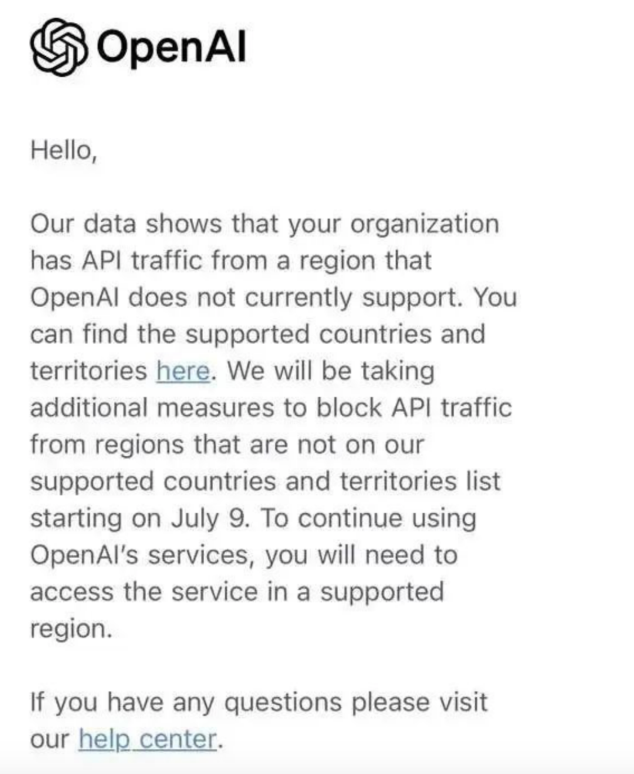
OpenAI在6月25日凌晨宣布,將從7月9日起,將阻止來自不支持其服務的國家和地區的API流量,而中國也在禁用名單之列。
消息一出,國產大模型們應聲而動,立刻推出了相應的“搬家”或“遷移”方案。有的還提出了與OpenAl 使用規模對等的 Token 贈送計劃(不設上限),坊間戲稱,“這下中國做AI的可以實現token自由了”。
我們知道,海外對於中國AI的限制一直存在。但此前針對AI的禁令,主要是限制英偉達和AMD的高性能AI算力卡,而OpenAI此次強勢禁用,則讓AI軟件算法層面的“另一只靴子落地”。
從硬件到軟件,越來越擴大的禁用範圍,以及越來越嚴格的限制,無時無刻不在提醒着我們,在AI這一關鍵科技領域,全方位阻隔中國的進步,已經是一張明牌了。
面對這個不可逆的AI封鎖大趨勢,中國企業受的影響到底有多大?AI全面國產化,中國做好准備了嗎?
放棄幻想:OpenAI禁用到底影響了誰?
自ChatGPT發布以來,OpenAI的API已向近190個國家和地區开放,其中並不包括中國。不過,一直以來,一些國內企業和用戶,可以通過技術手段來繼續使用OpenAI的服務。
對於這些來自中國的流量,OpenAI並非檢測不出,只是以前可能“槍口擡高了一寸”。
而就在6月22日,美國財政部發布了一份規則草案,進一步限制美國個人和企業投資中國的半導體、量子計算和人工智能業務。新規則草案推出,面對越來越明確的AI封鎖態勢,OpenAI也主動明哲保身,選擇了加強區域限制,採取額外措施阻止來自不受支持地區的API流量。
到底是什么人和公司“明知不可爲而爲之”,在使用OpenAI的API呢?主要有三類:
一是部分自研模廠。一部分模廠會在研發階段,調用OpenAI的API,使用其GPT產品進行模型訓練、數據對比迭代等。實際上,谷歌Gemini-Pro大模型的訓練也曾用到了百度文心生成的數據。此前就有國內某互聯網公司,被爆出經常達到OpenAI API的最大訪問上限,不過對方也表示,僅在年初的初期探索階段使用了OpenAI的API,而在今年4月已經停止了這種做法。
二是套殼AI公司。一些初創公司爲了快速推出AI產品或服務,可以通過技術手段,對OpenAI的API進行封裝,“改頭換面”作爲自己的產品推向市場。實際上用戶的每次交互,都會通過API調用OpenAI的模型來完成。
三是面向海外市場的應用开發者。在OpenAI所支持的國家和地區,爲了跟海外开發者“站在同一起跑线”,而選擇OpenAI API。
目前來看,上述群體受OpenAI禁令的影響程度都不高。
隨着國內模廠的模型基本完善,不用再通過調用API的方式收集數據。海外應用的开發,應用往往需要對本地市場的深入了解,因此國內开發者數量規模也較小。相比之下,“套殼API”的初創公司可能受到的打擊是最大的,不過通過“搬家”切換到國產大模型,快速找到能力接近的替代方案,也能一定程度上規避風險。

