來源:智東西

面壁智能回應:“深表遺憾”,這也是一種“受到國際團隊認可的方式”。
作者 | 程茜
編輯 | 心緣
智東西6月3日消息,大模型“套殼”的回旋鏢,這次扎到了美國科研團隊身上。最近幾天,斯坦福大學AI團隊陷入抄襲風波,被質疑“套殼”清華系大模型开源成果,引起輿論譁然。
起因是這個團隊在5月29日發布了一個多模態大模型Llama3-V,聲稱只花500美元訓練,就能實現在多個基准測試中比肩GPT-4的性能。但很快有人發現,該模型跟清華系大模型創企面壁智能5月發布的MiniCPM-Llama3-V 2.5模型有不少相似處,而且沒有任何相關致謝或引用。

一开始團隊面對抄襲質疑還嘴硬否認,只承認使用了MiniCPM-Llama3-V的分詞器,後來證據越來越多——不僅架構和代碼高度相似,而且被發現作者曾在Hugging Face導入MiniCPM-V的代碼,然後改名成Llama3-V。
最絕的是Llama3-V連國產AI模型的“胎記”都抄走了,跟MiniCPM-V一樣能識別清華战國竹簡“清華簡”,而且連出錯的樣例、在高斯擾動驗證後的正確和錯誤表現方面都高度相似。
而基於非公开訓練數據的清華簡識別能力,是面壁MiniCPM團隊耗時數月、從卷帙浩繁的清華簡中逐字掃描並逐一數據標注,融入模型中的。
面對鐵一般的證據,Llama3-V團隊終於立正挨打,一套道歉流程行雲流水,火速刪庫、發文致歉外加撇清關系。其中來自斯坦福計算機科學專業的兩位作者澄清說他們並未參與代碼工作,所有代碼都是畢業於南加州大學的Mustafa Aljadery負責的,他一直沒交出訓練代碼。

▲Llama3-V作者:Siddharth Sharma(左)、Aksh Garg(中)、Mustafa Aljadery(右)
這樣看來,Llama3-V團隊並不能算嚴格意義上的斯坦福團隊,不過因爲此事聲譽受損的斯坦福大學至今沒有採取任何公开措施。
