
作者 | 章漣漪
編輯 | 章漣漪
“It’s ok,Hopper。You’re very good,good boy or good girl”。
北京時間3月19日凌晨,GTC最重磅的主題演講开始,英偉達創始人黃仁勳身着標志性的皮衣,先是感謝了“改變世界的Hopper”,並宣布重磅推出新一代AI芯片架構Blackwell。
在他看來,加速計算已達轉折點,通用計算已走到盡頭,需要有另一種計算方式,來進一步降低計算成本、提高計算效率。"我們需要更大的GPU。"黃仁勳說。過去8年時間裏,AI算力需求有了1000倍增長。在Blackwell架構下,芯片之間可連接構建出大型AI超算集群,支撐更大的計算需求。“它是英偉達最成功的產品”。黃仁勳進一步介紹表示,Blackwell擁有2080億個晶體管,是上一代芯片“Hopper”800億個晶體管的兩倍多,可以支持多達10萬億個參數的AI模型。“其將成爲亞馬遜、微軟、谷歌、甲骨文等全球最大數據中心運營商部署的新計算機和其他產品的基石”。

第一款採用Blackwell架構的芯片名爲GB200。它被黃仁勳稱爲“史上最強AI芯片”,將於今年晚些時候上市。B200芯片擁有2080億個晶體管,採用台積電定制的4NP工藝制造。值得一提的是,這次的芯片將兩個die連接成一個統一的GPU,die之間的通信速度可以達到10TB/秒。黃仁勳強調,Blackwell架構的全新型GPU處理器設計架構在處理支持人工智能的大語言模型訓練、推理方面速度提高數倍,而成本和能耗較前代改善巨大。他舉例表示,如果要訓練一個1.8萬億參數量的GPT模型,需要8000張Hopper GPU,消耗15兆瓦的電力,連續跑上90天。但如果使用GB200 Blackwell GPU,只需要2000張,同樣跑90天只消耗四分之一的電力。不只是訓練,生成Token的成本也會隨之顯著降低。016大創新技術,Blackwell被認爲是“最成功產品”“1993年,英偉達旅程开始……”
Blackwell GPU登場之前,黃仁勳先回顧了英偉達30年發展歷程,他認爲沿途有幾個重要裏程碑。
