
之前看GPT-4像喬峰,武功蓋世。現在看GPT-4像慕容復,浪得虛名?
文 | 佘宗明
發現沒,好像沒什么人再吹GPT-4了(包括我)。
料到了它的熱度會降下來,不降對不起Gartner曲线,但沒想到是斷崖式下降。
要知道,110多天前,作爲ChatGPT進化版的GPT-4剛問世時,很多人還被它能1秒生成網站、解答邏輯題、調侃腦筋急轉彎的能力驚到了。
那時候,國人的反應通常包括幾點:
先是震驚,「真是牛逼Plus」。
後是擔心,「差距又拉大了」。
接着是覺得自己想象力已經不夠用了:按照GPT這一日千裏的進化速度,GPT-5出來後,是不是得宣告大結局了?
盡管今天輿論談到GPT時習慣提ChatGPT,但GPT-4其實是更強大的存在。
「皮衣刀客」黃仁勳就說:GPT-4的厲害之處,OpenAI也沒說清楚。
360創始人周鴻禕則是將GPT-4視作「通用人工智能的奇點和強人工智能到來的拐點」。
「硅基取代碳基」的話題,也被GPT-4的史詩級進化帶入輿論場。
包括馬斯克跟AI教父Bengio在內的上千名科技行業人士,沒多久後還聯名發公开信,呼籲暫停強AI的研發。
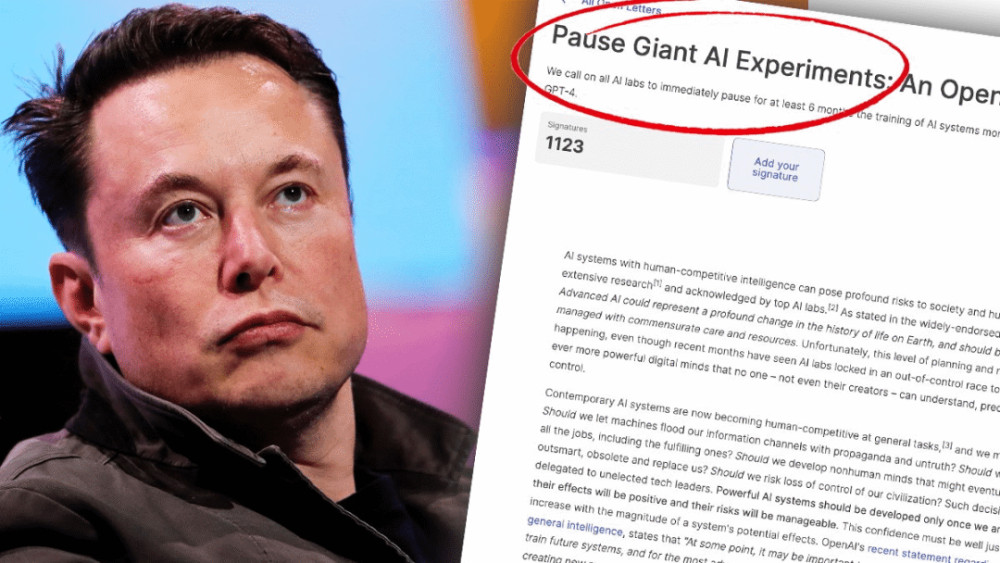
▲馬斯克等上千名科技人士此前曾發聯名公开信,呼籲爲強AI研發摁暫停鍵。
一股擔心科技大爆炸引發社會大震蕩的流行情緒,在全球蔓延开來。
可現在呢,你跟許多人說GPT-4,他沒准會回你:GPT什么?G什么4?什么PT4?
你說:行,你先涼快着吧。他說「好嘞」,爾後繼續刷普裏戈任或蔡徐坤。
天空響了一道驚雷,但風暴雨並沒有來。
何止是GPT-4,就連ChatGPT和背後的OpenAI公司,都在「增長放緩」的判斷和「這輪AI見頂了嗎」的分析中,顯得有些黯淡失色。
以前上熱搜,指向的都是ChatGPT厲害炸了。
而今成熱門,畫風早已大變——
圖靈獎得主楊立昆炮轟ChatGPT:五年內就沒人用了
馬斯克爲了不再被ChatGPT白嫖,決定給 Twitter「上鎖」
ChatGPT涼了?6月訪問量環比下滑近10%
OpenAI遭集體訴訟,明星大模型變「數據小偷」?