所以總體來說,OpenAI更嚴格的API限制,並不會給中國AI帶來很大的動蕩。
但這並不意味着,中國AI可以高枕無憂了。從“英偉達禁令”到“OpenAI禁令”,發出了一個鮮明的信號:“潘多拉魔盒”一旦开啓,就不會關上,針對中國AI的封鎖,也不可能在短時間內被撤回。
是時候摒棄“槍口擡高一寸”的僥幸心理和幻想了,事實證明,槍口隨時可以朝下扣動扳機。
認清現實:不可逆的AI封鎖,還有哪些牌可出?
在封鎖烈度上,美國官方和AI企業的行動在不斷加強;在封鎖廣度上,從高性能AI芯片的底層算力,到大模型的底層算法,“釜底抽薪式”的封鎖正逐漸延伸到AI基礎設施的各個關鍵部分。
那么,在算力禁運、算法禁用之後,海外想要阻隔中國AI的發展,還有哪些牌可以打?梳理一下AI軟件基礎設施:
- 框架。深度學習框架,是支持AI算法模型开發和部署的軟件平台,對AI應用的开發效率和性能有重要影響。目前國內深度學習框架市場主要由飛槳(由百度开發)、TensorFlow(由Google开發)、PyTorch(由Meta开發)三家主導,共同佔據了超過80%的市場份額。這三家均爲开源框架,允許开發者自由地查看、修改和使用其源代碼,不過TensorFlow、PyTorch作爲开源平台也需要遵守所在國法律法規,並可以通過开源許可證等方式,限制开發者的訪問。

2.算子庫。包含各種數學和邏輯運算函數的庫,在深度學習框架中扮演着至關重要的角色,爲各種算法提供了基礎的計算單元。如果算子庫是閉源的,又歸屬於海外公司,那么可以直接限制使用。开源的算子庫也要遵循一定的开源協議,協議中往往會規定代碼的使用、修改和分發規則,如果开發者沒有獲得適當的許可或權限,也無法使用。目前,國內飛槳、昇思等AI开發平台都發布了算子庫。
3.數據集。AI界有句名言“garbage in,garbage out(垃圾進,垃圾出)”,高質量的數據集,對於AI算法模型的性能至關重要,在大模型時代也不例外。各個領域和應用場景都有專有數據集,比如計算機視覺領域的MNIST、CIFAR、ImageNet等。NLP領域的SQuAD、GLUE等,再比如AI蛋白質結構預測任務所需要的數據集,如CASP、AlphaFold DB、PDB等,這些數據集爲AI研究提供了豐富的數據資源,大多由海外研究機構建立。
近年來,中國AI領域的高質量數據集也在快馬加鞭地建設,數據治理體系也在不斷完善,數據作爲核心生產要素的战略地位不斷提升。但現階段,與海外一流水平還有差距。而AI算法的特別之處在於,不像傳統軟件能一次开發完成,模型需要不斷學習、迭代和進化,依賴於持續更新的數據集進行訓練。一旦數據集被阻止訪問,就如同剝奪了模型成長的土壤,甚至可能變得停滯不前。
此外還有編譯器、IDE等,這些軟件工具可以大大提高开發者的編程效率。如果被禁用,开發者將需要手動完成這些工作,從而導致开發效率降低,團隊協作困難,甚至影響項目的進度和質量。

