
作者|昭覺
AI新星OpenAI最近有點頭疼,不僅公司和CEO被馬斯克起訴,其拳頭產品GPT-4在性能和價格上均面臨競爭對手的衝擊。
近期,成立不到一年的法國人工智能創企Mistral AI發布了最新大模型Mistral Large,並推出了首個聊天機器人產品Le Chat,直接對標ChatGPT。據了解,Mistral Large在目前所有能通過API訪問的大模型中評分第二,僅次於GPT-4。
更值得關注的是,Mistral AI還與微軟達成了更加深入的合作協議,微軟將投資入股Mistral AI,並爲其提供算力和雲服務,而Mistral AI的大模型資源也將在微軟的Azure雲平台中售賣。要知道,上一個有此待遇的AI創業公司還是OpenAI。
除此之外,更低廉的API接口價格也讓Mistral Large成爲了GPT-4的有力競爭者,並有望在當前的大模型軍備競賽中掀起一場價格战。
比GPT-4更具性價比?
作爲一款誕生於歐洲的大模型,Mistral Large支持英語、法語、西班牙語、德語和意大利語,可深度理解語法和文化背景。另外,Mistral Large的上下文窗口爲32K,可從約2.4萬個英文單詞的大型文檔中精准提取信息;具備精確的指令跟隨能力,便於开發者定制審核策略;支持原生函數調用和限定輸出模式,助力應用开發規模化和技術棧現代化。
性能方面,雖然Mistral AI並未公布Mistral Large的參數量,但其關鍵性能已達到業界前三。
具體來看,Mistral Large在MMLU基准測試中的常識和推理得分爲81.2%,僅次於GPT-4的86.4%。Mistral Large達到了頂級的推理能力,可用於復雜的多語言推理任務,包括文本理解、轉換和代碼生成。其推理准確性優於Anthropic的Claude 2、谷歌的Gemini 1.0 Pro、OpenAI的GPT-3.5,推理速度甚至超過了GPT-4和Gemini Pro,顯示了其在處理復雜任務時的高效能力。
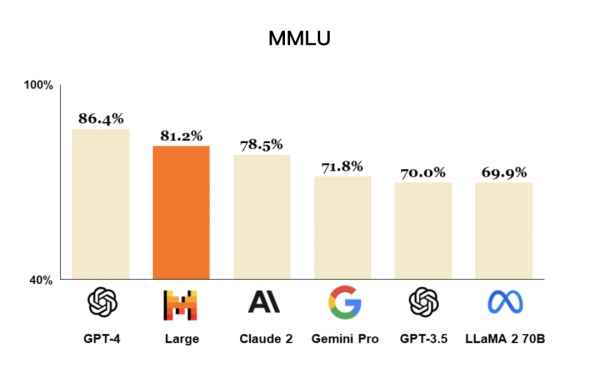
多語言能力測試中,Mistral Large在法語、德語、西班牙語和意大利語的Arc Challenge、HellaSwag、MMLU等基准測試中的表現均遠超目前公認最強的开源大模型——Meta的LLaMA 2 70B。
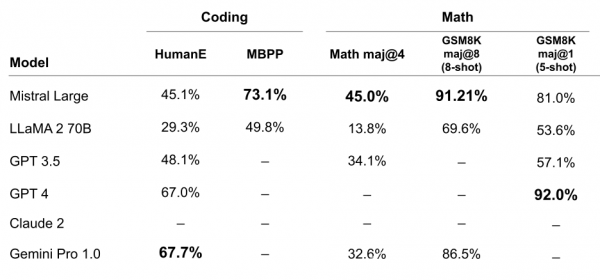
數學和編程能力方面,Mistral Large同樣表現不俗:其在MBPP基准測試中的編程得分高於LLaMA 2 70B,在Math maj@4基准測試中的數學得分也領先於GPT-3.5、Gemini Pro 1.0等模型。
作爲Mistral AI商用系列中的旗艦模型,Mistral Large與GPT-4一樣並未开源。用戶可通過三種方式訪問與使用Mistral模型:其中,在歐洲的Mistral Al基礎設施上安全托管的La Plateforme是开發者訪問Mistral Al所有模型的首選方式,开發者可通過點擊創建自己的應用程序和服務;Mistral Al的开源模型目前可通過GCP、AWS、Azure、NVIDIA等雲服務商獲得,而Mistral Large目前僅通過Azure雲平台提供服務,包括Azure AI Studio和Azure Machine Learning。
此外,开發者還可以通過虛擬雲或on-prem自行部署使用Mistral模型,這種方式提供了更高級的自定義和控制,自有數據將保留在公司內部。
