
過去半年,AI 生成視頻一直處在斷斷續續推進的狀態。在 OpenAI 年初推出 Sora 時引發空前討論之後,號稱國內首個自研視頻大模型的 Vidu,以及後續字節、騰訊、快手等多家國產廠商推出視頻生成模型,都在時不時引發外界的關注。就在前幾天,雷科技還對快手的視頻大模型「可靈」進行了內測體驗。
不過,這兩天 AI 生成視頻確實又火了。
一發布就火,「造夢機器」燒遍社交網絡
6 月 12 日,初創公司 Luma AI 發布了新的 AI 視頻生成模型 Dream Machine(造夢機器),並且面向公衆开放測試。很快,不僅官方放出的一系列樣片,社交網絡上還出現了一大堆由網友通過「造夢機器」生成的視頻。
比如現代風格的樣片,它在少女和貓的呈現效果上水准相當高,尤其是貓的頭部和眼部動作。

圖片經過壓縮,圖/ Luma AI
還有奇幻風格的,生成的人物或者物體也確實奇幻,甚至有些克蘇魯的味道。

圖片經過壓縮、剪輯,圖/ Luma AI
此外,「造夢機器」不僅支持通過文本生成視頻,也支持基於圖片和文本生成視頻,所以你還能看到從《戴珍珠耳環的少女》中跳出的少女,還有房地產中介可能會喜歡的「如何讓景觀圖變成景觀視頻」。
甚至,有人已經开始利用「造夢機器」創造一個講述「一日生活」的影像故事,包括美國中學生從早起到上學再到舞會的刻畫。
不只是用戶玩得开,海外和國內媒體也都注意到了「造夢機器」的熱度。不過有一說一,有些國內媒體明顯吹過了頭,什么超越 Sora、比 Sora 更真實流暢,這些我們先稍後再談,但「造夢機器」哪來的支持 120 秒生成視頻?
事實上,「造夢機器」只支持生成 5 秒的視頻,官網說的是生成視頻需要 120 秒,排隊等待的時間另說。而如果單獨打开官網上的樣片,也會發現一律都是 5 秒(除非有剪輯)。

圖/ Luma AI
這個視頻時長,比起國產視頻大模型 Vidu 的 16 秒(最近又宣稱延長到了 32 秒的有聲視頻)就不用說了,更何況是將 AI 生成視頻時長突破到 60 秒的 Sora。
按照 OpenAI 官方公布的信息,Sora 能夠實現視頻時長突破,主要功臣是其所採用的擴散 Transformer 架構,在 Diffusion 擴散模型的基礎上將 U-Net 架構替換成了 Transformer 架構。
「造夢機器」呢?目前 Luma AI 公司並未透露具體的情況。
當然,5 秒的視頻時長你也不能說太短,因爲目前大量的視頻生成模型也只能生成 5 秒的視頻,包括宣稱可以生成最長 2 分鐘的快手可靈,至少目前也只能生成 5 秒的視頻。而且我們也不能只看「視頻時長」一個維度,還得看畫面的可用性以及使用潛力。
表現驚豔,但內容可靠嗎?
坦率地講,「造夢機器」給小雷的第一印象還是挺驚豔的,首先感受下官方放出的樣片。

圖片經過壓縮,圖/ Luma AI
比如這段中,在一個氛圍透露着危險的房間,一個持槍的男子小心翼翼地前進。
除了人物主體和背景的一致性,最讓人驚訝的可能是光照的變化。不僅是手槍上明顯的光线反射,在男子臉上,也可以看到原本詭譎的紅光在人物移動過程中,色溫逐漸由暖轉冷,並與鄰近光源趨同,包括亮度的變化也符合基本的物理規律。
還有一段是在一間廢棄的房屋中發生了爆炸,鏡頭由遠及近。雖然還是會出現憑空固定的白色棒狀物,但在鏡頭移動的過程,不管是家具的不變,還是氣流變化引起的紙屑亂飛,都稱得上符合直覺。
另外「造夢機器」也展現了作爲動畫創作工具的潛力,比如在一段視頻中,鏡頭從角色正面轉向背面,已經很接近動畫創作中的特寫鏡頭。

