Sora的突破,再次證明AI是一個大型系統工程。OpenAI靠的不是蠻力,國內人工智能圈還需要方方面面的補足。
文|趙豔秋
編|牛慧
在春節开工後這一周,國內人工智能圈以及與Sora技術相關的大廠,對OpenAI公布Sora後的反應,與媒體上的熱烈程度形成鮮明反差。
OpenAI越來越閉源,幾乎沒有任何具體信息,國內還處於拆盲盒階段。不得不承認,Sora是算法組合、數據選擇、訓練策略、算力優化等多種能力的結合,雖然這些技術可能不是OpenAI的原創,但OpenAI對它們的深刻洞察,以及精巧的系統構思設計能力,才做出“顛覆性”突破,而非簡單的蠻力。
在這樣的大系統工程面前,國內人工智能圈還需要方方面面的補足。
01
大廠的反應
這一周,字節、百度、阿裏、騰訊、華爲、浪潮等企業未對外發聲。一些相關大廠的研發團隊則在“拆盲盒”,信息也絕對保密,“Sora將影響今年公司產品的研發計劃。”
值得關注的是,對Sora的積極關注度和洞察程度,在大廠的中高層,總體不像去年ChatGPT推出後那么緊迫和深入。
在各大廠內網上,核心研發團隊之外的“喫瓜群衆”,在零星發帖討論,“談不上討論熱度”,甚至有國內人工智能大廠內網是“零貼”。這種狀況與媒體上的熱搜新聞,甚至對中美AI差距加大的哀嚎,大相徑庭。
不過,一些較快的動作,也能窺見業界的一些緊迫感。Sora發布第二天,2月17日,阿裏摩搭社區推出對Sora技術路徑的分析,文章很熱;2月18日,百度的度學堂推出Sora系列解讀課程;春節後剛开工,浪潮相關業務已對Sora給出分析報告。不少大廠相關業務线紛紛布置調研匯報作業,其中有些企業將在本周做出Sora分析調研。
由於OpenAI透露的信息很少,與ChatGPT推出後,對技術的一些具體分析不同,對Sora的分析猜測成分更多,具體依據更少。
從各大廠內部的員工討論看,大家集中在幾個方向:Sora的技術機理,包括Sora能不能成爲真實世界的模擬器;算力;商用方向和時間。目前,技術機理還有不少”謎團“;對算力消耗的推測也較混亂;在Sora商用時間上,預測從一個月到半年不等,普遍認爲速度會很快。
有大廠員工發文分析,從OpenAI的動作,包括發布Sora、ChatGPT、DALLE以及一直強調的agent看,今年下半年OpenAI可能發布的GPT5,將是第一版真正意義的Agent。有了這個Agent,比如未來要做一個App,GPT5可自動生成代碼、圖片、視頻、打包部署,包括申請、配置域名,最終生成可訪問的App。這些推測也預示着,每位員工未來的工作方式正在被重塑。
雖然大廠論壇鮮有對技術差距的哀嚎,但員工在交流中都有抱怨和無奈。不過,也有人士認爲,Sora反而對國內AI超級有利,原因是在全球短視頻市場上,字節、騰訊、快手佔前三,而Sora原理基礎大家也都知道,以國內現有的GPU算力,推測“快的話一年”,國內將有類似產品推出。
02
OpenAI不靠蠻力
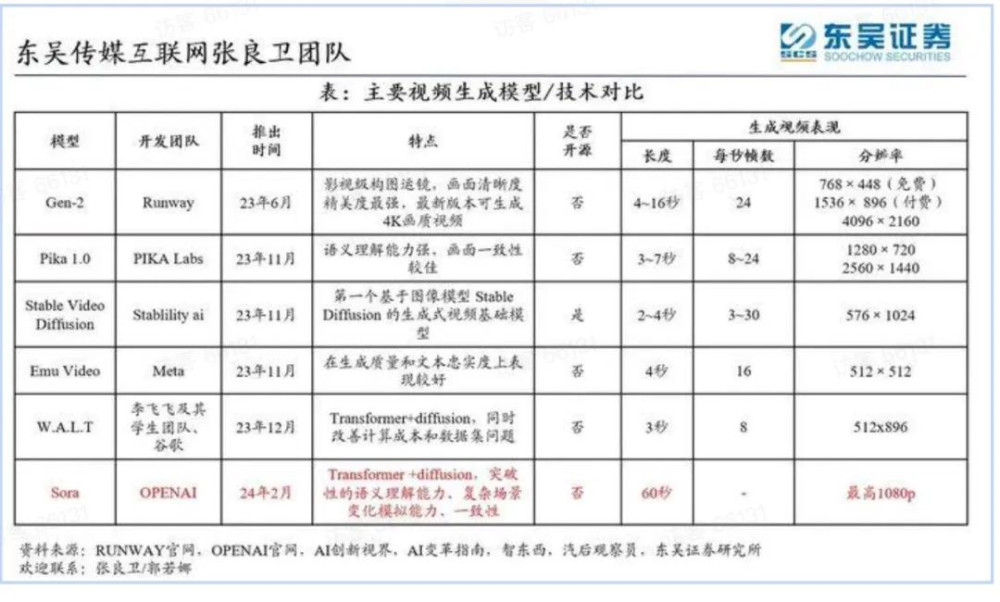
業界都關注到,Sora 的驚豔效果得益於新的算法組合和訓練策略。然而,類似ChatGPT,單純從具體算法來說,都不是 OpenAI的原創。
“Sora 在算法組織和數據訓練策略上下了很大功夫,充分挖掘了算法和數據的潛力,學到更深層知識。”雲知聲董事長梁家恩說,通過架構設計和訓練策略,而非單純算法改進,OpenAI 繼續刷新了業界的認知。這體現了OpenAI對算法和數據潛力的深刻洞察,以及精巧的系統構思設計能力,而非簡單使用“蠻力”,才能做出這種“顛覆性”的突破。
在Sora官宣後,紐約大學謝賽寧對其進行了技術推測。由於謝賽寧與Sora團隊關系較近,他的推測影響很廣,尤其是他猜測“Sora參數可能是30億”。
一些人士認爲30億參數有一定道理。一位資深人士分析,Sora生成的視頻效果驚豔,但細節問題較多,應該是OpenAI拿出來先秀肌肉的,OpenAI會進一步擴展模型;另一位資深人士則從算力角度直觀分析,視頻是三維的,單位處理需要的算力非常大,如果Sora參數太大,算力會不夠。
