語言可以殺人——網絡時代,相信沒人會否認這一點。
語言攻擊,是最具代表性的網絡暴力之一。謾罵剛失去兒子的母親,詆毀女孩的粉色頭發,嘲笑男性的氣質“太娘”,炮制莫須有的黃色謠言……無數侮辱性的語言,在網絡間橫行無阻,給他人帶來了無窮無盡的精神傷害。
語言暴力,已經成爲網絡治理的全球性難題。

各種方案被使出,但都無法有效阻止“網絡暴民”的增加和語言暴力的橫行。其中,技術層面的解決思路,就是利用AI算法來自動檢測有毒語言,按照攻擊性來設定毒性評分,並對高毒性語言進行預防處理,比如屏蔽、心理幹預等。
但由於語言的模糊性,此前的機器學習算法魯棒性不強,很容易做出錯誤判斷,導致識別和幹預的結果並不理想,仍然需要大量人工審核員。不僅處理效率低下,而且長期閱讀有毒語言也會傷害人類審核員的心理健康。
ChatGPT這類大語言模型,憑借強大的魯棒性和泛化能力,展現出了前所未有的語言理解力。
按理說,本着“技術向善”的宗旨,大語言模型應該被用來更有效、高效地預防網絡暴力,但爲什么迄今爲止,我們仍然沒有見到相關應用?反倒是利用大語言模型生成更多有害內容的“技術作惡”大行其道。
大語言模型,也救不了“網絡暴民”,難道我們注定只能在有毒網絡環境下“數字化生存”嗎?
大語言模型,內容檢測技術的一大步
預防,是治理網絡暴力最重要的環節。利用AI內容檢測來預防網絡暴力,相關研究已經有數年歷史了。
2015年就有人提出,個體的情緒狀態就與有害意圖之間存在顯著關聯,使用機器學習來檢測社交媒體中的有害行爲,被認爲是網絡暴力檢測的良好指標。
也就是說,一個人在生活遭遇了劇變、坎坷或感到低落、鬱悶等情緒狀態不佳時,就容易在網絡上發出仇恨、攻擊、詆毀等冒犯性語言。
2017年,谷歌的Jigsaw創建了Conversation AI,檢測在线有毒評論。許多科技巨頭,多年來一直在將算法納入其內容審核中,都有一套對網絡信息內容進行識別和過濾的手段。比如國內某短視頻平台,就研發了100多個智能識別模型,來提前攔截辱罵內容,但該平台依然是網暴的“重災區”。某問答平台,會對評論內容進行識別,對有風險的內容進行提醒,直到用戶修改才允許發出。
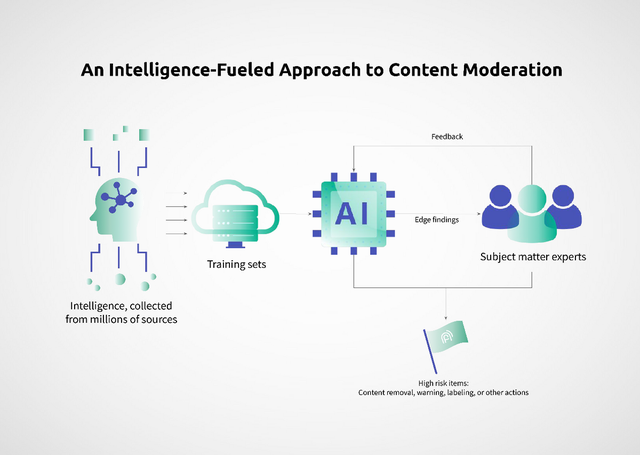
但顯而易見,這些AI檢測算法也並沒有根除網暴,網友對平台治理網暴的批評仍是“不作爲”“沒效果”。原因之一,是傳統的機器學習算法,不能滿足網絡內容的審查需求:
1.理解力不夠。有害語言非常難以區分,而AI算法的語義理解能力不夠強,經常會將有害評論和無害評論給出相同的分數,沒有真正過濾掉那些不尊重的評論,或者給中性句子更低的分數,過濾了不該過濾的正常評論,阻礙了博主和粉絲的交流。
2.靈活性不夠。某些網站可能要求檢測攻擊語言,但不需要檢測謠言,而其他網站的要求可能恰好相反。傳統的AI檢測工具往往使用一個通用的“毒性評分”,不夠靈活,無法滿足不同平台的不同需求。
3.更新速度不夠。很多檢測算法是使用API來工作的,而這些模型通過大量網絡數據進行訓練,在與訓練數據相似的示例上表現良好,一旦遇到不熟悉的有毒語言,比如涉及飯圈的討論會有很多黑話、yyds之類的拼音簡寫,以及不斷新造的詞語,很可能就會失敗。某社交媒體平台,一开始設置了一百多個禁發關鍵詞,比如一些髒話、“綠茶婊”“怎么不去死”等,如今已經增加到了700多個。所以,AI模型缺乏高效實時的人類反饋,無法快速微調並迭代模型,從而導致自動化檢測的效果不佳。
