
AI 的學習能力,目前為止仍停在語言層面。
餵給大模型的語言資料,最初是維基百科和Reddit,後來擴展到影音甚至雷達和熱圖像,後者廣義來說也是換個表達方式的語言,因此有生成式AI新創認為,極聰明的大語言模型就是通往AGI的最終答案,現在這麼多研究途徑只是人類還沒找到正確路的摸索。
我們對未知事物的想像以此為限(如果矽基生命也算)。談到外星生命,衝進腦子的第一個想法是外星語言,《三體》三體人第一次亮相也是與語言相關,因人類文明系統就是這麼運作,推己及人,語言也是其他文明的操作系統,故《人類簡史》作者尤瓦爾·赫拉利5月表達對生成式AI的擔憂,若AI完全掌握人類語言,就有能力駭入人類文明系統。
但AI對人類語言資源的了解,也是人類對AI威脅性的想像極限。換句話說,無法由語言表達和記錄的東西,AI也學不會。世界處處是秀才遇到兵,從周圍環境獲得生活經驗的本事,是人類面對AI威脅時最後的淨土。
直到DeepMind帶著登場,最後淨土也要守不住了。
DeepMind高階工程師、平時還要管理非洲AI技術社群的Avishkar Bhoopchand,和流轉於各種遊戲公司五年然後進入DeepMind的Bethanie Brownfield,領導18人團隊,最近於《自然》發表研究成果。
簡單說,他們在3D模擬環境用神經網路結合強化學習訓練出智慧體,智慧體從未接觸任何人類資料,完全從零開始學習,過程就像人類。此實驗AI和Culture(文化)概念連結似乎是第一次,因廣義的人類智力可理解為有效獲取新知識、技能和行為的能力,也就是如何適當情境下行動以達成目標的能力。如:
- 如何用公式和輔助線解開幾何題。
- 如何把IG看到的食譜變成晚飯。
- 如何開能賺錢的公司。
都是智力的體現。論文舉例更簡單:如何旅行時不跟丟導遊,或向同事說明影印機怎麼用。人類很多技能都不是一步一腳印學來的,反而特別依賴從其他人身上直接複製知識的能力,統稱為文化,從個體傳遞知識到另一個體的過程就稱為文化傳播(cultural transmission)。
