
引言
2023年3月,一家僅創立幾個月的機器人公司號稱要推出“世界上第一個商業上可行的通用人形機器人”,並放出了幾張PPT。
接下來的一年中,這家名爲Figure的公司經歷了——被質疑“碰瓷波士頓動力”——創紀錄地邁出人形機器人“動態雙足行走”第一步——半個硅谷科技圈下注, 融資高達6.75 億美元,估值猛漲至26億美元。
本周三,僅在B輪融資完成後的13天,這位“當紅炸子雞”放出了Figure 01的最新視頻。
雖然只用到了一個“端到端”神經網絡,但Figure 01卻可以在你想要食物時,貼心地遞上蘋果而不是盤子;還能一邊回答你的問題,一邊對物品進行分類——將垃圾收拾進框子裏、將杯子和盤子歸置放在瀝水架上。而且!它甚至能回答你餐具瀝幹水分的大致時間。

有人說,Figure只用了1年時間,就走完了波士頓動力20多年的路。於是,壓力給到了波士頓動力,讓我們回到實驗室,再扒一些女團舞吧(bushi)。

話說回來,Figure 01的最新視頻有沒有一絲絲“注水”的可能性?難道傳說中“世界上第一個具身智能”機器人真的來了?!
Figure創始人Brett Adcock特意在X上強調,視頻是以1.0倍速度拍攝並連續拍攝的,機器人是在完全自主的情況下進行的行爲,沒有遠程操作。
言外之意就是“無剪輯,無加速,一鏡到底”。
然而,適道和一些相關領域投資人交流時,獲得了另一條思路:有沒有一種可能——Figure 01的完美表現是“試”出來的。
例如在測試階段,當你說“我餓了”並指向“蘋果和碗”,Figure 01會遞給你碗;當你指着“梨子和盤子”,Figure 01會遞給你盤子。可能試了一大通後,得出面對“蘋果和盤子”組合,Figure 01的表現是最好的。
但在適道看來,與其說這是“注水”,不如說這正是Figure神速進化的技術祕籍——“端到端”技術黑盒。
01 Figure進步神速的祕籍——“端到端”神經網絡
根據Brett Adcock的說法,Figure 01主要通過“端到端”神經網絡來與人類進行對話。大致流程爲:OpenAI的LLM提供“大腦”——視覺推理和語言理解 ;Figure神經網絡提供“小腦”——做出一系列快速、低級、靈巧的機器人動作。
Figure機器人操作高級AI工程師Corey Lynch進一步解釋:“這些神經網絡以每秒 10 幀的速率接收機器人內置圖像,並能生成每秒200次的24自由度動作(包括腕部姿勢和手指關節角度)”
何爲“端到端”?
“端到端”(End-to-End)是深度學習中的概念,指一個AI模型,只要輸入原始數據,就能輸出最終結果,有點像馬斯克遵循的“第一性原理”。
舉個簡單的例子,兩個同齡小孩,一個生活在城市,一個從小長在河邊。城市小孩想學遊泳,需要找教練,進行一系列抱水、換氣、劃水、蹬腿的分解動作,才能系統性地掌握蛙泳技能;而在河邊長大的小孩,看了大人們遊泳的姿勢,就去下河摸索,經歷了嗆水、訓練、強化,也學會了遊泳,而且遊得像魚一樣嫺熟。
如果你要問這個小孩經歷了哪些針對性訓練,都有什么訓練模塊,他一定答不出所以然。但從結果來講,他不僅泳技超群,甚至學習時間還可能更少。
“端到端”的原理跟這個例子有點類似。
例如,想讓機器人變成“咖啡師”,如果通過傳統編程,雖然看起來“透明”“可解釋”,但代碼非常復雜,靈活性也很差。
而Figure 01的卓越表現證明了,通過這種“不可解釋”的“端到端”神經網絡(輸入視頻、輸出行動軌跡),機器人能夠在數小時訓練後就能get新技能。