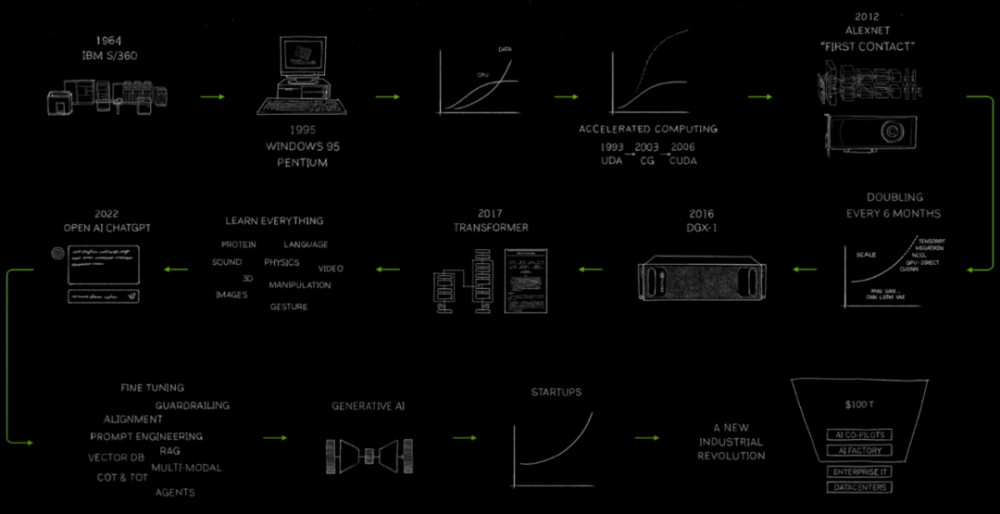
首先是2006年,CUDA發布,黃仁勳表示,後來被證明是一種革命性的計算模型。
“我們當時認爲它是革命性的,以爲它將一夜之間獲得成功。”黃仁勳如是表示,
從後續發展來看,CUDA確實配得上“革命”這個詞。
作爲一項同時支持硬件和軟件的技術,CUDA可利用圖形處理器中的多顆計算核心進行通用計算處理工作,極大加快了开發模型的訓練速度。
可以簡單理解爲,CUDA是英偉達實現軟硬件適配的一種架構,而軟件生態決定了產品的適用性,計算平台決定了硬件的使用效率,CUDA是英偉達實現生態的絕對護城河。
不過,外界認識到CUDA的價值還是將近10年之後。
2016年,AlexNet與CUDA首次接觸,一種名爲DGX1的新型計算機誕生,首次將170teraflops和8個GPU連接在一起。正如外界了解那樣,黃仁勳笑言,“我親自交付了第一台DGX1給一家位於舊金山的初創公司,名爲OpenAI”。
2017年,Transformer到來。
2022年,ChatGPT捕獲了世界的想象力,人們意識到人工智能的重要性和能力。
2023年,生成式AI出現,新的行業开始形成。

“爲什么是一個新行業?”黃仁勳表示,因爲這樣的軟件以前從未存在過,我們現在正在使用計算機編寫軟件,這是一個全新的類別,它從無到有佔據了市場份額,生產軟件方式與此前在數據中心所做的完全不同。
面對全新的市場和需求,需要更強大的GPU。
“Hopper很棒,但Blackwell更好”。黃仁勳認爲,生成式AI是這個時代的決定性技術,Blackwell是推動這場新工業革命的引擎。
根據黃仁勳介紹,Blackwell GPU有6大創新技術,包括:
全球最強大的芯片。具有2080億個晶體管,採用專門定制的雙倍光刻極限尺寸4NP TSMC工藝制造,通過10 TB/s的片間互聯,將GPU裸片連接成一塊統一的GPU。第二代Transformer引擎。得益於全新微張量縮放支持,以及集成於TensorRT-LLM和NeMo Megatron框架中的英偉達動態範圍管理算法,Blackwell將在新型4位浮點AI推理能力下實現算力和模型大小翻倍。