已經有媒體开始很嚴肅地討論:GPT,是吹起來的泡沫嗎??
01
之前看GPT-4像喬峰,武功蓋世。
現在看GPT-4像慕容復,浪得虛名。
這似乎又是個「初看是王者,再看是青銅」的故事腳本。
問題來了:現有的大模型天花板GPT-4,已經不香了嗎?
看上去,確實是這樣。
就在上個月,「GPT-4變笨」的話題,一度在國外技術社區內引發熱議。
有用戶反饋,把GPT-4的3小時25條對話額度一口氣用完了,都沒能解決自己的代碼問題,無奈切換到ChatGPT基於的GPT-3.5版本,反倒把事情解決了。
他反饋的主要問題包括:以前GPT-4能寫對的代碼,現在滿是Bug;回答問題的深度分析變少了,內容質量變差了。
這引起網友們的共鳴,「GPT-4开倒車」的說法由此興起。
不少網友都懷疑,GPT-4會像微軟必應那樣,出道即巔峰,但後來慘遭「前額葉切除」。
深度學習框架Keras創始人、網紅科學家François Chollet,爲GPT-4「自幹五」地洗道:
不是GPT的表現變差,而是大家渡過了最初的驚喜期,對它的期待變高了。
言下之意,是高期待值拉高了人們對GPT失誤的敏感度。
但OpenAI开發者推廣大使Logan Kilpatrick,倒是挺會自我拆台——
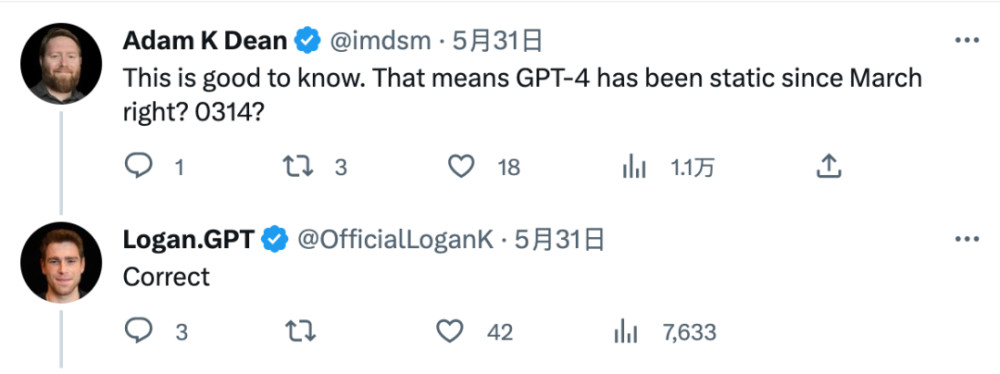
▲很顯然,OpenAI开發者推廣大使是個耿直Boy。
網友問他,GPT-4大模型本體自從3月14日發布以來都是靜態的,對吧?
他說,沒錯。
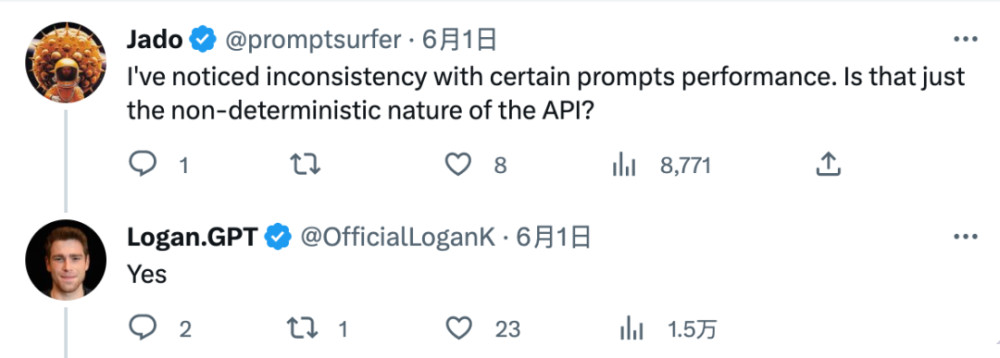
網友又問他,相同提示詞回答不一致,是因爲大模型本身不穩定嗎?