圖片經過壓縮,圖/ Luma AI
但是,這些終究還是官方「嚴選」出來的。不管是文字、圖片還是視頻生成模型,官方 Demo 肯定會經過精挑細選找出相對較好的,這一點大家都能理解,但從普通用戶的角度,很容易代入誤以爲是模型的平均水平。
在實際網友創作和分享的內容中,即便是在那些相當驚豔的少數作品中,你也能看到或多或少的錯誤。
比如@minchoi 用「造夢機器」創作的美少女視頻,好幾段都完全媲美真人實拍。
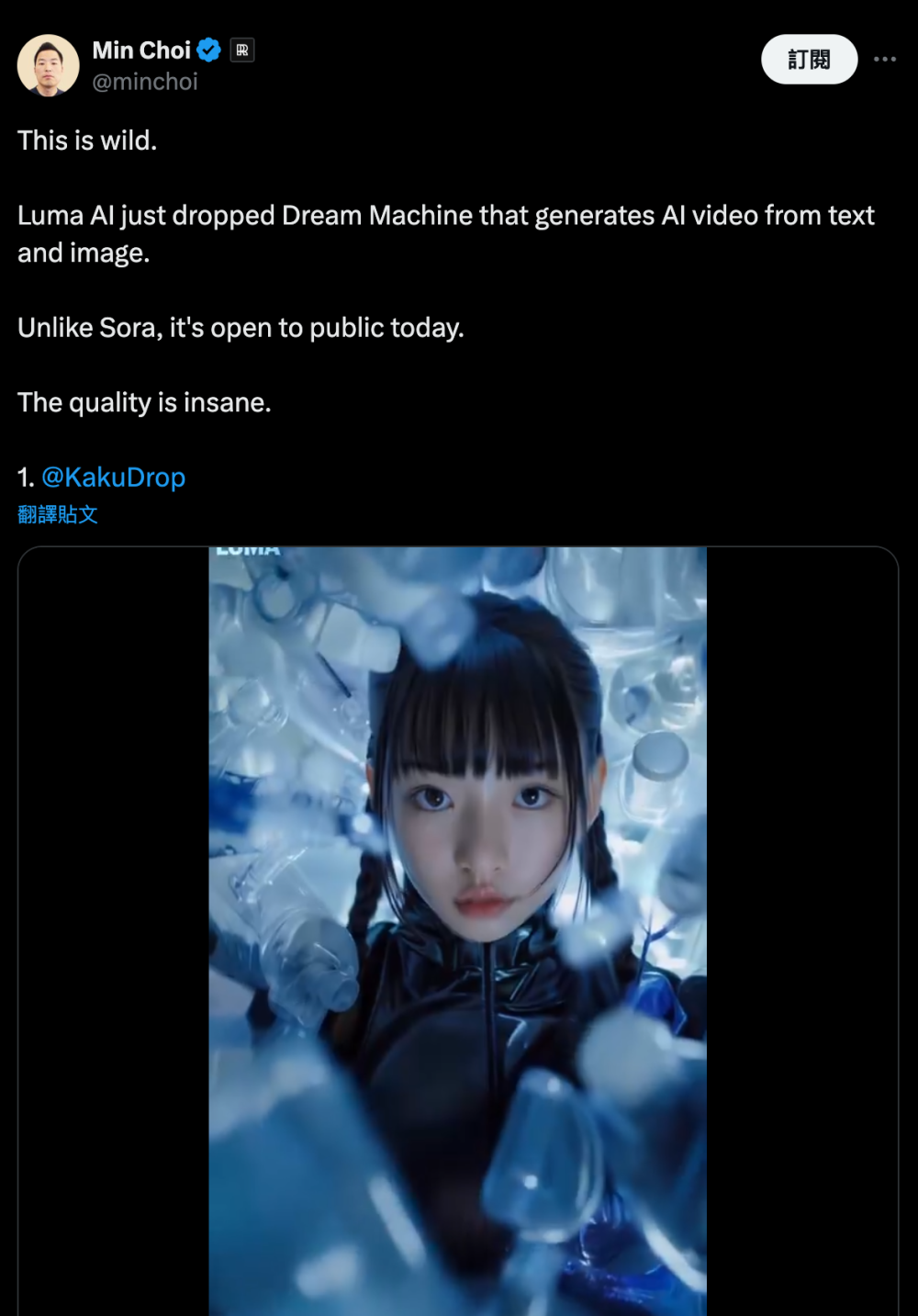
圖/ X
不過,人物的手還是存在渲染問題,而且人物的形態還是會有一定的變化,在前面提到的《戴珍珠耳環的少女》視頻中更加明顯。