第五代 NVLink。爲了提升萬億級參數模型和混合專家AI模型的性能,最新一代 NVIDIA NVLink爲每塊GPU提供1.8TB/s雙向吞吐量,確保多達576塊GPU之間的無縫高速通信。

RAS引擎。採用Blackwell架構的GPU包含一個用於保障可靠性、可用性和可維護性的專用引擎。此外,Blackwell架構還增加了多項芯片級功能,能夠利用AI預防性維護來運行診斷並預測可靠性相關的問題。這將最大程度延長系統正常運行時間,提高大規模AI部署的彈性,使其能夠連續不間斷運行數周乃至數月,同時降低運營成本。
安全AI。機密計算功能可以在不影響性能的情況下保護AI模型和客戶數據,並且支持全新本地接口加密協議。
解壓縮引擎。專用的解壓縮引擎支持最新格式,通過加速數據庫查詢提供極其強大的數據分析和數據科學性能。
在黃仁勳看來,未來幾年,每年需要企業花費數百億美元的數據處理將越來越多地由GPU加速。02多次迭代,英偉達不斷拉大與對手差距之所以取名Blackwell是爲了致敬美國科學院首位黑人院士、傑出統計學家兼數學家David Blackwell,其擅長將復雜的問題簡單化,獨立發明的“動態規劃”、“更新定理”被廣泛運用於多個科學、工程學等多個領域。而這,也是每一代英偉達GPU架構的命名習慣。GPU的概念,是由英偉達在1999年發布Geforce256圖形處理芯片時首先提出的,從此英偉達顯卡的芯就用GPU來稱呼,它是專門設計用於處理圖形渲染的處理器,主要負責將圖像數據轉換爲可以在屏幕上顯示的圖像。
與CPU不同,GPU具有數千個較小的內核(內核數量取決於型號和應用),因此GPU架構針對並行處理進行了優化,可以同時處理多個任務,並且在處理圖形和數學工作負載時速度更快。
