毫無疑問,當前的科技圈已進入“大模型”時代。含“模”量大到什么程度?但凡科技企業,基本都在做“大模型”。
“從去年12月ChatGPT(Chat Generative Pre-trained Transformer)引爆科技圈之後,幾乎所有行業玩家都想抓住這根救命稻草。因爲做成了就意味着抓住未來幾十年的趨勢。”行業創業者夏先生對壹DU財經說道:“ChatGPT是生成式AI,是大模型的落地場景之一。理論上講,這條路的走通,加速了大模型在短期內的爆發。”

的確,ChatGPT的爆發,讓更多人看到了語言模型的魅力。微軟、谷歌、百度、阿裏等
國內外科技巨頭快速響應,相繼推出自家的AI聊天機器人,試圖以To C作爲切入口,搶佔市場。
風口在哪裏,資金和人才就在哪裏。隨後,先是廠商陸續宣布推出大模型,如百度的文心大模型、阿裏的通義大模型、騰訊的行業大模型,後有科技圈曾經的風雲人物也开始陸續入場,李开復、王小川、周伯文、王慧文等。出行、認知、辦公等一些垂直領域的大模型也相繼推出。
半年時間,國內呈現出“群模亂舞”盛況。而在經歷喧囂後,大模型或許是時候回歸現實了。
玩家們开始意識到,最初的熱鬧僅僅是熱鬧,他們最終的战場在B端市場。此時,多家有着人工智能積累和雲計算大廠登台,相繼推出了AI大模型服務。
行業老炮和新手創業者的對決,也就此开始了。
01
熱情高漲,玩家們跑步入場
進入2023年,大模型技術讓科技圈沸騰起來。看到ChatGPT爆發後,不少大廠抓緊時間推出相應產品,新老創業者們着急招兵买馬,生怕慢一步就錯過了這難得的風口。一級市場關於大模型的投融資熱度也在攀升,不少FA开始瘋狂補課。
一時間,整個行業熱鬧非常。
在OpenAI發布GPT4大模型後,第一個採取行動的是百度,在3月16日用“Demo演示”的形式正式發布文心一言。同樣在3月,已經沉寂許多的周鴻禕推出大模型產品,甚至連名字都沒來得及取。

在此之後,科技巨頭、創業公司和高校研究院們展开了一場關於“大模型”的競速賽。整個4月,都成了“大模型的發布月”,華爲、商湯、阿裏都在4月份亮出了自己的大模型產品。
到了5月,訊飛推出了自己的星火大模型,並公布了大模型在自己優勢領域的諸多應用場景。
創業者們也在火速入場。原美團聯合創始人王惠文(目前已退出)、創新工場CEO李开復、前京東AI掌門人周伯文、前阿裏技術副總裁賈揚清等开始招兵买馬。前搜狗CEO王小川的百川智能拿到5000萬美元融資後,甚至揚言:“今年年底做到國內最好的”。
“這波創業熱潮有點2000年左右的互聯網創業潮的意思。”一位業內人士說道:“似乎每個創業者都想在這個時代找到第二春。”
總體來看,今年上半年,大模型幾乎成爲所有科技企業的必選項。對於普通人而言,大模型或許是件很遙遠的事。畢竟不是每次科技浪潮都能成功靠岸,如元宇宙、XR等行業。