圖片經過壓縮,圖/ Luma AI
另外,一致性的問題還體現在風格上,有的明明是 2D 動畫風格,慢慢就开始往 3D 動畫的風格轉。

圖片經過壓縮,圖/ Luma AI
小雷也試着用「造夢機器」創作了一段視頻,Prompt 是「A group of people walking down a street at night with umbrellas on the windows of stores.」實際效果還是比較糟糕的:人物詭異的倒退,在背後拿着傘的怪異舉動,還有飛起來的雨傘。
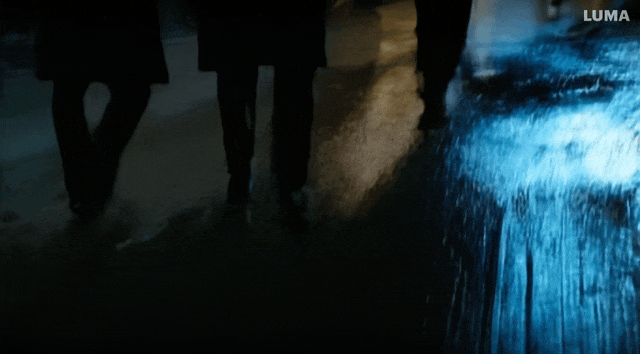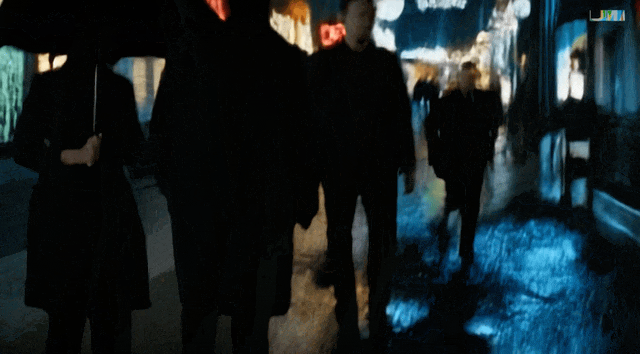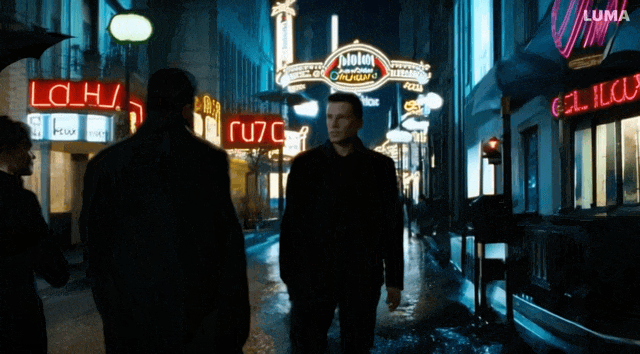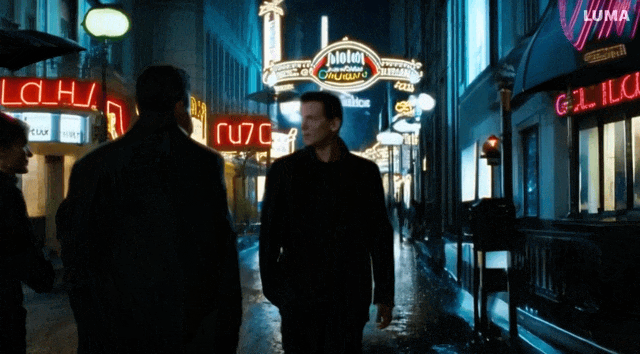
圖片經過壓縮,圖/ Luma AI
不過還是有一些優點的,比如路面的倒影,背景和人物的一致性。
即便如此,這些問題說到底還是沒有攔住廣大網友的創作熱情。畢竟相比 Sora,「造夢機器」至少公开可用,還有每個月 30 次的免費生成機會。而相比大部分可用的視頻生成模型,「造夢機器」在一致性也有明顯的進步。