不過,也有一些行業人士認爲“不止30億”。
“30億參數,我認爲是有誤導性的。”一位短視頻人工智能資深人士告訴數智前线,“Sora背後依賴了OpenAI最強大的語言模型來生成Caption(字幕、說明文字)。”而在Sora提供的技術報告中,簡要描述了,他們針對視頻如何設計自動化技術,生成文本描述,或將簡短的用戶提示轉換爲更長的詳細描述,用來提高視頻的整體質量。
而從OpenAI一直在摸索人工智能邊界的風格來看,一些人士也認爲,30億太小了。“這不符合它一貫的做法,他們都是‘大力出奇跡’。”中科深智CTO宋健對數智前线說,實際上,理論上已指明了道路,有不少企業也去嘗試了,目前來看,真正意義上能執行下去的只有Sora。
一位浪潮人士稱,Sora的突破再次證明了AI是一個系統工程,單純靜態的推測參數可能沒有意義。
在視頻生成上,過去大家的困難在於,很難保持視頻的連貫性或一致性,因爲中間有很多反常識的東西,如光影不對、空間變形,所以業界搞不定長視頻。
“OpenAI 最終是否採用了更大規模的參數,根據目前公开信息還無法判斷,但我估計以他們風格肯定會嘗試的。”梁家恩說,此前,OpenAI 從 GPT2 做到 GPT3 時,就是堅信只要算法架構合理,通過超大規模的無監督學習,是可以通過小樣本甚至零樣本學習,擊敗有監督學習,這是 OpenAI 對規模效應的堅定信念。“這次Sora通過算法組合和數據設計,學到更多符合物理規律的‘知識’,符合 OpenAI 這些年來的一貫風格。”
不過,Sora尚不能稱爲一個合格的物理世界的模擬器。在它生成的視頻中,存在大量錯誤。OpenAI自己也在技術報告中提出,這是一個有希望的方向。
人們對Sora的需求不同。“如果你現在做數字孿生,還不如直接用物理引擎作爲底層來構建,就像英偉達的Omniverse,雖然不完全是物理的,但已經很精確了。”宋健說,“但對於視覺藝術來講,講的是視覺感受力,反物理也沒關系,只要視覺上給大家足夠好的衝擊力就可以。”
03
算力猜想
“現在大家對算力的推測非常混亂。”一位英偉達人士告訴數智前线。由於OpenAI這次公布的信息非常少,業界很難評估。
“視覺模型或多模態模型跟大語言模型算力的評估方式不太一樣。”一位人工智能算力資深人士告訴數智前线,即便Sora可能只有幾十億參數,其算力與幾百億或上千億的大語言模型估計差不多。
他進一步分析,可以參考文生圖模型Stable Diffusion,參數大概只有10億,但訓練算力用了幾十台服務器,花了將近一個月時間。他估計Sora的訓練算力可能比前者至少大一個數量級,也就是數百台服務器,而後面OpenAI肯定會進一步去做scaling,把Sora模型做的更大。
另一方面,這種模型的推理算力也比大語言要大很多,有數據曾顯示,Stable Diffusion的推理算力消耗,與Llama 70b(700億)參數模型差不多。也就是說,推理算力上,一個10億的文生圖模型,與千億量級的大語言模型差不多。而Sora這種視頻生成模型的推理算力,肯定比圖片生成模型還要大很多。
“文本是一維的,視頻是三維的,視頻的單位計算量大很多。”一位人工智能專家告訴數智前线,他認爲需要大幾千卡才有機會。
由於Sora推動的文生視頻方向的發展,今年國內算力總體仍會非常緊張。有算力基礎設施企業人士稱,在人工智能算力上,北美幾家巨頭的算力,現在已是國內總算力的十幾倍,甚至還要更多。
但在某些局部上,國內算力已經出現了闲置。這包含了幾種情況,比如一些去年上半年开始訓練大模型的企業,放棄开發大模型或改爲使用开源模型;去年大語言模型的落地應用遭遇挑战,還沒有大量的推理應用落地,這些會導致一些企業出現幾十台或幾百台的空闲。
宋健也發現了局部算力闲置的問題。他觀察,尤其是2023年11月份左右开始,算力的租賃變得容易,而且價格可能是原來的2/3甚至1/2。
原文標題 : Sora不靠蠻力,大廠忙拆盲盒
標題:Sora不靠蠻力,大廠忙拆盲盒
地址:https://www.utechfun.com/post/335977.html