價格方面,目前上下文窗口爲128k的GPT-4 Turbo的輸入價格爲0.01美元/1000 token,輸出價格爲0.03美元/1000 token。相比之下,Mistral Large的輸入、輸出價格均爲前者的80%。
體驗方面,有AI創業者指出,Mistral Large的使用體驗碾壓曾經的第三名Claude 2。截至2023年11月,OpenAI的开發者規模達200萬,其中包含92%的世界500強企業。而Mistral Large直逼GPT-4的性能和更低的售價有望爲需求量巨大的企業用戶節省一大筆开支,從被OpenAI壟斷的MaaS(模型即服務)市場撕开一個口子。
MoE架構立大功
Mistral Large把價格打下來的底氣是更低的訓練成本。OpenAI CEO Sam Altman曾表示,GPT-4的模型訓練成本“遠遠超過了”5000萬至1億美元。而據Mistral AI創始人Arthur Mensch透露,Mistral Large的訓練成本不到2200萬美元,約爲GPT-4的五分之一。
除了真金白銀的訓練成本,後來者居上的Mistral Large的時間成本也更具優勢。OpenAI從成立到推出GPT-4,足足用了8年,而Mistral AI推出僅次於GPT-4的Mistral Large只用了9個月。
Mistral AI號稱歐洲版OpenAI,創始團隊由Meta和Deepmind的前科學家們組成。成立後的半年多時間裏,Mistral AI接連完成1.05億歐元種子輪融資和後續的4.15億歐元融資,得到美國光速、a16z等頂級VC以及英偉達、賽富時、法巴銀行的青睞。
同期,Mistral AI先後推出號稱當時“最強的70億參數开源模型”Mistral 7B、首個开源MoE大模型Mistral 8x7B。其中,Mistral 8x7B更是以一條簡單粗暴的磁力鏈接引領了大模型發布的新範式,給業界帶來震撼。
憑借巨額融資疊加新品發布,Mistral AI的估值也曾一夜之間飆升至20億美元,成爲大模型領域的新晉獨角獸。而Mistral AI更引人關注的是,從初期只有6人的小團隊成長至今,Mistral AI一直是MoE路线的忠實信徒。
MoE即“混合專家模型”,這種模型設計策略通過將大模型分解爲多個子模塊,提高模型的容量、處理能力和效率。MoE架構主要由“專家”和門控機制兩部分構成。每個“專家”相當於一個小型的Transformer模型,專門處理特定類型的輸入數據,多個“專家”的結合則使模型具備了更好的性能。而門控機制則用於判定輸入樣本需由哪些“專家”接管處理。
大模型的大規模應用與其算力成本緊密相關。對於模型廠商而言,目前主要的算力成本包括預訓練成本和推理成本。除去GPU每秒運算次數和顯卡的租用成本這兩個常量後,大模型的預訓練成本與模型參數量和訓練數據的token量正相關,推理成本與模型參數量正相關。而大模型的性能通常與其參數量相關聯,而越高的參數量意味着越高的算力成本。因此,如何在同樣的算力成本下提升大模型的參數量成了破局的關鍵。
而MoE的解題思路是引入稀疏性,即模型訓練過程中,各有所長的“專家”們獨立訓練、各司其職,在過濾重復信息、減少數據幹擾的同時大幅提升模型的學習速度與泛化能力;在推理過程中,每次推理只按需調用部分“專家”,激活其對應的部分參數,如此便有效降低了相同參數下大模型的算力成本。

有意思的是,OpenAI在去年成爲“當紅炸子雞”成功得到衆多重度用戶的續費後,被曝採用MOE重新設計了GPT-4構架,導致性能受到影響。盡管OpenAI官方並未對此進行正面回應,但利用MOE架構降低訓練成本,已經被認爲是一個無比自然的發展方向。