而除了免費用戶,「造夢機器」目前還提供三檔付費選項,包括 29.99 美元的標准檔、99.99 美元的專業檔以及 499.99 美元的高級檔,區別是每個月可以生成視頻的次數。
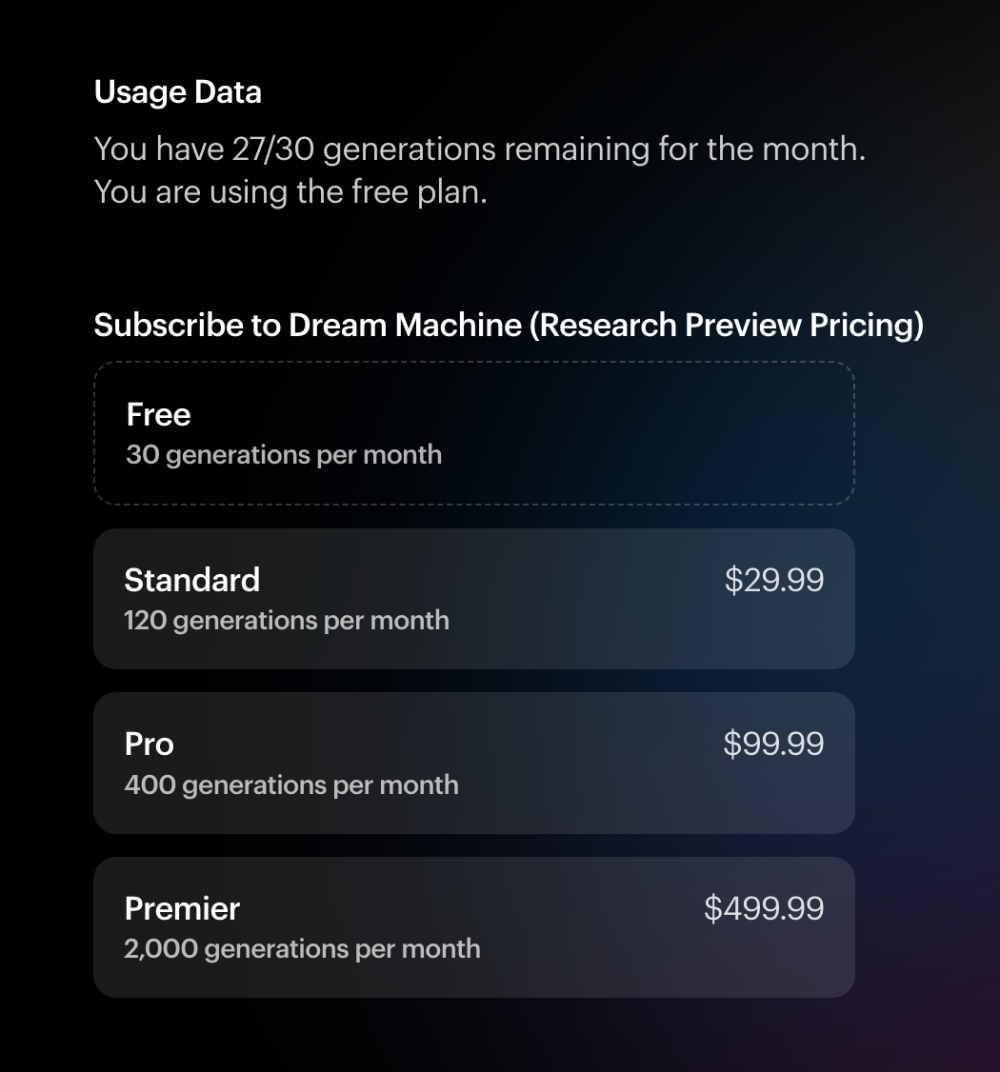
圖/ Luma AI
對於普通用戶來說,這些定價可能有些離譜,但對於那些开始通過「造夢機器」創作視頻在 TikTok 上賺錢的創作者來說,估計還在接受範圍內。
從 AI 畫圖到 AI 視頻,大模型再次混战
AI 視頻不是從「造夢機器」开始的,當然也不是從 Sora 开始的。事實上早在 2022 年,AI 繪畫已經开始驚豔世界的時候,AI 視頻就开始吸引大量的關注。
首先我們需要回到 2022 年那個時間點,彼時 ChatGPT 還在酝釀(年底才發布),在大衆眼中,AI 技術發展最快速的領域當屬 AI 繪畫。
2022 年 4 月,OpenAI 發布了新版本的文本生成圖像程序——DALL-E 2,一張由 DALL-E 2 生成的「宇航員在太空騎馬」圖片开始躥紅社交網絡,讓一衆畫師真正有了「失業」的擔憂。

