本文咱們無意引战,只是有些人做的確實太過分了。
1
號稱中國AI教父的李一舟倒了,倒了也就倒了吧,一個江湖術士而已。
但是這背後的事情,這背後的人,這背後人做的背後事,卻不得不令人發涼。
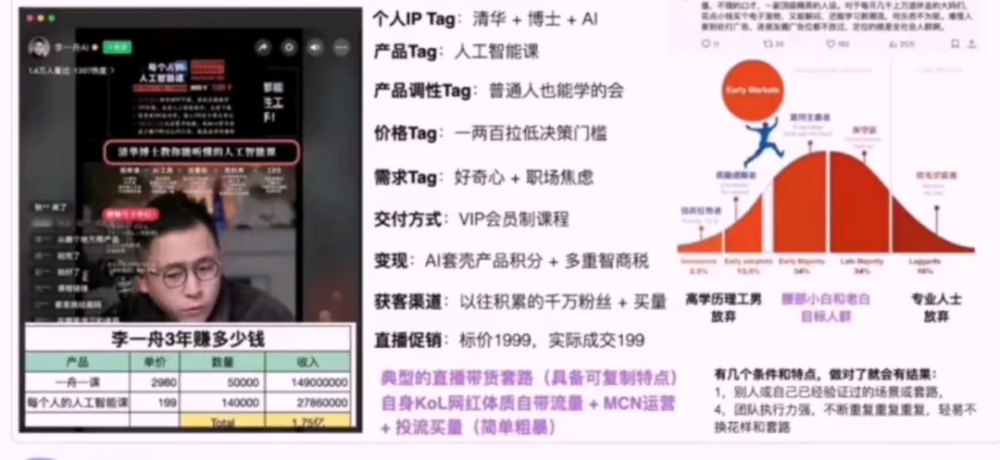
李一舟,一個清華美院學設計的,靠着把自己包裝成了所謂“清華大學博士”、“中國AI第一人”,硬生生用199塊錢小課,通過造焦慮、摳概念一路狂卷了5000多萬。
雖然說平台最終會拿走一大部分利潤,但是5000多萬的韭菜款是實實在在的。
其實這種事兒已經屢見不鮮了,從當初“企管培訓”到後面的“狼性文化班”,從最初的“元宇宙培訓課”到現在的“AI培訓課”,這玩意兒不新鮮,騙子的路數也沒怎么更新。
但是!
我今天要說的不是幾個騙子的事情,要罵的人也不是李一舟。
而是整個中國AI圈!
有些人,是注定要被定在歷史的恥辱柱上的!
2
衆所周知,AI革命,是最接近第四次工業革命的歷史性技術節點,如果要找出一個對於生產力推動比AI還強的技術,可能就只剩下可控核聚變了。
去年11月中美籤署了一份關於同意建立人工智能政府間對話的協議。
這份協議是由兩國元首直接對話達成的,其分量不可謂不重。
AI這個東西,往小了說,他能把曾經需要三四個小時甚至三四天的資料整理、統計、計算工作,縮減到幾秒鐘時間完成,呈幾何式的提高了每個使用者的生產效率。
往大了說,自動化制造、社會管理、醫療工程、企業管理、市場流動等等社會生產和交互工作,80%以上的耗時,都是由統計數據、交流數據、管理數據、決策數據所佔用的。
而AI最強大的效用,就是能夠將這80%以上的“低效耗能”無限縮減。
誰掌握了AI的主動權,誰的生產效率就會像“工業經濟VS農業經濟”一樣碾壓對方。
誰掌握了AI的主動權,誰的社會運轉效率都會大規模提高,而社會運作成本則會極大地縮減。
可以說現在中美國運之爭,爭的核心節點就是看誰第一個邁入第四次工業革命。
就在李一舟爲代表的一重中國AI圈玩家們,還在拿着半拉人工智障割韭菜的時候,美國的AI達人們在幹什么呢?

2 月 16 日凌晨,OpenAI 發布了文生視頻 AI 模型 Sora。
這個sora可以根據你給出的文本提示、靜態圖像或視頻,直接生成或擴展視頻,視頻時長可達 1 分鐘。
而且其逼真和先進度令人乍舌,它不僅能夠生成具有多個角色、特定類型的主題和運動,具備准確且高清的細節特徵的復雜場景。
最可怕的是,這套視頻生成系統,已經可以开始理解基准視頻當中的物理邏輯,生成出幾乎完全仿真的物理模型。

要知道,中美AI起步時間,僅僅相差3個月左右,但是現在我們自己的AI連圖片處理都還費勁,對方已經走到了對物理規律進行理解的水平了。
但是當Sora發布出來以後,我咨詢了衆多專門搞IT技術的專業人員,他們給我的答案無不評價極高。
但是拐回頭來,我們卻能看到網上鋪天蓋地的各路愛國網紅,一個個將其說成“一個佔比不到4%的視頻軟件”、“美國畫的餅”、“過度緊張了”、“我們的主陣地又不在這”。
人是誰我就不貼圖了,網上太多了,隨便就能刷到。
愛國沒錯,我也愛國,但是此時此刻,如此這種將其定性爲“奇淫巧技”式的解說拉流量,或是將其拿來當做割韭菜變現的噱頭玩,這是要出大問題的。
愛國不是自嗨啊!是正視問題解決問題!