但事實上,大模型的應用更多在B端市場。那么,在行業烈火烹油過後,擺在這些玩家眼前的,理應是他們對市場更多的理性思考。比如市場是否真的需要大模型?大模型真正走向成熟,需要越過哪些重要關卡?能否真正意義上實現商業化。
02
“軍備賽”开打
大模型軍備賽的衝鋒號吹響後,整個行業开始“卷”起來。更多玩家已經將視线移至應用層面。因爲行業“退燒”後,最終考驗的還是玩家們的“硬實力”。
此時,一些在人工智能、雲計算上有積累的玩家則佔據的先發優勢。尤其是模型的參數量。
就目前市場上發布的AI模型來看,雖然大家都自稱爲“大模型“,但參數量實質是大模型和小模型的界定因素之一。
此前,百度集團副總裁侯震宇在接受媒體採訪時曾表示,2022年,10億參數的模型就叫大模型。但到了眼下,千億參數以上才會出現“智能湧現”,才會形成泛化能力,才能在各個場景下具備通用能力。
何爲“智能湧現”?簡單地講,當模型規模、算力水平超過某個參數閾值後,AI效果將不再是隨機概率事件。比如初期語言大模型出現“圖不對文”“答非所問”等現象。
並且在通用領域,參數量越大,智能通常湧現的可能性就越大,AI准確率就越高。在垂直領域則更容易獲得精確的效果。
今年5月,科技部下屬的中國科學技術信息研究所發布的《中國人工智能大模型地圖研究報告》統計,截至5月28日,國內10億級參數規模以上基礎大模型至少已發布79個。
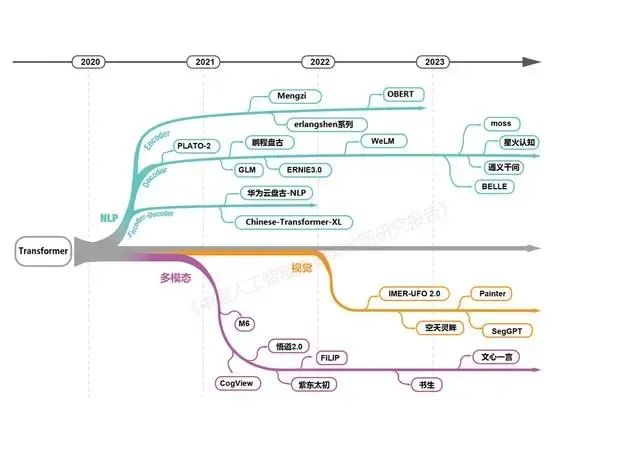
但可以看到,10億級參數這個量級,很可能不是真正的“分界线”。因爲現實的情況是,一些未能達到千億規模的模型,很難在當前市場的競爭具有競爭力。不過,也不排除一些在垂直領域深耕的玩家,最終能跑出來。
“大模型需要算力、算法和數據積累,絕對不是玩概念的事情,最終還是要市場买單。”夏先生認爲,目前來看諸如百度、騰訊、阿裏無論是在資源還是積累上,都有一定的優勢,“他們在雲市場深耕,並在自己擅長的領域積累多年,無論技術層面還是行業積累上,實質已經完成了搶跑,未來就看這些頭部玩家如何落地。”
而在投入層面,這會是一個天文數字。
以百度爲例。據透露,過去10年,百度在AI方向的投入已超過1000億元。但大模型不是投一筆錢、做一個模型那么簡單,它需要有算力、有數據、有經驗豐富的AI工程師在好的研發平台上長期積累。
而創業公司如果直接去做基礎大模型,除了上述投入之外,還需要能夠把模型、算力管理好的AI开發平台。
這意味着,創業公司不論是自建开發平台,還是採購外包平台,其投入都不會是小數目。並且,大模型不是預訓練出來就好,更需要後續持續敏捷迭代。從這一點看,創業公司所受的限制明顯要高於大公司。