在1月5日的視頻,Figure 01展示了自己出色的“學霸”能力,只需觀看10小時的人類煮咖啡錄像,就能學會人類的動作和手勢,並通過模仿這些動作,成爲一名real咖啡師。

而“端到端”也正在成爲機器人訓練的主流路子。例如,1X EVE 、Digit同樣是通過“端到端”學習新技能。
由此不難得出,雖然目前Figure 01展示的只是做咖啡、物品分類,但理論上,只要獲取到人類的數據,進行“端到端”地訓練,它就能掌握更多技能。
我們再回到被“質疑”的“蘋果和盤子組合”——即便Figure 01的完美表現是“試出來”的,但隨着“端到端”訓練量加大,“試錯”會越來越少,成功率越來越高,最終Figure 01或許真能輕松拿捏家務,說不定還會在你喊餓時包出一頓餃子。
這一切正如創始人Brett Adcock所言:機器人就像我的孩子們一樣,在他們學習做某件事的過程中,盡管可能失敗了很多次,但他們一旦掌握了就不會忘記,然後他們會不斷積累新的技能。
02 創始人:人形機器人成本會低於一台廉價電動汽車
Figure的創始人Brett Adcock年僅38歲,但Figure已經是他創立的第三家科技公司。在去年10月的一次訪談中,Brett 分享了 Figure 01的設計過程,以及他對於通用人形機器人領域的預測。
Brett 認爲人形機器人研發一定是軟硬件一體的過程,LLM 爲機器人提供了強大的大腦,是軟件層面的重要補足,而硬件角度,幾乎沒有成熟的供應鏈可供使用,因此,Brett要求團隊在設計產品的同時就要考慮到機器人重量、計算處理、現實環境等細節。

適道也對訪談進行了原文編譯和節選,請配合食用。
1、簡單介紹一下 Figure,你們的使命和目標是什么?
Brett:Figure 是一家 AI機器人公司,專注於設計自動通用人形機器人(Autonomous General-purpose Humanoids)。自動通用人形機器人是指具備自主能力,能夠自動執行多種任務,並且在外觀和行爲上類似於人類的機器人。我們的目標是在長期能夠部署和人類數量一樣多的人形機器人,讓體力勞動成爲一種選擇而非必然。
我們的遠期計劃是在全球部署 100 億個人形機器人。未來 1-2 年內,我們的重點將放在开發具有裏程碑意義的產品上,希望在未來一兩年內,能向公衆展示大量人形機器人產品的研發成果,包括 AI 系統、低級控制(Low-Level Control)等,最終展示能在日常生活中發揮作用的機器人。
2、如果能成功降低制造成本、提高生產量,一個功能完善的人形機器人制作成本能降低多少?
Brett:如果我們回顧消費品或汽車行業的發展歷史時,可以看到產品的價格與生產量之間存在強相關。根據經驗曲线(Experience Curve),每當生產數量翻倍,產品的價格或成本就可能下降 20%或 30%。因此,我們可以認爲價格取決於生產量。
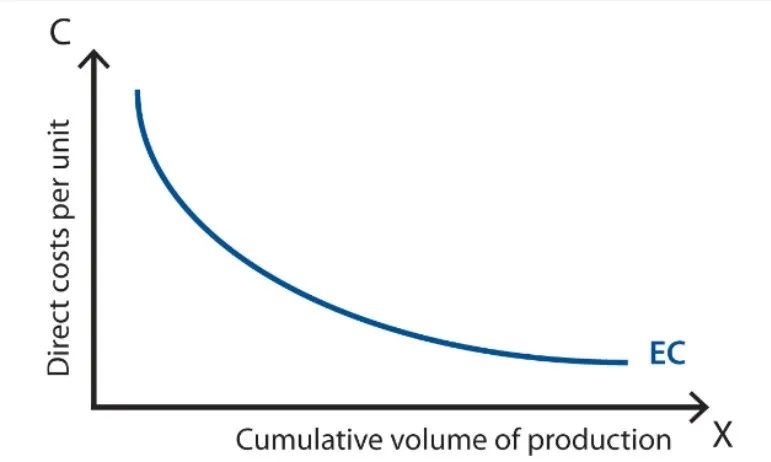
這個原理同樣適用於人形機器人的生產。目前,一個人形機器人大約有 1000 個零件,重量約爲 150 磅(68 公斤)。相比之下,一個電動汽車可能有大約 1 萬個零件,重量可能在 4000-5000 磅(1800-2250 公斤)之間。
從長期來看,一個人形機器人的成本應該低於一台廉價電動汽車。這主要取決於機器人的執行器、電機組件、傳感器的成本以及計算成本。
3、你們打算訓自己的模型,還是集成其他模型?