圖/ OpenAI
包括之後的 Midjourney,它們在生成圖像方面相比之前的產品都有更高的分辨率和更低的延遲。Stable Diffusion 雖然起步最晚,憑借开源的優勢,在用戶關注度和使用範圍都超越了 Midjourney 和 DALL-E,在初期的進步也最明顯。
事實上,當時 AI 繪畫已經开始「侵入」社會的方方面面,不管是獲獎的《太空歌劇院》(Midjourney 生成),還是各大公司开始嘗試通過 AI 繪畫直接生成廣告、海報甚至內容作品。
圖片可以 AI 生成,視頻還會遠嗎?衆所周知,視頻本質上就是一幀一幀的圖片組成。所以在 2022 年,谷歌和 Meta 其實就开始了一場關於 AI 生成視頻的競爭,Meta 有 Make-A-Video,谷歌有 Imagen Video,二者都是通過文本直接生成視頻的視頻擴散模型,底層還是 AI 繪圖那一套。

圖/ Meta
當時,AI 生成視頻時長都不超過 5 秒,分辨率也很低,同時畫面變化很小,與其說視頻,更像是讓圖片「動一動」。更重要的是,谷歌和 Meta 受限於大公司的身份和慣性,都沒有選擇开放給用戶以及創作者使用,更多還是研究成果的展示,影響範圍也基本局限在圈內。
相比之下,Runway、Synthesia 以及 Pika 等 AI 視頻創業公司就顯得更加「靈活」。在去年發布的 Gen-2 上,Runway 不僅改進了視頻生成的質量,還增加了 Motion Slider(運動滑塊)、Camera Motion (相機運動)等功能,把更多視頻的控制權交給用戶。
去年火過一陣的 Pika 也是一款比較受關注的 AI 視頻生成工具,由於較高的畫面質量甚至一度被稱爲「視頻版 Midjourney」,同時相比 Runway Gen-2,Pika 爲了確保內容的可控性和擴展性,還更進一步給了創作者更多的控制權,比如可以精細到眼部和表情的規劃生成。
此後,包括 Stable Diffusion 以及 Midjourney 也都陸續推出了生成視頻的版本,讓 AI 生成視頻進入战國時代。但不管是哪一家,就 AI 生成視頻的畫面表現來看其實沒有太大的差異,更多是產品層面的差異。
直到 Sora 帶着 Transformer 架構出道即碾壓。
大語言模型,在改變 AI 視頻生成
Sora 引發的震撼和討論可謂有目共睹,甚至有人認爲 Sora 將是通往 AGI(通用人工智能)的快車道。Sora 是否能真正理解物理世界的運行規律,我們先放在一邊不談,但可以肯定的是,Sora 徹底改變了 AI 視頻生成技術的發展路线。

圖片經過壓縮、剪輯,圖/ OpenAI
Sora 最震撼的技術突破之一在於其輸出的視頻時長,當其他家普遍都只能生成數秒視頻的時候,Sora 就將時長突破了 60 秒。
事實上,包括最新發布的「造夢機器」也只能生成幾秒的視頻,一旦需要更長的視頻,第二次、第三次、第 N 次生成的視頻很容易出現變形,導致前後畫面差異過大,從而無法使用。
此外,AI 生成視頻還普遍存在基於時間的連貫性問題,但一段關於小狗的 Sora 生成視頻中,行人完全擋住畫面之後,小狗依然能保持住連貫性,主體也沒有發生明顯的變化。再有就是大家提過很多次的「模擬」,能夠很好地模擬符合物理世界規則的動作。
而 Sora 的這些優勢很大程度上來源於架構上的核心區別,所以在 Sora 之後,Transformer 架構與擴散模型相結合的全新技術路线很快受到了廣泛的關注,包括生數科技(聯合清華大學)Vidu、愛詩科技 PixVerse、快手可靈也都採取了這一路线。
從這個角度來看,雖然 Luma AI 沒有公开「造夢機器」採用的架構設計,但結合在生成視頻中表現的一致性和邏輯表現,很難相信「造夢機器」是在純擴散模型上的產物,大概率,也是借鑑了 Sora 將 Transformer 架構融入擴散模型的做法。
當然,這也只是一種猜測。但對 AI 視頻來說,這越來越成爲一種必然。
來源:雷科技
原文標題 : 視頻大模型“造夢機器”爆紅:瑕疵真不少,關鍵是能用!
標題:視頻大模型“造夢機器”爆紅:瑕疵真不少,關鍵是能用!
地址:https://www.utechfun.com/post/384492.html