Mistral AI同樣未公布大模型的具體參數與訓練數據Token數,但此前谷歌應用MoE开發出的GLaM模型參數量達12000億、訓練數據16000億token,分別是GPT-3.5的6.8倍和5.3倍,其實際的訓練成本卻只有GPT-3.5的三分之一也印證了MoE框架的高效。
延續着MoE的路线,如果說此前發布的开源模型Mistral 7B、Mistral 8x7B實現了對LLaMA等大參數开源模型的逆襲,此次發布的Mistral Large則是Mistral AI對可持續商業模式的探索,試圖以閉源模型搭建可盈利的產品线。
大模型進入成本战
頂着對華芯片禁售的壓力,芯片巨頭英偉達以一份耀眼的四季報打消了市場顧慮:在數據中心與遊戲業務雙核驅動下,英偉達2023年四季度營收、淨利潤大幅超出預期,毛利率再創歷史新高。業績加持下,英偉達業績已突破2萬億美元,更接連超越亞馬遜、沙特阿美,成爲僅次於微軟和蘋果的全球第三大公司。
數據、算力和算法構成了大模型的基石。在當下這波如火如荼的大模型淘金熱中,從學界到初創企業再到巨頭紛紛下場,而無論其技術路线是开源或閉源,應用場景是通用或垂直,AI芯片作爲大模型大腦,始終是模型預訓練和推理必不可少的工具。

身爲高端GPU市場中唯一的提供方,“軍火商”英偉達是這場大模型軍備競賽中永遠的贏家——以A100爲例,若要通過訓練達到ChatGPT級別的性能,至少消耗一萬張A100加速卡,巨頭們囤貨的單位也以萬張起,怎能不賺得盆滿鉢滿?
但換個角度來看,在GPU供應短缺的背景下,一張A100顯卡售價約10000美元甚至更高,對於大模型廠商來說,在應用落地和商業化前景仍不明朗的情況下,動輒上億美元真金白銀的投入必然肉疼。在算力、數據、人力等資源成本高企的情況下,如何用相對低的成本訓練出一個想要的大模型,並以一個用戶可接受的成本讓大模型跑起來是大模型行業在2024年的當務之急。
在保證同等效果前提下,提高硬件利用率,縮短算力使用時長;優化工具鏈以提高訓練、推理效率;適配低價GPU是當前國內大模型廠商降本的主流方法論。
例如,面向大模型訓練,騰訊升級了自研機器學習框架Angel,針對預訓練、模型精調和強化學習等全流程進行了加速和優化,提升了內存的利用率。借此,大模型訓練效率可提升至主流开源框架的2.6倍,用該框架訓練千億級大模型可節省50%算力成本,大模型推理速度提高了1.3倍。
京東雲推出vGPU池化方案,提供一站式GPU算力池化能力,結合算力的任意切分和按需分配,在同等GPU數量的前提下,實現了數倍業務量擴展和資源共享,降低了硬件採購成本,使用更少的AI芯片支撐了更多的訓練和推理任務,GPU利用率最高提升70%,大幅降低大模型推理成本。

阿裏雲通義大模型則聚焦於規模定理,基於小模型數據分布、規則和配比,研究大規模參數下如何提升模型能力,並通過對底層集群的優化,將模型訓練效率提升了30%,訓練穩定性提升了15%。
百度升級了異構計算平台“百舸”,將訓練和推理場景的吞吐量提高了30%-60%,意味着原先需要用100天的訓練才能達成的效果,現在只需40-70天,節約時間等於間接省錢。同時,在英偉達之外,百度的“千帆”大模型平台還兼容昆侖芯、昇騰、海光DCU、英特爾等國內外其他主流AI芯片,通過組合選項完成低成本的算力適配。
正所謂“早买早享受,晚买有折扣。”當前,Mistral AI以性價比暫時領先,但也有不少开發者還在等待OpenAI大模型產品的升級降價。畢竟,正是OpenAI自己在GPT-4發布後不到8個月就推出了更強也更便宜的GPT-4 Turbo。

原文標題 : 大模型2024:先把價格打下去
標題:大模型2024:先把價格打下去
地址:https://www.utechfun.com/post/344710.html