Brett:要讓人形機器人從工廠走進家庭,關鍵在於語言,所以 LLM 或視覺語言模型對我們的業務幫助很大。我們要讓機器人能夠從語義層面理解世界,做到理解和回應用戶的需求和指令,恰好 LLM 可以做到這點。
因此,我們會逐步將視覺語言模型加入機器人的研發過程,從高層次的行爲角度來幫助人形機器人理解人類在說什么,讓它能與人類進行對話,同時推斷和理解人們在說什么以做出回應。
我們很可能不會自己訓模型,但我們可以在機器人系統上訓練視覺語言模型,關聯傳感器數據。
打造一個正確的 AI 數據引擎對我們來說非常重要,它能確保我們對機器人產生的數據進行准確的訓練,對神經網絡進行正確的訓練,以便未來能夠有效地部署和使用。這也是驅動我們盡快讓產品進入市場的動力,我們希望將更多的機器人投放市場,收集數據,從而讓我們未來的機器人隊伍將變得更加智能、學會更多技能。
4、爲什么需要軟硬件一體开發?
Brett:如果算上做控制系統(control)、中間件(middleware)和自主決策與行動能力(autonomy)的人,我們的軟件佔比會比硬件稍微多一些,因爲硬件團隊的員工只有 15 個左右,軟件規模要明顯大一些。
長遠來看,軟件會成爲公司最大的業務板塊。Figure 作爲一家專注於 AI 的公司,以後會有一個龐大的 autonomy 團隊,並且研發出關鍵的 AI 數據引擎。
但硬件方面也同樣重要。如果我們真的想做出實現高性能、高可靠性、高安全性和低成本的人形機器人,就需要开發自己的執行器、電子設備、電池和幾乎所有軟件,因爲這些都沒有現成的解決方案。
長時間從事軟件开發再進入硬件領域是真的很困難,研發硬件需要經過一個漫長的迭代周期,這也是我們受挫的主要因素。
5、人形機器人的潛在大市場在哪裏?何時出現?
Brett:我們計劃先在未來十幾年內持續擴大在商業勞動力市場的規模。我們關注的領域包括醫療保健、房地產、建築和零售等,我相信這些領域都有巨大的市場潛力。
另外,還有一些市場尚未應用人形機器人,比如房地產。科技房地產公司开發的在线平台可以使用人形機器人來代替人類經紀人提供服務。人們可以通過訪問網站預約看房,然後由人形機器人打开門迎接他們,在一個虛擬的房屋中全程介紹。這是一個價值數萬億美元的市場,但科技公司迄今爲止還未涉足,因爲目前房地產領域的工作仍然過於依賴人力。
此外,還有許多行業的工作可以通過遠程操作或其他技術來完成,人形機器人可以爲這些行業帶來新的發展機會。
6、人形機器人會讓人們失去工作嗎?
Brett:我的觀點是在接下來的 10-20 年裏,機器人業務的發展將與自動駕駛汽車的發展路徑類似。就像自動駕駛汽車,高速公路的測試視頻會比城市街道的更早公开,是因爲城市街道有更高的安全要求和更多的不確定性。
同樣,人形機器人也會首先解決相對容易的問題,比如在預知環境和任務的情況下搬運貨物。這類任務就像在高速公路上駕駛,相對簡單易行。然而,更復雜的任務,例如在家中烹飪或照顧老年人,就像在城市街道上駕駛,更具挑战性。
盡管大家對人形機器人的期望往往集中在復雜任務的解決上,比如谷歌的機器人做垃圾分類,豐田研究院在雜貨店等場景的研究,但這些都是非常困難的挑战。
我很高興有這些研究,但從商業角度出發,我們的首要任務應該是解決那些簡單但必要的問題,然後逐漸將 AI 數據引擎應用到更復雜的任務中。
所以 ,Figure 和其他研究團隊關注的事情恰恰相反。我們的目標是在倉儲制造領域應用人形機器人,這個領域的勞動力短缺問題最爲嚴重。全球約一半的 GDP 來自勞動力,我們正在面對全球範圍內的勞動力短缺問題。隨着嬰兒潮一代的退休和生育率的下降,這個問題將越來越嚴重。
原文標題 : Figure 01視頻被質疑“注水”?看看創始人怎么說
標題:Figure 01視頻被質疑“注水”?看看創始人怎么說!
地址:https://www.utechfun.com/post/346192.html