隨後20多年時間,英偉達每隔1-2年提出新的芯片架構以適應計算需求升級,陸續推出Tesla、Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere和Hopper等。不斷增強GPU的計算能力和程序性,推動GPU在圖形渲染、人工智能和高性能計算等領域的應用。
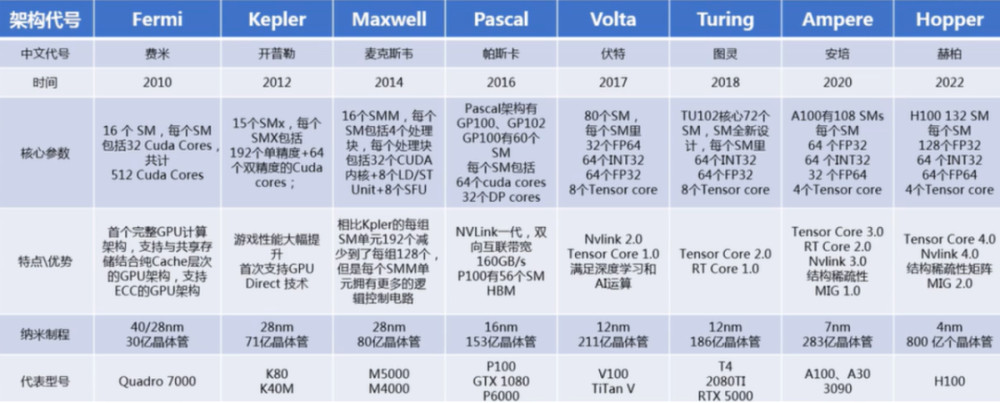
比如,2020年Ampere架構在計算能力、能效和深度學習性能方面大幅提升,採用多個SM和更大的總线寬度,提供更多CUDA Core及更高頻率,引入第三代Tensor Core,具有更高的內存容量和帶寬,適用於大規模數據處理和機器學習任務。再比如,2022年發布Hopper架構,支持第四代TensorCore,採用新型流式處理器,每個SM能力更強。
可以理解爲,GPU架構的更新主要體現在SM、TPC(CUDA核心的分組結構)增加,最終體現在GPU浮點計算能力的提升。
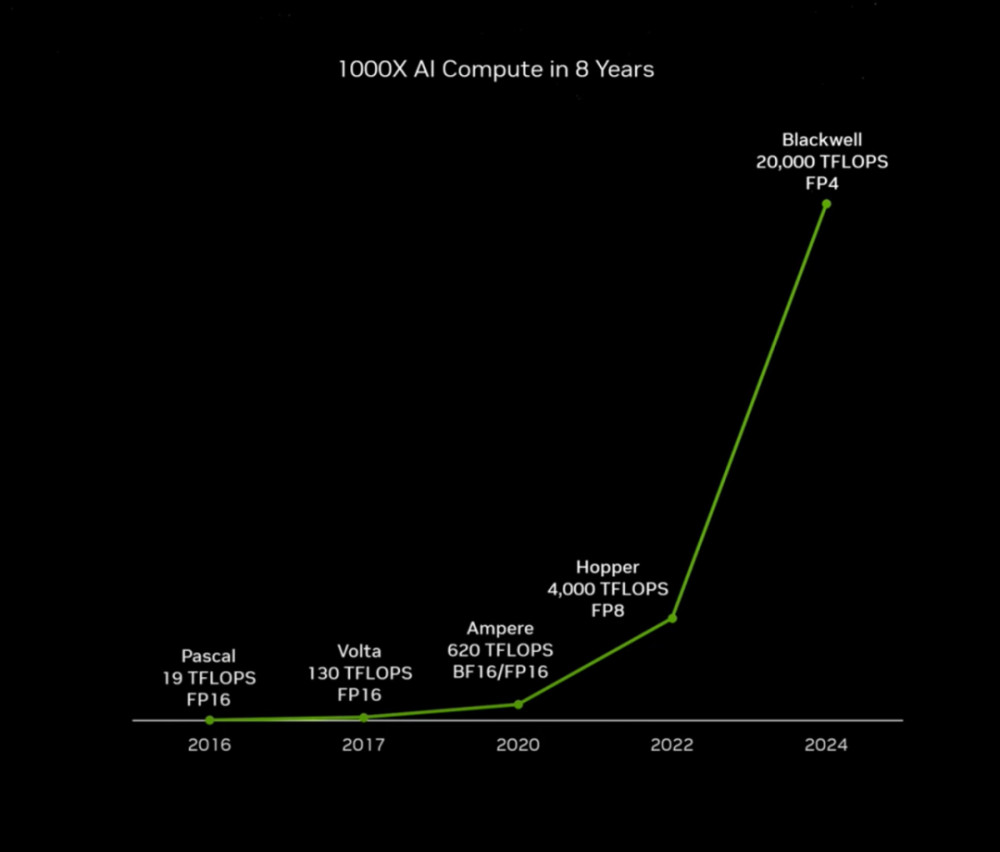
從Pascal架構到Blackwell架構,過去8年,英偉達將AI計算性能提升了1000倍。“在Blackwell架構下,芯片之間可連接構建出大型AI超算集群,支撐更大的計算需求。”黃仁勳表示,GPU的形態已徹底改變,未來英偉達DGX AI超級計算機,就是AI工業革命的工廠。從數據和性能看,英偉達的GPU產品在AI訓練上的性能和水平,確實與全球其他玩家的差距在進一步拉大。這也使得英偉達芯片在大模型訓練領域佔比不斷提升,但受限於芯片管制、產能等因素,在推理市場,英偉達丟失了一些份額。03生成式AI微服務推出,打造AI應用級入口兩周前,英偉達在CUDA11.6更新版本中強調:“禁止其他硬件平台上運行基於 CUDA的軟件”。顯然,它想要訓練和推理芯市場一起抓。爲了上述目標的實現,光有硬件還不夠,軟件護城河也要跟上。
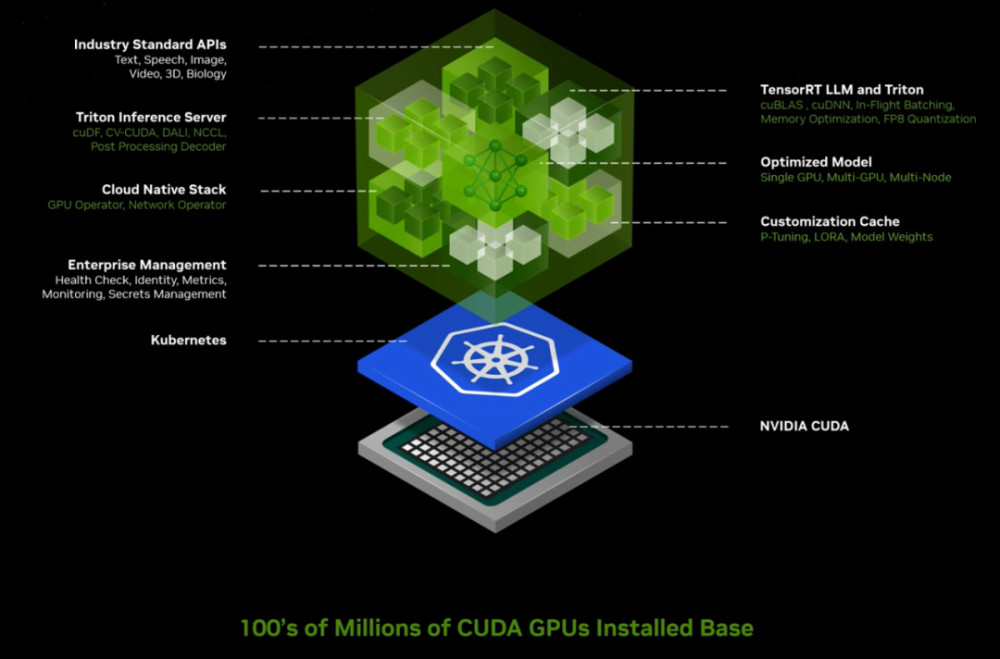
因此,在講完硬件生態之後,黃仁勳开始介紹在AI軟件方面的創新,即生成式AI微服務NIMS(Nvidia Inference Micro Service)。