他又回答,Yes。
回答得這么坦誠,一看就是沒好好學習胡錫進的講話藝術:近期網上出現了××,老羅也看到××,知道大家很××,老羅忍不住囉嗦幾句,雖然××確實存在××,但是××……
02
GPT-4變「弱」了,國內科技大佬的「大模型自信」也就變強了。
幾個月前,國內外AI大模型存在代差,幾乎是共識,歧異只在於差距到底有多大。
今年3月25日,周鴻禕曾表示,中國大語言模型和GPT-4差距在兩三年。
5月上旬,周鴻禕跟俞敏洪對談,談到ChatGPT問題時說,「如果不經過兩年的模仿和抄襲,上來就說自己能超越,那才叫吹牛呢。」
幾天後,做客央視節目時又說:GPT-4有強大的思維鏈模型,能夠把一個事情做連續多步推理,能夠把一個目標做多任務的分解和規劃。如果要跟這種能力去比,國內大模型引擎跟它比都是六七十分的水平,差距可能是兩年,「如果有人說差兩個月、差兩周我可能不太相信」。
華爲原副總裁張俊對此大概頗爲認同,他5月下旬受訪時也說,國內外AI大模型存在約兩年的代差。
而李彥宏被王小川懟,也是因爲他3月下旬接受專訪時提了一嘴「文心一言和 ChatGPT 的水平差了2個月,但可以追趕」。
在王小川看來,這屬於自我吹噓,「怎么可能只差2個月?」「之前如果說追上GPT-3.5用一年還是有可能的,但是目前OpenAI已經訓練到GPT-4的級別,GPT-5也在訓練過程當中,我們追上還需要三年。」
就連李彥宏事後都給自己找補,說自己是被斷章取義了。

▲李彥宏稱「文心一言和ChatGPT的水平差了2個月」後,被王小川懟了。
彼時的共識就是:AI大模型的進化是非线性的,其正向增強回路的特點會強化「強者愈強」的頭部效應,外加語料庫質量差異,國內外AI大模型很可能會越拉越大。
但近段時間,某些大佬的口徑在變。
科大訊飛董事長劉慶峰就很自信。在5月6日的訊飛星火認知大模型發布會上,劉慶峰表示,當前訊飛星火認知大模型已經在文本生成、知識問答、數學能力三大能力上已超ChatGPT。
他還揚言:10月24日,將實現通用模型對標ChatGPT,中文超越ChatGPT的當前版本,英文能做到相當水平。
周鴻禕也不遑多讓:6月8日,跟品玩創始人駱軼航對話時,他說,最近幾個月國內同行陸陸續續發布了自己的大模型,雖然客觀來講跟GPT4.0還有點差距,相比GPT3.5也有點差距,但差距沒有那么大。
在5天後的360智腦大模型發布會上,他更是表示,國內大模型已基本趕上或接近國際先進水平,之前曾說和全球先進的差距有一兩年,今天收回這句話。
中國工程院院士鄔賀銓在6月下旬接受採訪時也說,評價大模型水平應該是多維度的,全面性、合理性、使用便捷性、響應速度、成本、能效等,籠統地說目前我國大模型开發與國外的差距爲1—2年的依據還不清楚,現在下這一結論意義也不大。
他還指出,按2022年年底的數據,美國佔全球算力36%,中國佔31%,現有算力總規模與美國相比有差距但不大,而以GPU和NPU爲主的智能算力規模中,中國明顯高於美國(按2021年年底數據,美國智算規模佔全球智算總規模15%,中國則是佔到26%)。
03
所以,GPT-4是被吹得太狠了嗎?