面壁智能團隊的回應很有涵養。今日,面壁智能聯合創始人兼CEO李大海在朋友圈回應說“深表遺憾”,這也是一種“受到國際團隊認可的方式”,並呼籲大家共建开放、合作、有信任的社區環境。

01.
網友細數五大證據
作者刪庫跑路、不打自招
Llama3-V的模型代碼與MiniCPM-Llama3-V 2.5高度相似,同時其項目頁面沒有出現任何與MiniCPM-Llama3-V 2.5相關的聲明。
公开的基准測試結果顯示,Llama3-V在所有基准測試中優於GPT-3.5,在多個基准測試中優於GPT-4,且模型尺寸是GPT-4V的1/100,預訓練成本爲500美元。這也使得該模型一經就衝上Hugging Face首頁。
但當細心網友發現Llama3-V疑似“套殼”面壁智能此前發布的开源多模態模型MiniCPM-Llama3-V 2.5,在評論區提出質疑後,Llama3-V項目作者最初否認抄襲,並稱他們的項目开始時間先於MiniCPM-Llama3-V 2.5發布,只是使用了MiniCPM-Llama3-V 2.5的分詞器。
當網友拋出三大事實質疑後,Llama3-V的做法是——不回應直接刪除網友評論。
昨日下午,網友在MiniCPM-V頁面下將事情經過全部公开,並公开@面壁智能讓其項目團隊投訴。
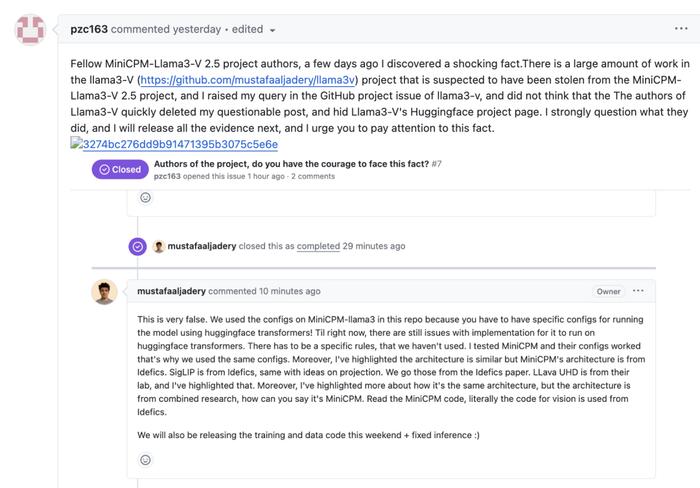
當日晚間,面壁智能研發人員發布推文,其驗證結果也印證了網友的說法,Llama3-V與MiniCPM-Llama3-V 2.5高度相似。同時公开喊話Llama3-V研發團隊:“鑑於這些結果,我們擔心很難用巧合來解釋這種不尋常的相似性。我們希望作者能夠對這個問題給出官方解釋,相信這對开源社區的共同利益很重要。”
以下就是Llama3-V被質疑抄襲MiniCPM-Llama3-V 2.5的五大證據:
1、Llama3-V的代碼是對MiniCPM-Llama3-V 2.5的重新格式化,其模型行爲檢查點的噪聲版本高度相似。
其中,Llama3-V只是對代碼進行了重新格式化和變量重命名,包括但不限於圖像切片、標記器、重採樣器和數據加載。面壁智能研發人員也證實,Llama3-V有點類似於MiniCPM-Llama3-V 2.5的噪聲版本。
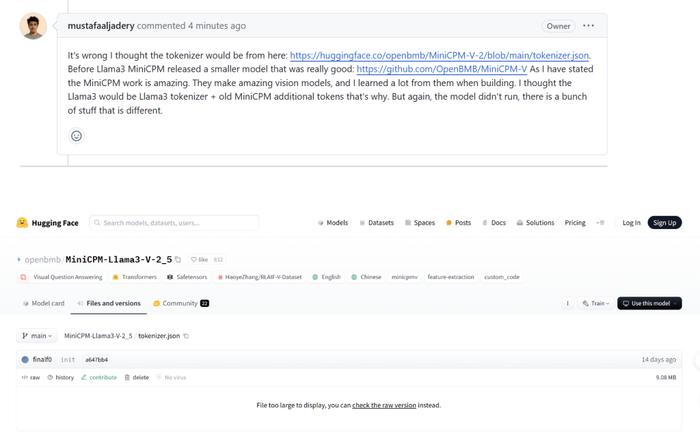
2、起初網友在Llama3-V的Hugging Face頁面質疑抄襲時,其作者回應稱只是使用了分詞器,並且項目开始時間比MiniCPM-Llama3-V 2.5更早。
當網友進一步詢問如何在MiniCPM-Llama3-V 2.5發布前使用其分詞器,作者給出的答案是使用了MiniCPM-V-2的分詞器,但很明顯,兩個版本的分詞器完全不同。
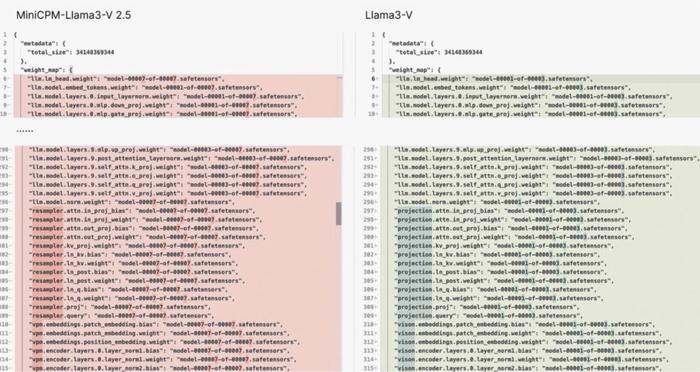
3、Llama3-V提供的代碼無法與Hugging Face的檢查點兼容。

但網友將Llama3-V模型權重中的變量名稱更改爲MiniCPM-Llama3-V 2.5的名稱後,該模型就可以與MiniCPM-V代碼一起成功運行。
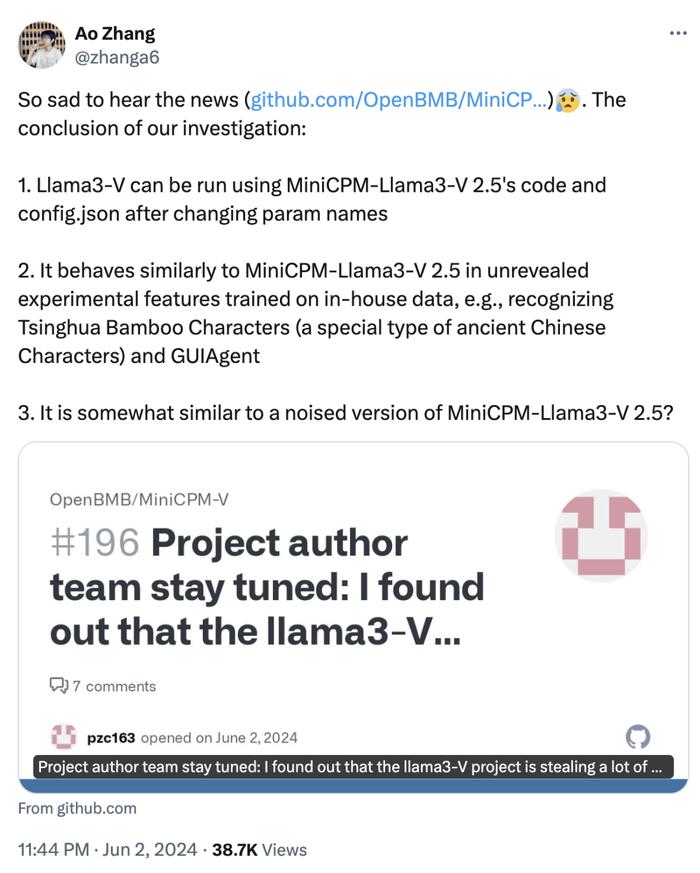
面壁智能的研發人員的調查結果也顯示:更改參數名稱後,可以使用MiniCPM-Llama3-V 2.5的代碼和config.json運行Llama3-V。
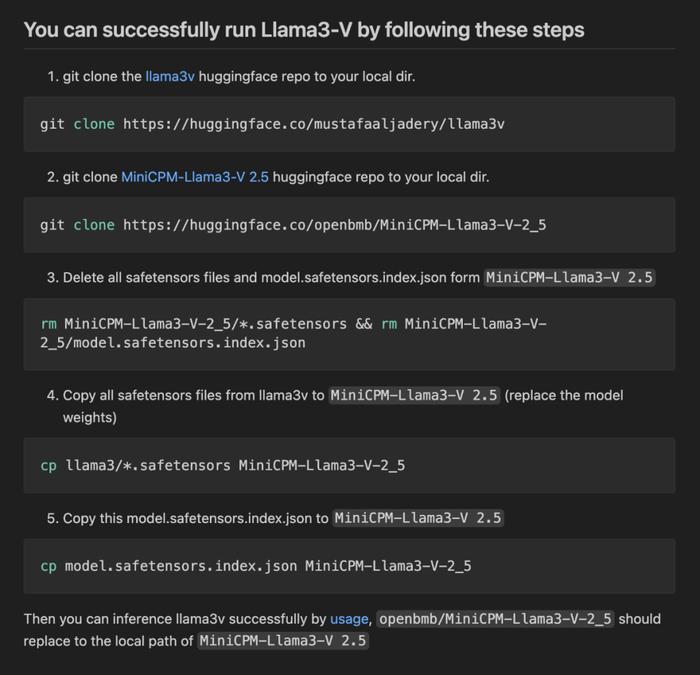
4、Llama3-V項目的作者害怕面對質疑,刪除了質疑者在Llama3-V上提交的質疑他們偷竊的問題。並且目前Llama3-V項目已經從开源網站中下架刪除。
5、在一些未公开的實驗性特徵上,比如在內部私有數據上訓練的古漢字清華竹簡,Llama3-V表現出與MiniCPM-Llama3-V 2.5高度相似的推理結果。這些訓練圖像是最近從出土文物中掃描並由面壁智能的團隊注釋的,尚未公开發布。