在黃仁勳看來,生成式AI改變了應用程序編程方式。未來,企業不再編寫軟件,而是組裝AI模型,指定任務,給出工作產品示例,審查計劃和中間結果。而NIM的出現能夠讓這件事的實現更加簡單。黃仁勳希望,用NIM平台,支持應用廠商开發智能應用,將NIM打造爲CUDA生態之後的一個AI應用級入口,增加生態護城河價值。據介紹,英偉達NIM是英偉達推理微服務的參考,是由英偉達的加速計算庫和生成式AI模型構建的。微服務支持行業標准的API,在英偉達大型CUDA安裝基礎上工作,並針對新的GPU進行優化。“企業可以利用這些微服務在自己的平台上創建和部署定制應用,同時保留對知識產權的完整所有權和控制權”。據黃仁勳介紹,NIM微服務提供基於英偉達推理軟件的預構建容器,使开發者能夠將部署時間從幾周縮短至幾分鐘。它們爲語言、語音和藥物發現等領域提供行業標准API,使开發者能夠使用安全托管在自己的基礎設施中的專有數據,來快速構建AI應用。這些應用可按需擴展,從而爲在英偉達加速計算平台上運行生產級生成式AI提供靈活性和性能。
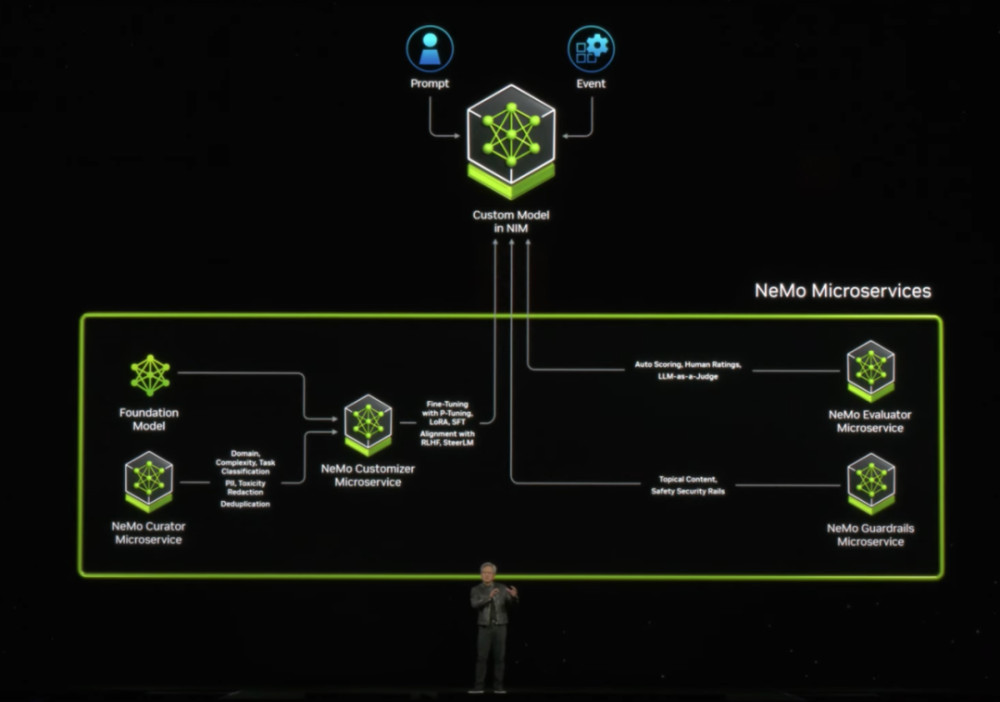
用戶將能夠從亞馬遜SageMaker、谷歌Kubernetes Engine和微軟Azure AI中訪問NIM微服務,並與Deepset、LangChain和LlamaIndex等AI框架集成。同時,爲助力各行業加快开發生產級AI,CUDA-X微服務還爲數據准備、定制和訓練提供端到端的構建模塊,企業可以使用CUDA-X微服務,包括用於定制語音和翻譯AI的Riva、用於路由優化的cuOpt,以及用於高分辨率氣候和天氣模擬的Earth-2。與此同時,英偉達還在不斷打造相關生態系統,包括Abridge、Anyscale、Dataiku、DataRobot、Glean、H2O.ai、Securiti AI、Scale.ai、OctoAI和 Weights & Biases等數百家AI 和 MLOps企業將通過AI Enterprise來支持英偉達微服務。04AI+汽車落地,英偉達繼續擴大汽車朋友圈技術價值的實現,最終需要落地。