這兩天的兩則新聞,或許挺適合對此作答:
阿裏達摩院多語言NLP團隊日前發布了首個多語言多模態測試基准 M3Exam,共涵蓋 12317 道題目,結果顯示,多語言能力上,GPT-4是唯一一個可以超過60%准確率的模型, 其他的均不及格。
麻省理工學院和微軟的學者近來的研究也發現,GPT-4在自修復方面表現出了有效能力,GPT-3.5則沒有。在此之外,GPT-4還能夠對GPT-3.5生成的代碼提供反饋。
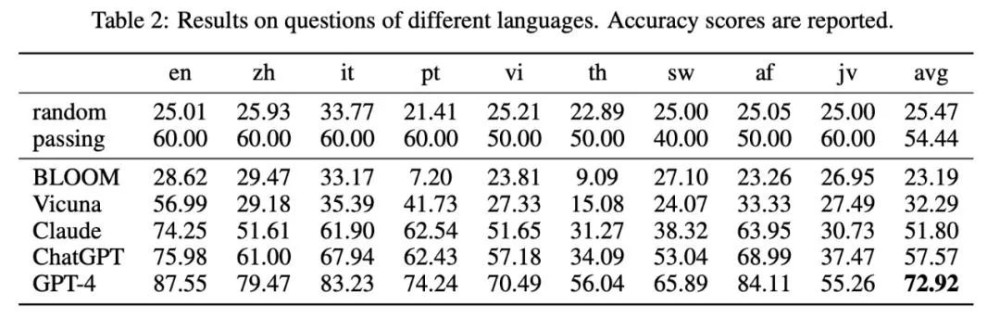
▲阿裏達摩院的測試中,GPT-4在多語言能力上仍是最秀的那一個。
那爲什么很多人感覺GPT-4能力退化了?
微軟研究院早前刷屏的那篇論文《AGI的火花:GPT-4早期試驗》中的說法,興許可資參考:
微軟方面獲得的GPT-4版本性能,要遠強於目前的公測版本。公測版本變弱,是因爲它要對標人類的指令和價值觀。
說大白話就是:OpenAI也怕出安全問題,所以「寧可變慢一點,也要安全一些」。
有人會說:不重要了,沒看到人家訪問量正在下滑嗎?
訪問量下滑,確實是不少人評價ChatGPT們「漲不動了」「也不行了」的重要依據。
乍看起來,這不乏數據支撐:多家數據分析網站指出,ChatGPT的訪問量環比增長率已從1月份的131.6%、2月份的62.5%、3月份的55.8%、4月份的12.6%,跌到了5月份的2.8%,6月份或環比下降。
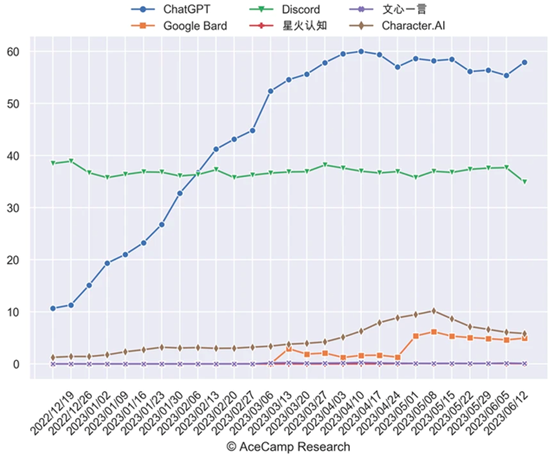
▲統計顯示,ChatGPT的訪問量增速出現回落態勢。
OpenAI麾下的ChatGPT和GPT-4告別流量高增長時代,大概率是事實。
但別忘了幾點潛在背景:
1,OpenAI未必在乎C端用戶直接訪問官網的流量,因爲它不想跟B端客戶搶用戶。
OpenAI的CEO阿爾特曼就曾表示,ChatGPT未來的核心战略使命,是吸引更多的企業應用程序接入API,而非在C端,與自己的企業客戶爭奪流量。
OpenAI從3月初开始,就在降價token的費用,借此鼓勵更多第三方开發者(很多都是B端客戶)使用ChatGPT和Whisper工具,通過API接口整合接入他們的服務。
現實中,很多人訪問的都是那些應用插件,而不是OpenAI官網。這難免對ChatGPT和GPT-4造成分流,但那些統計工具並未顧及這層因素。
2,4月初ChatGPT曾出現大面積封號,主要針對「特制工具」批量注冊的黑账號。
來自東方的神祕力量們憑着VPN和黑科技貢獻的流量,就被切掉了。
所以,你說它的流量下滑沒毛病,但這未必是OpenAI最在意的。
04
不論是GPT-4貌似沒那么「靈」了,還是ChatGPT和GPT-4訪問量下滑了,都指向了一點:
大模型的正確打开方式,與其說是做流量入口,不如說是深入行業場景,做行業數字化的AI底座。
從網絡反饋看,反映GPT-4變笨了的,主要都是些細分行業從業者。他們想要的業務知識,確實是那些基礎性、普適型的公用大模型給不了的。
OpenAI要把自身從C端爆火的超級AI應用,變成並不性感的API接口服務平台,說白了,就是想將價值做深,而不是只賺流量錢。
爲什么阿裏雲的通義千問今年4月發布後,想要通過「夥伴計劃」撬動更多企業在再訓練和精調基礎上打造企業的專屬大模型?
