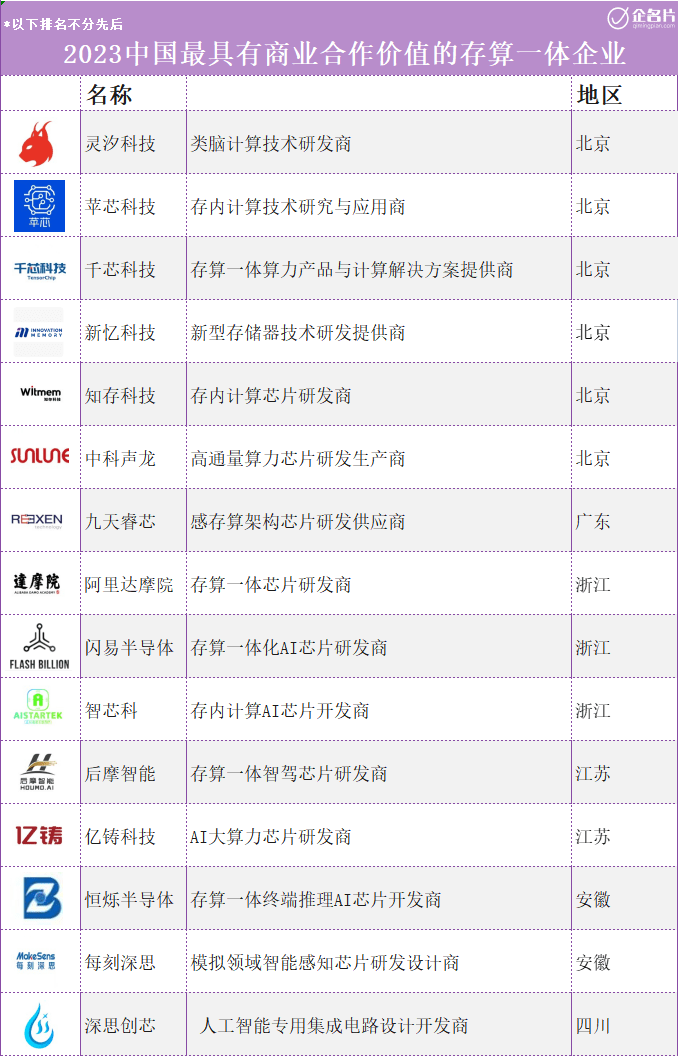
存算一體芯片市場前景
存內計算的發展類似於存儲器的發展路徑,算力每年可以有5-10倍提升,能效每年會有1-2倍提升,成本每年會有30-50%下降,能把成本、算力、能效都可以做到最優。
中早期的存算一體芯片算力較小,更多地應用在對低功耗和高能效有強烈需求的端側場景,比如智能家居場景下的智能語音和輕量級視覺層面的應用。
但存算一體芯片算力不斷提升,其使用範圍逐漸擴展到邊緣端以及雲端的大算力應用領域。
智能駕駛技術的迭代升級,智能汽車對算力的需求越來越大;並且,智能汽車作爲一個邊緣端設備,相比雲端,對成本和功耗更爲敏感。
存算一體技術通過將計算功能和存儲功能有機融合,可有效降低甚至消除數據頻繁搬運帶來的功耗問題,並且能夠在不依賴於先進工藝的情況下,做出大算力芯片,能夠同時兼顧能效和成本,可破解當前傳統架構大算力AI芯片的所面臨的一些困局。
也是智能駕駛場景下被業內人士迫切期待的一種高能效AI芯片架構的技術實現路徑。
存算一體芯片开源指令集和編譯器
在今年的集成電路EDA領域頂級會議上,中國科學院計算技術研究所智能計算機中心陳曉明和韓銀和研究員團隊發表論文,公布了一項新的研究成果:PIMCOMP-NN存算一體通用編譯器和PIMSIM-NN——存算一體通用模擬器,二者基於一套之前該團隊开源的存算一體指令集,構成了完整的开源存算一體工具鏈,該項工作或將爲存算一體芯片建立統一的生態做出一定的貢獻。
該工具鏈建立在一套面向神經網絡的存算一體指令集基礎上。
指令集作爲芯片軟硬件設計的接口,對於軟件生態有着舉足經重的作用,爲了使工具鏈對多種多樣的存算一體芯片的底層操作具有通用性,該課題組首先抽象了存算一體架構支持的基本算子,定義了一套統一的面向神經網絡的存算一體指令集。
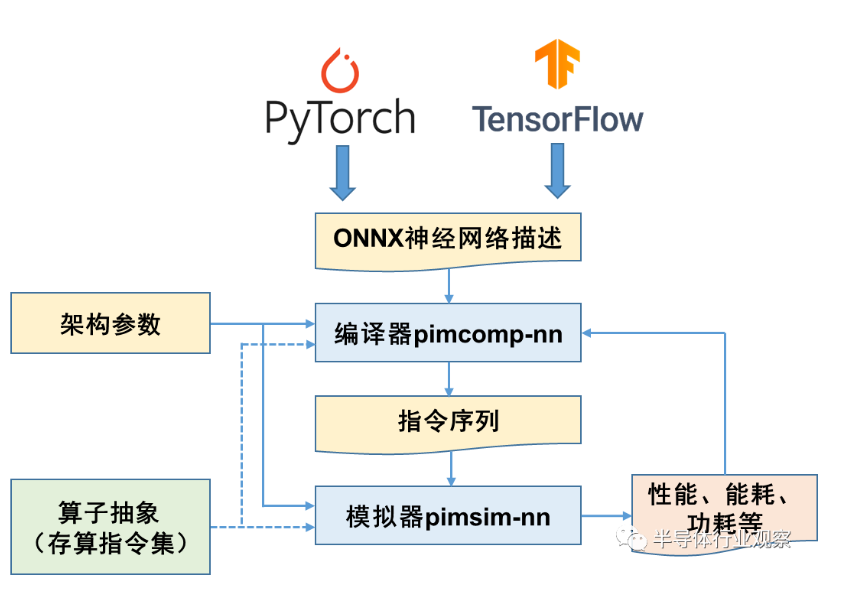
隨着开源理念在存算一體領域的拓展,將有助於行業建立統一的編程和接口標准,從而使來自不同廠商和研究機構的產品實現互通。
這一標准化進程將有助於解決目前存算一體芯片領域的碎片化問題,提高生態系統的協同效率。
進一步推動存算一體芯片更容易與人工智能、大數據、物聯網等產業相結合,形成更加豐富和復雜的應用場景。
結尾:
隨着矛盾不斷升級,高通和Arm破鏡難圓已成定局。
對Arm公司來說,上有PC端巨擘X86的競爭壓力,下有RISC-V欲取而代之;
再加上昔日盟友高通這一肘腋之患,重重隱憂正在動搖ARM在芯片產業下遊的統治基礎。
部分資料參考:熱點微評:《ARM霸權下:高通的叛逃與國產廠商的無奈》,三易生活:《驍龍8 Gen4或全面換用自研架構,ARM不樂意了》, 談芯說科技:《人工智能突飛猛進,ARM是否會掉隊?》
原文標題 : AI芯天下丨趨勢丨存算一體芯片邁進开源
標題:存算一體芯片邁進开源
地址:https://www.utechfun.com/post/254299.html