例如下圖中的幾個古漢字識別:

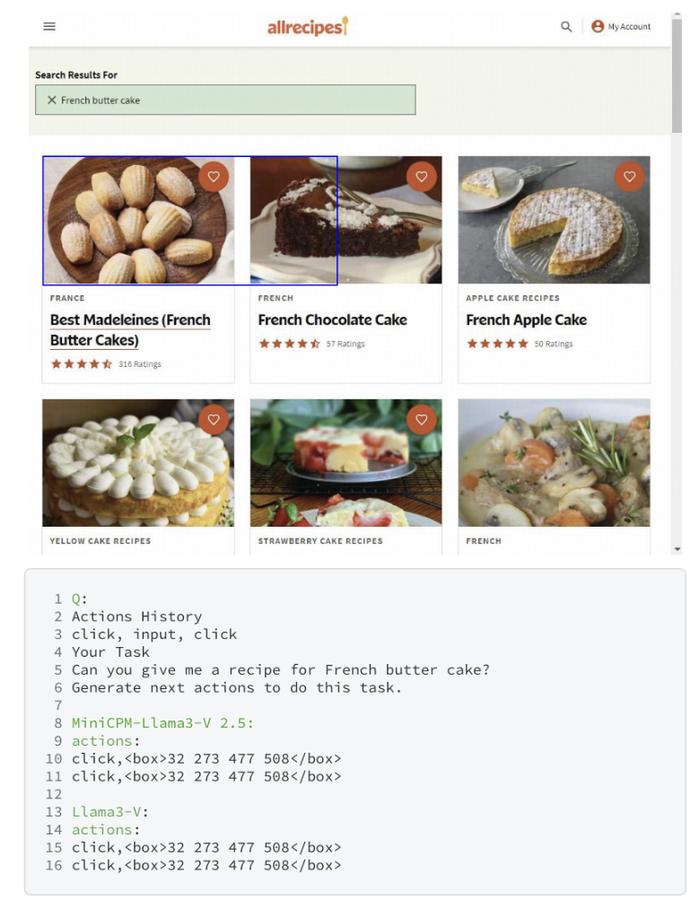
MiniCPM-Llama3-V 2.5中未公开的WebAgent功能上,在框選內容大小時,Llama3-V與之犯了相同的錯誤:
02.
仨作者內訌,Aljadery全權負責寫代碼
但拿不出訓練代碼
昨天,Aksh Garg、Siddharth Sharma在外媒Medium上公开回應:“非常感謝在評論中指出(Llama3-V)與之前研究相似之處的人。我們意識到我們的架構與OpenBMB的‘MiniCPM-Llama3-V2.5:手機上的GPT-4V級多模態大模型’非常相似,他們在實現方面領先於我們。爲了尊重作者,我們刪除了原始模型。”Aljadery沒有出現在聲明中。
 ▲Aksh Garg、Siddharth Sharma的回應聲明
▲Aksh Garg、Siddharth Sharma的回應聲明
Mustafa曾在南加州大學從事深度學習研究,並在麻省理工學院從事並行計算研究,擁有南加州大學計算機科學學士學位和計算神經科學理學士學位,目前其沒有在公司任職。
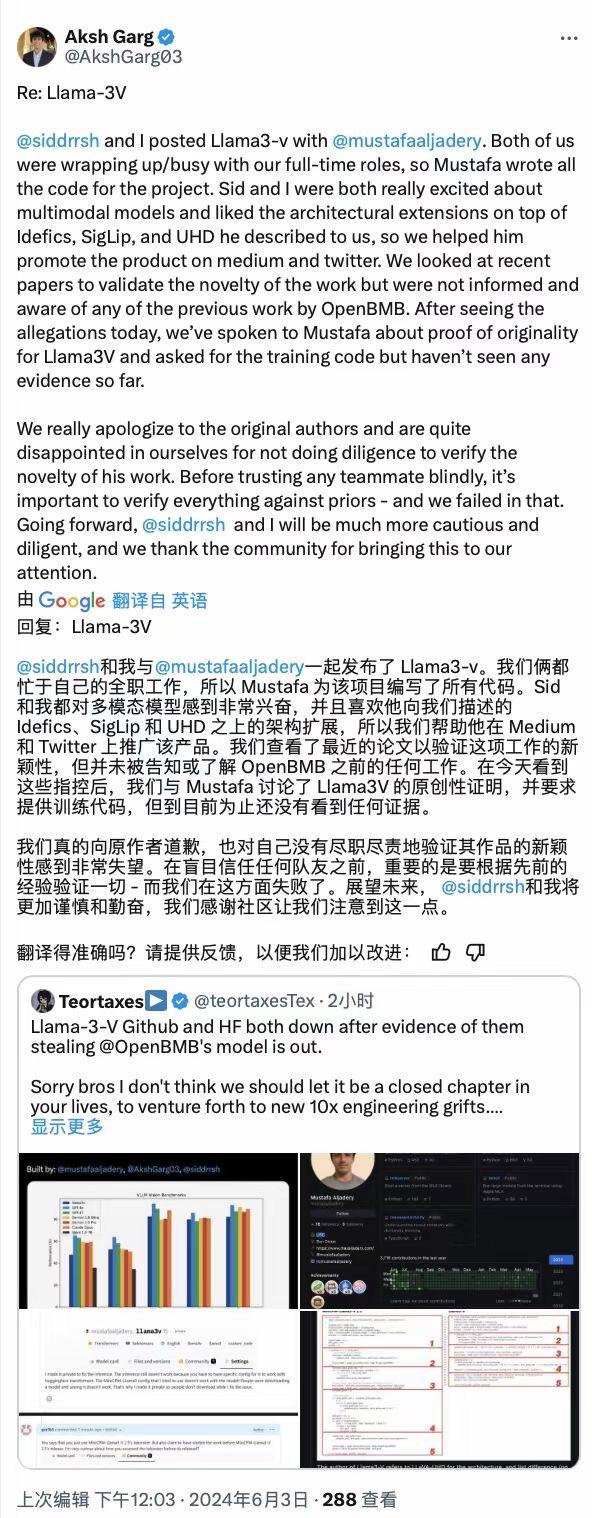
Garg在社交平台X中發布的致歉聲明中提到,Mustafa全權負責編寫Llama3-V的代碼,他與Sharma因忙於全職工作並未參與代碼編寫。
在聽取了Mustafa描述的Idefics、SigLip等架構擴展創新、查看了最新論文後,他們二人就在未被告知該項目與开源代碼關系的情況下,幫助Mustafa在外媒Medium和社交平台X對Llama3-V進行了宣傳推廣。