演講中,黃仁勳還介紹了AI+醫藥、AI+汽車、AI+家電、AI+工業設計以及AI+機器人等方面的進展。其中,汽車方面,黃仁勳透露,比亞迪不止採用英偉達集中式車載計算平台Drive Thor开發下一代電動車,還計劃將英偉達的AI基礎設施用於雲端AI开發和訓練技術,並使用英偉達Isaac與Omniverse平台來开發用於虛擬工廠規劃和零售配置器的工具與應用。
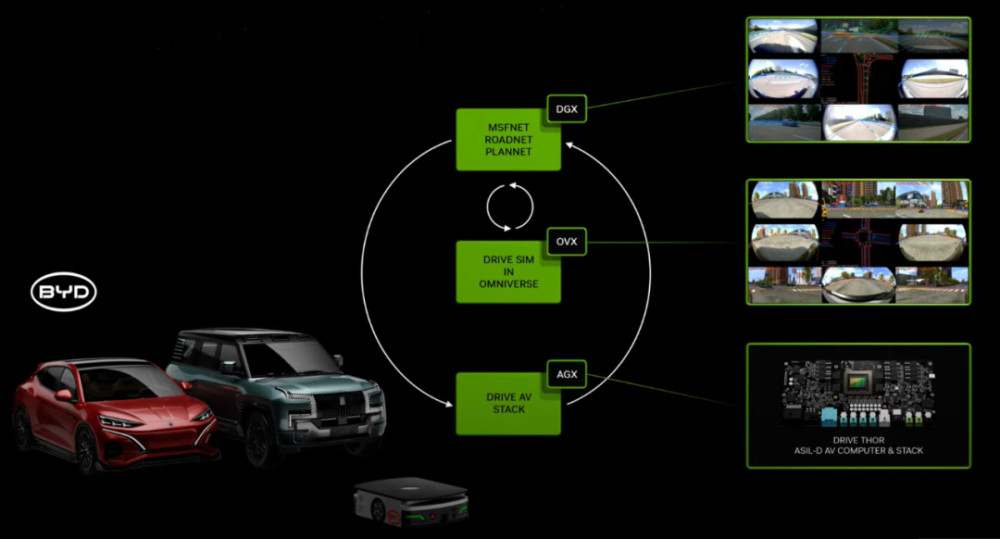
除了比亞迪之外,其他多家汽車制造商和自動駕駛卡車开發商也宣布擴大與英偉達的合作。廣汽埃安旗下高端豪華品牌昊鉑宣布其下一代電動汽車將採用DRIVE Thor平台,新車型將於2025年开始量產。小鵬宣布將把DRIVE Thor平台作爲其下一代電動汽車的“AI大腦”。這款新一代車載計算平台將助力該電動汽車制造商自研的XNGP智能輔助駕駛系統,實現自動駕駛和泊車、駕乘人員監控等功能。DRIVE Thor是英偉達於2022年9月發布的最新一代Drive平台。彼時,英偉達方面稱,這顆SoC芯片內部擁有770億個晶體管,可實現2000 TOPS的AI算力,或者是2000TFLOPs。根據英偉達介紹,除乘用車外,DRIVE Thor在自動駕駛領域也在持續擴張。

其中,Nuro正致力於开發用於商用車和乘用車的L4級自動駕駛技術,該公司選擇DRIVE Thor爲Nuro Driver提供助力;智加科技宣布,其L4級解決方案SuperDriv的下一代產品將在DRIVE Thor計算平台上運行;文遠知行正在與聯想車計算一同基於DRIVE Thor來創建多個商用L4級自動駕駛解決方案。可以預見,伴隨着Blackwell架構和Thor芯片的推出、落地,英偉達將進一步鞏固在智能駕駛、人工智能等領域的地位。
原文標題 : 8年增長1000倍,英偉達帶來史上最成功的產品
標題:8年增長1000倍,英偉達帶來史上最成功的產品
地址:https://www.utechfun.com/post/348526.html