爲什么周鴻禕說「公有大模型在落地政府、城市、行業和企業場景時並不能直接使用,存在着缺乏行業深度、易帶來數據安全隱患、無法保障內容真正可信及無法實現成本可控四大痛點」,企業級垂直大模型才是未來?
爲什么騰訊雲6月19日不是直接發布基礎的通用大模型,而是發布面向 B 端客戶的 MaaS(模型即服務)服務解決方案,幫金融、政府、文旅、傳媒、教育等行業打造契合自身業務需要的「專屬模型」?
原因就在於:AI大模型是工業革命級的生產力工具,最終得服務於生產效率提升,是以還得將B端作爲切入口。
唯有如此,才能在AI時代「把所有行業重做一遍」。
前些天,傅盛PK朱嘯虎,圍繞ChatGPT激辯,核心也在於類ChatGPT產品的價值點开掘上。
▲傅盛跟朱嘯虎前不久在朋友圈激辯大模型創業。
作爲創投圈話題人物的朱嘯虎,認爲ChatGPT對創業者不友好,只有大廠商才玩得轉大模型,大模型都是在大模型上做應用又沒什么價值,完全沒有BAT級機會。
曾跟周鴻禕、雷軍、馬化騰、馬雲等一衆大佬相愛相殺的獵豹創始人傅盛,則認爲大模型催生了很多新的架構在大模型之上的創業機會,包括直接在大模型上搭建的不同應用和由於數據私有帶來的垂直領域大模型等。
可以這么理解:朱嘯虎認爲,創業公司們很難復制OpenAI,壓根就沒做通用AI時代的Windows或安卓系統的機會。
傅盛則不以爲然,認爲做AI時代的美團滴滴也挺好——美團滴滴們不就是靠拿捏住落地場景做大的嗎?
05
說回GPT-4,再怎么說它變弱了,它依舊是霸榜級別的存在。
打個不甚恰當的比方,GPT-4就是大模型版NBA裏巔峰期還沒過去的詹姆斯,它身後的Bard、LLaMA、文心一言、通義千問等,就相當於字母哥、杜蘭特、庫裏、約基奇,仍在追趕。
詹姆斯未必是「永遠的神」(華語樂壇這么多年了「永遠的神」也只有華晨宇一個),但在其鼎盛期,他的實力是獨一檔。
至於OpenAI的GPT以後會不會走下坡路,就難以料定了。
就目前看,中國大模型的追趕之路仍然道阻且長。
特別是考慮到美國預計7月份針對對華芯片出口實施新管制,連英偉達爲中國特供的A100平替版GPU芯片A800都要禁,加速追趕正迎來更多高難度挑战。

▲英偉達爲中國特供的A800GPU芯片,也在美國新一輪出口管制的射程內。
但不能說中國大模型就沒機會。中國互聯網過去20年能彎道超車,成爲全球Top2的玩家,超大市場提供的海量應用場景就是個重要因素。
中國消費互聯網規模能做成全球第一,就得益於互聯網平台們抓住了應用場景裏蕴藏的機會,進而不斷做大。
到了大模型時代,國產大模型很難再做出ChatGPT那種一問世就舉世矚目的大模型產品了,畢竟喝頭啖湯有身位優勢。
可它們能不能立足於應用場景,在助益實體產業中發掘出更多「平台級」機會來,還挺值得觀察。
能,就會得到市場的犒賞。
說到底,GPT-4有沒有從北喬峰變南慕容,固然挺有說頭。
但反求諸己,更重要的,還是練好「適合自身體質」的武功祕笈。
不然的話,連進AI江湖「五絕」的機會都沒。
?作者 | 佘宗明
?運營 | 李玩
?
原文標題 : GPT-4,從北喬峰變南慕容?
標題:GPT-4,從北喬峰變南慕容?
地址:https://www.utechfun.com/post/234280.html