在昨天看到關於Llama3-V的抄襲指控後,Garg和Sharma就與Mustafa進行了原創性討論,並要求他提供訓練代碼,但目前未收到任何相關證據。
目前,Aljadery的推特账號顯示“只有獲得批准的關注者才能看到”。
03.
首個基於Llama-3構建的多模態大模型
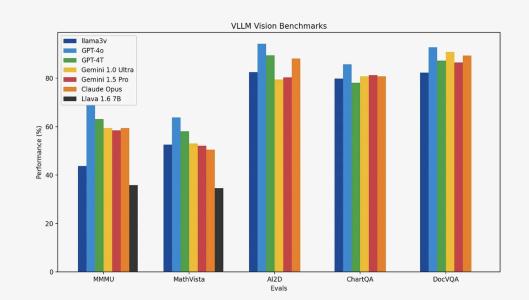
此前,Garg在介紹Llama3-V的文章中提到,Llama3-V是首個基於Llama-3構建的多模態大模型,訓練費用不到500美元。並且與多模態大模型Llava相比,Llama3-V性能提升了10-20%。
除了MMMU之外,Llama3-V在所有指標上的表現都與大小爲其100倍的閉源模型非常相近。
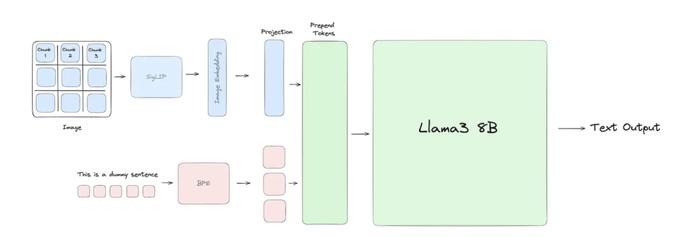
他們所做的就是讓Llama 3能理解視覺信息。Llama3-V採用SigLIP模型獲取輸入圖像並將其嵌入到一系列塊嵌入中。然後,這些嵌入通過投影塊與文本標記對齊,投影塊應用兩個自注意力塊將文本和視覺嵌入放在同一平面上。最後,投影塊中的視覺標記就被添加到文本標記前面,並將聯合表示傳遞給Llama 3。
04.
結語:Llama3-V套殼實錘
或損害开源社區健康發展
不論從網友的質疑還是Llama3-V作者的回應來看,該模型套殼MiniCPM-Llama3-V2.5已經基本實錘,高度相似的代碼以及部分基於面壁智能內部未公开訓練數據訓練的功能,都證明這兩大模型的相似性。
目前來看,對於大模型“套殼”沒有明確的界定,但开源大模型以及开源社區的構建本意是促進技術的共享和交流,加速AI的發展,但如果以這種直接“套殼”、更改變量的形式使用,或許會與這一發展愿景背道而馳,損害开源社區的健康發展。
標題:斯坦福AI團隊抄襲國產大模型?連識別“清華簡”都抄了!清華系團隊發文回應
地址:https://www.utechfun.com/post/379460.html