“英偉達禁令”執行以後,一位國內某計算廠商向腦極體表示,“雖然我們還可以用特供版的AI芯片,但確實支持不了英偉達最新的平台了”。
所以說,硬件、軟件基礎設施共同構成了AI產業的支撐體系。面對阻隔中國AI的封鎖禁令,一定要有“底线思維”,軟件並不比硬件更安全,开源軟件並不比閉源軟件更安全。
准備應對:中國AI,必須兩條腿走路
提到國產化替代,總有人擔憂這是在閉門造車、與世界脫節。AI作爲高度全球化的高新技術產業,這種擔憂確實不無道理。
但也必須看到,“沒有一次AI斷鏈是我們先動的手”。
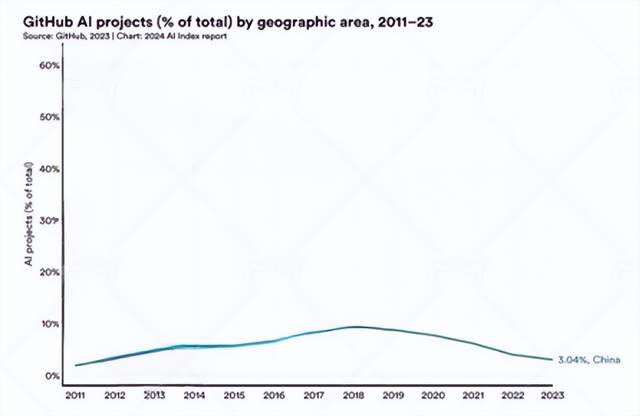
實際上,中國AI產學界始終保持着开放心態,積極吸收國際先進技術,與世界接軌。斯坦福大學發布的《2024 年人工智能指數報告》顯示,自2011年以來,GitHub上的开源人工智能項目,中國參與度不斷增長,直到2019年在科技領域遭受不合理打壓之後,才开始走低。
無論是芯片禁運,還是API禁用,都是海外以“國家安全”“保證美國AI領先地位”等理由,發起的單方面阻隔。而在短時間內,這種單方面動手的“AI封鎖”,並不會告一段落。
這種情況下,中國AI將面臨一個重要抉擇:是徹底國產化替代,底層軟硬件全用自己的?還是繼續參與全球AI大市場,更多利用國外技術?
小孩子才做選擇,成年人全都要。中國AI,必須學會“兩條腿走路”。
第一條腿,是基礎軟硬件的自主創新,做好全棧AI技術國產化的准備。
中國AI在底層軟硬件的關鍵“卡脖子”環節,都積累了不少力量。以軟件爲例,百度、華爲雲等頭部大模型廠商,都建立了“AI大底座”,從底層算力(百度昆侖、華爲昇騰)、基礎模型(文心、盤古)、深度學習框架(飛槳、昇思)、全棧AI开發工具平台(千帆平台、昇騰AI雲服務)等。
這些全棧自研的AI軟硬件基礎設施,可以讓中國AI做好“最壞的准備”,無懼來自海外的斷鏈風險。
但正如經濟學家江小涓所說的,在當今科技全球化、產業全球化的格局下,“會做的全部自己做”並不是最優選項。

所以中國AI的第二條腿,是保持與全球最新趨勢的緊密聯系,確保信息通暢、創新同步。
還記得芯片禁運之時,有網友義憤填膺地表示要“對等制裁”“不用也沒有損失”,但一位資深從業者卻說“別人小心眼,我們自己不能小心眼”。美國封閉但我們不能封閉,不能自己把路走窄了。
緊密貼近全球趨勢、充分利用全球資源,是中國AI保持領先的必要條件。一方面,吸收全球最先進的技術,中國AI可以在更高的起點上推動技術自主創新,避免產業鏈割裂帶來方向迷失,錯過主流的AI發展機會。
另一方面,中國AI是科技競賽中排名全球前列的一個領域,這種領先優勢十分關鍵,且不容失去,必須與全球創新保持同步,因此要積極擁抱國際市場和科技合作。
隨着國產算力的突破,“英偉達禁令”不再讓AI算力束手無策,就在大家覺得中國AI穩了的時候,OpenAI的禁令猶如一道閃電,劃破了中國AI界對“限AI=限卡”的幻想。
國產算力固然是底氣所在,但絕非高枕無憂的保證,來自OpenAI的API限制說明,海外AI軟件也並不完全可靠,同理,开源軟件也並非絕對安全的屏障。

AI產業鏈封鎖,如同懸在頭頂的達摩克利斯之劍。但換個角度看,逐漸加碼的禁令,恰恰是之前的措施勞而無功,沒能起到徹底阻攔中國AI進步的效果,這也間接反映出中國AI產業的生存活力,是不會輕易被阻隔在世界之外的。
中國AI,唯有認清現實,把一張張產業鏈王牌都握在自己手心裏,才能繼續留在全球大市場的牌桌上。
原文標題 : OpenAI刺破了中國AI的幻想
標題:OpenAI刺破了中國AI的幻想
地址:https://www.utechfun.com/post/390598.html