但大廠很難留住強算法人才的弊端也比較突出,因爲大模型投入是一件長期主義的事,必定會面臨與既有業務之間的衝突。這一點,從大廠出走的大模型創業者的經歷,就說明了一點。長期主義對創業公司同樣重要,無論是創始人的背景背書,還是資源合作,抑或是客戶的拓展,都需要長期積澱。
03
行業競賽即將鳴槍
人工智能專家侯世達的學生梅拉妮·米歇爾《AI 3.0時代》一書中提到,研究人工智能與賽道中的創業者們都熟悉了一種模式——先是“人工智能的春天”,緊接着是過度的承諾和媒體炒作,接下來便是“人工智能的寒冬”。並且,他認爲這一模式將以五到十年爲周期不斷上演。
具體到2023年上半年的大模型賽道,顯然其正處於第二個階段——行業很火,市場很熱。這一周期往往是最短的,也通常意味着如此去泡沫化後,賽道競爭即將正式开始。
大模型比拼的不僅僅是技術,還應該將重點放在大模型應用、產業生態中去評估。
目前,市場上大模型的玩家主要分三類。
一是聚焦基礎層,主要對標OpenAI,發揮基礎設施的作用。
第二類是錨定中間層,不需要像OpenAI一樣花大錢做底層,只需要掌握通用化能力,就可以通過开源大模型做精調,讓模型具備差異化能力,最終可以形成垂直類模型。
第三類是調用大模型API的企業,專注开發大模型具體場景的應用,如Jasper。
相對而言,前兩類又是大模型的“基礎設施”,因爲有極高的門檻,對技術、資金以及資源有嚴格的准入壁壘,往往是大公司布局的主要方向。
目前來看,百度、阿裏和華爲在大模型的構建上,不約而同地採用了“模型+工具平台+生態”的三層共建模式。騰訊雲則更專注於應用層而,6月19日公布的騰訊雲MaaS服務解決方案即覆蓋了金融、文旅、政務、教育等10個行業、超50個解決方案。
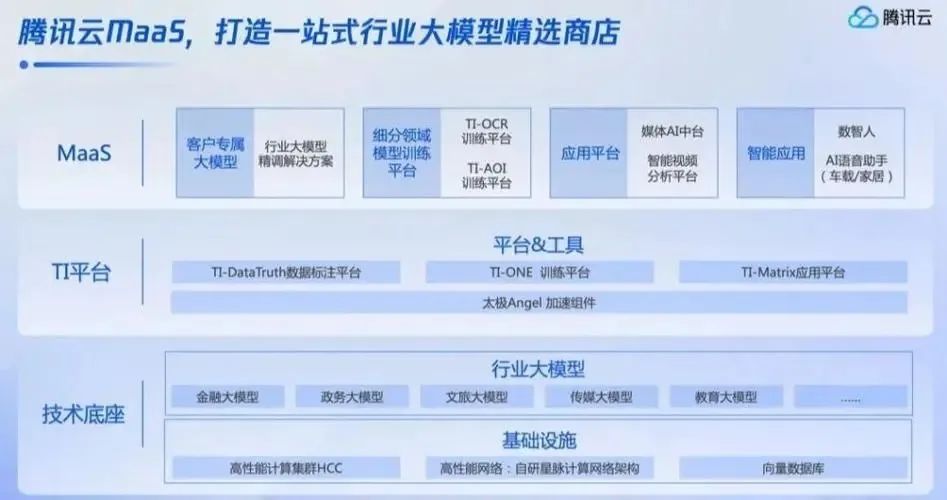
雖然巨頭們參與競爭的姿勢不同,但目標實質上只有一個,那就是打通應用層。在百度創始人李彥宏看來,應用層最具想象空間。
商湯科技聯合創始人楊帆認爲,AI 基礎設施本質上還是算力、數據、基礎算法,包括算法相關的工具,本質上還是三位一體的東西。最後誰能把這三者的整合能力提供的好,提供更低成本、更低門檻的能力是決定整個競爭最重要的點。
結語
AI大模型是人工智能邁向通用智能的裏程碑式技術,因爲其可爲各行各業的智能化升級提供強勁的生產力工具。在千行百業數字化轉型升級的當下,大模型的重要意義不言而喻。也因此,在當下,誰能率先在賽道裏搶到更多籌碼,就非常關鍵了。可以預料,未來,拋开“基礎設施”層面的較量外,真正的战場大概率是各行各業的切實落地上。
圖片來源於公开網絡,侵刪。
原文標題 : 大模型狂飆半年,“群模亂舞”誰能勝出
標題:大模型狂飆半年,“群模亂舞”誰能勝出
地址:https://www.utechfun.com/post/232810.html