上一次大談“我中華地大物博,富有四海”,“國本乃是騎射,不需洋人奇淫巧技”還是辮子們啊!
我們在明末因爲東林黨的一己私利讓整個民族錯過了大航海,在晚清時候因爲八旗的愚昧和傲慢錯過了工業革命,這一回在如此關鍵的競爭中,難道還要再來一次么?
提振國民信心,大可不必用避重就輕、掩蓋事實的方法。
大家如果真想了解這個Sora的真實情況,我把一份專門針對Sora的研究報告放在文末附件裏,掃二維碼回復“sora”領取就行。
咱們繼續說正題。
3
各路網紅其實也不是真正該挨罵的人。
最該挨罵的,就是中國的AI圈!
網紅鑑於自身的知識區塊和職業性質,可以將其解讀爲“支撐貨幣信用的餅”,也可以解讀爲“佔比不到4%的視頻軟件”,這都沒錯。
但是大家有沒有想過,AI這個東西是必須用巨大數據量和實測端口迭代才能喂出來得啊。
可以說數據儲量和AI用戶基數才是AI迭代的關鍵養料。
也就是說社會應用度和應用效率才是迭代的關鍵。
美國從gpt3.0到現在的Sora,從文字理解、到圖片理解、到視頻理解直至此時的物理理解,這四次迭代僅僅用了一年時間。
而我們呢,盡晚了三個月,爲何落後美國的距離會大的如此離譜?!
有人會說是技術不行。
錯!
如果真是技術不行,對神經式計算網絡不理解,中國就不可能在gpt出現的3個月內直接跟進出自己的大模型系統。
這個東西是不能僞裝的,神經式計算網絡跟枚舉型腳本那根本就是兩個次元的東西,技術中國是不缺的。
那你說是不是芯片的問題或者是算力的問題?
也不是,真正的超微型芯片只是應用在小部分高精尖設備領域,支撐最基礎的超級算力的是體量、是穩定性,並不是納米數越小算力就越實用的,美國F35战機上用的都是90納米。
而且要拼算力的話,全世界398台超級計算機當中將近220台是中國的,173台是美國的,中國的算力余額比美國還大!
那是數據儲量不夠?
中國一國的數據儲量幾乎與整個歐美相當,微信9億多用戶,比歐美總人口都多。
每天上百億次支付,以兆計算的文本信息交流,以及數十億次的定位、面部識別信息。
少?
如果這算少,那抖音9億日活,天文數字一樣的視頻數據,還少么?
4
那么問題出哪了?
出在中國這些AI企業、資本的屁股上啦!
我們必須理解Sora的出現,它自身只是一個視頻軟件,但是他的出現代表着美國的AI推廣和應用,以及AI對社會的改造、滲透程度,對生產的賦能已經拉我們中國十幾條街那么遠了!
我前天給在美國的前同事打電話的時候,他告訴我一個讓我後背發涼的消息,他說:“硅谷那邊,現在除了AI的升級和應用,其余的都不談。”
就在李一舟忙着拿他那個垃圾AI課割韭菜圈錢的時候。
就在抖音忙着將第一代AI的商業價值榨,幹忙着收流量費的時候。
就在科大訊飛忙着拿AI的噱頭賣藍牙鼠標和鍵盤的時候。
就在中國科技資本在TMD忙着拿現有的爛貨圈錢、割韭菜的時候,美國的AI科技資本正在瘋狂的推廣AI應用普及,以及不惜血本开發迭代更強的AI系統。
不爭氣啊!
不是能力上的不爭氣,而是思想上的不爭氣。
AI的推廣應用必然會廣泛採集數據,所以爲了國家安全和競爭優勢的考慮,可定不可能放gpt進來,就像美國不能容忍tiktok遍布美歐一樣。
中國將gpt拒之門外,這些公司坐擁巨大的數據資源和應用終端,本應該是奮起直追擴張版圖迭代技術的時候,他們不僅不追,反而將這些技術圈閉爲自己撈錢的噱頭,想要慢慢將每一個版本的利潤榨幹?
這與明末東林爲了東南走私的一己之利,硬生生阻止中國开海數百年,讓中國錯過大航海時代有什么不同?
挾國運以謀私利,有些人注定是要被釘在歷史的恥辱柱上的!
也是奇怪了!
爲什么美國的科技資本圈到錢以後都想要玩命的向上攀爬去追一追星辰大海。
而中國這些人,有了錢以後不是想着從菜農手裏扣走最後一個口飯,就是想着怎么能更有效的放高利貸呢?
中國這個科創圈文化,難道真就是個“狗屎坑裏養不出肥蛆”的環境嗎?
中國的科技強國之路,我發現真的不是技術提升的問題,而是得先從思想开始,從法律开始。
不把這些亂來的手剁掉,還不知道要走多少彎路。
 海量資訊、精准解讀,盡在新浪財經APP
海量資訊、精准解讀,盡在新浪財經APP
標題:有些人,是注定要被釘在恥辱柱上的
地址:https://www.utechfun.com/post/337547.html