我們知道,大語言模型具備智能湧現、預訓練、人類反饋的強化學習等特點,這就對傳統方法帶來了很大的助力,更強的語言理解能力,使用通用模型可以很快訓練出精度更高的定制模型,同時借助人類反饋查漏補缺,獲得更好更快的檢測效果。
防範網絡暴力,已經成爲各國互聯網治理的重點,平台也能因此建立起更良好的社區氛圍,所以大語言模型在檢測有害語言方面,應該能大展拳腳才對。
但爲什么這一波大語言模型的浪潮中,我們很少見到將LLM用於預防網絡暴力的探索呢?
AI,防範語言暴力的一小步
在AI技術體系內部來看,從傳統NLP到大語言模型,是一個自然語言理解的飛躍式進步。但走到更大的現實中,AI的一大步,也只是將問題解決向前推進了一點點。
作用不能說沒有,但也很有限。應對網絡中的語言攻擊,AI的力量仍然弱小。
首先,敵人數量太龐大。
康奈爾大學信息科學部門的丹尼斯庫表示,很多時候,你我這樣的普通人都會成爲網絡暴力的幫兇。當爲數不少的網民自身積怨和不滿得不到緩解之時,會對周圍事物看不慣,在互聯網上用語言攻擊他人,來緩解負面情緒。
此前《三聯生活周刊》有一篇報道,某位網絡暴力受害者已經去世,作者聯系到的一些施暴者則回應稱“忘記自己當時做過了什么”。
許多網暴者平時看起來是非常正常的,會在某些時刻、某些偶然事件後,短暫地化身“語言惡魔”,然後“事了拂衣去,深藏身與名”,即使是AI,也很難及時准確地判定出,哪些人存在攻擊可能。
此外,語言攻擊越來越隱蔽。
AI自動檢測技術發展到今天,一些明顯有害的言論,比如威脅、隱晦、辱罵等,已經可以被直接屏蔽掉了,但人類用語言傷害人的“創造力”是很大的,很多在機器看來中性化的語言,也可能惡意滿滿。
比如此前校園事故中痛失孩子的母親,就被大量評論“她怎么看起來不傷心”“她怎么還有心思打扮”,看似並沒有什么侮辱性語言,但這些質疑累加在一起,卻形成了對受害者的“道德審判”。

對於隱蔽的攻擊性語言,目前的NLP模型還有比較大的局限性,語言背後的實際、細微的含義,很難被捕捉到,依然需要人工審核的幹預。
而平台監測語言暴力,並沒有一個通行的判定體系,往往是各個平台自己酌定。比如知乎會判定邪路隱私、辱罵髒話、扣帽子、貼負面標籤等行爲。豆瓣則會處理諷刺、擡槓、拱火、歧視偏見等。不過,這些標准都有很大的主觀成分,所以大家會看到“掛一漏萬”的現象,一些很正常的發言被斃掉,一些明顯煽動情緒的發言沒有被及時處理。
另外,網絡信息的“巴爾幹化”。
巴爾幹化,指的是一些四分五裂的小國家,互相敵對或沒有合作的情況。一項研究顯示,互聯網雖然消除了地理屏障,讓不同地區的人可以低成本地相互交流,但卻造成了觀念上的“巴爾幹化”,輿論上的分離割裂程度越來越嚴重。
網絡信息的推送機制,算法設計還不夠科學,偏好設置過於狹窄,採用關鍵詞聯想、通訊錄關聯、圖網絡等過濾方式,類似“喫了一個饅頭=喜歡喫饅頭=再來一百個饅頭”“你媽愛喫饅頭,你也一定愛喫”“饅頭=更適合中國寶寶體質的吐司=看看吐司”。人們長期停留在有限的信息範圍內,對自己感興趣的內容之外的信息很少涉獵,和其他群體之間的觀念間隙會越來越大。
信息獲取機制的“巴爾幹化”,會導致輿論“極化”,就是一個觀點反復發酵,從而引發大規模的跟風行爲,網暴風險也就提高了。
數量多、識別難、極化情緒嚴重,將互聯網變成了一個負面語言的遊樂場。
技術之外,做得更多
當然,AI防止網暴道阻且長,但咱們不能就此放棄努力。
大語言模型的出現,帶來了更強大的自動檢測潛力。媒體機構基於通用模型,可以訓練出更高精度、識別能力更強的行業大模型,用人類專業知識來增強模型效果,創建具有人類智能的AI檢測模型,從而支持更加復雜的內容理解和審核決策,提高有害內容的檢測效率。
升級技術之外,必須做的更多。預防網絡暴力,與其說是一個技術問題,不如說是一個社會問題。網絡信息環境不改變,攻擊語言還會不斷變種,增加技術檢測的難度與成本,這是用戶、平台和社會所不堪承受的。
但此前,很多治理方法效果都不是很理想。

比如說,網絡匿名是暴力的“隱身衣”,於是實名制成爲一項重要的治理手段,但效果並不理想。韓國是第一個施行網絡實名制的國家,於2005年10月提出要實行網絡實名制,但按照韓國的統計,實名制之後,網絡侵權行爲從原來的13.9%降到了12.2%,僅降了1.7%。
立法也是被期待的一種。各國都在不斷推出法規,韓國《刑法》對網絡暴力最高判處七年有期徒刑,我國刑法、民法中也有相應的規定,治理網絡暴力並非無法可依。但立法容易、執法難。
網絡環境復雜,網暴攻擊的發動者難以確定,網暴一般是由大量跟帖評論等攻擊行爲累加而成的,證據收集十分困難,容易滅失,“情節嚴重”難以認定,維權周期長,網暴受害者的維權成本太高,最後大多不了了之,很難對施暴者產生實際的懲罰,助長了“法不責衆”的僥幸心理。
要改變“法不責衆”的難題,治本的辦法,是消除“無意識跟風”的“衆”。
網暴不是一個人能完成的,除了少數發布者之外,大量攻擊言論,都來自是上頭了的跟風者,是網民集體非理性行動的結果。
報紙時代、電視時代的單向傳播,只有少數群體有發言、評論的機會,而大衆在线下面對面交流時,也不會輕易侮辱攻擊別人。到了網絡時代,隨着智能手機的普及,所有人都可以直接在網絡上表達自己的意見,一旦媒體素養跟不上,信息識別能力不夠,那么面對真假難辨的網絡信息,煽動性的語言,就很容易衝動失控,無意識地加入網暴大軍。
很多人在評論時,並不一定經過了理性的思考和判斷,只是看自己關注的博主那么說,或者很多人都在討伐,就跟風批判,使網絡暴力升級。
對此,指責“網暴者”的行爲偏激,反而又會形成新的“網暴”。“用魔法打敗魔法”,會嚴重擾亂了網絡話語生態。很多偶發性的“語言暴力”,是可以通過個人媒體素養的提高去規避的。
這就需要專業媒體機構和有關部門,投入更多媒體資源,面對網絡時代,幫助人們習得更高的媒體素養,實現更文明、友好的“數字化生存”。

每個人內心深處都有某種暴力衝動。正如羅翔老師所說,“我們遠比自己想象的更僞善和幽暗,每個人心中都藏着一個張三”。
當理性上升,當一個人習得了自我控制的能力,那么“非理性”的暴力一定會減少。比起AI的繮繩,真正能消除網暴的,是每個人心中的道德律令。
原文標題 : 大語言模型,救不了“網絡暴民”
標題:大語言模型,救不了“網絡暴民”
地址:https://www.utechfun.com/post/237096.html