文化傳播是種社會行為,靠整個群體即時彼此學習和使用資訊,讓技能、工具和知識積累提煉,最終形成文明,個體甚至世代間高度穩定傳遞知識,沒有書或影片能講清楚說明白。當AI研究者擔心大模型資料庫五年後會枯竭,這首先建立於AI有巨大能力盲區基礎上,也就是直接從環境抽象化發散資訊的能力。
DeepMind智慧體訓練引入GoalCycle3D,是Unity引擎構建的3D物理模擬任務空間,看下圖可知,裡面有崎嶇地形和各種障礙物,障礙物和複雜地形間又有各種顏色球體,若照特定順序經過目標球體會獲得積極獎勵。
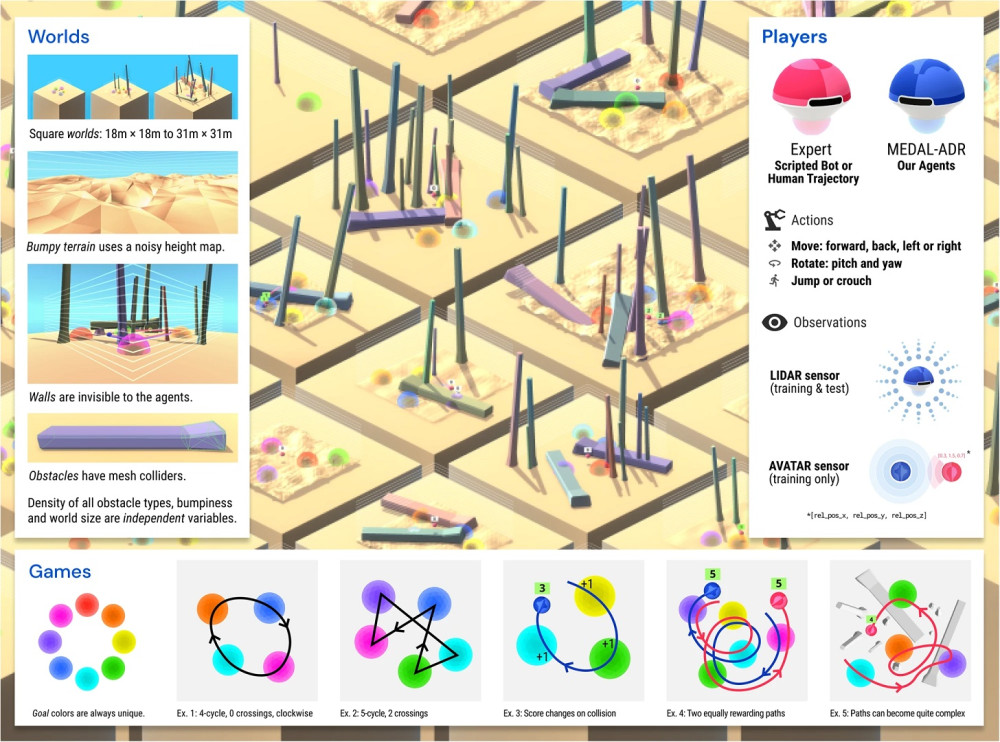
DeepMind設置了上帝視角:知道如何行動能拿到獎勵的紅智慧體,藍智慧體是毫無遊戲經驗的被訓練方,拿到高分的行為即視為文化。完全沒有遊戲背景的智慧體文化傳播(CT)值為0,完全依賴專家的智慧體CT值為0.75。紅智慧體在場時完美跟隨,紅智慧體離開後仍能獲高分的智慧體CT值為1。
實驗結果為隨機生成的虛構世界,藍智慧體靠強化學習「得高分」文化,會經歷四個階段。
第一階段,藍智慧體開始熟悉任務,學習表示、運動和探索,但得分沒有改善。
第二階段,藍智慧體有足夠經驗和失敗,學會第一個技能:跟著紅智慧體。CT值達0.75,顯示純粹是模仿。
第三階段,藍智慧體記住紅智慧體在場時的有獎勵循環,並於紅智慧體不在場時繼續解決任務。
第四階段,藍智慧體能獨立以自己路線取得高分,這代表訓練文化傳播度量回到0──藍智慧體不必跟在紅智慧體屁股後面了──但得分還在增加。藍智慧體顯示出「實驗」行為,甚至開始使用假設檢驗以推斷出正確循環,故藍智慧體超越紅智慧體,得到更多獎勵。
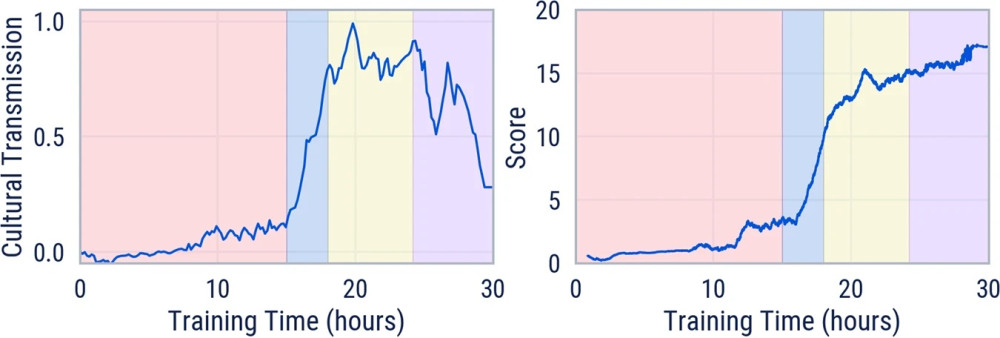
以模仿開始,然後深度強化學習繼續最佳化甚至找到超越前者的實驗,顯示AI智慧體能觀察別的智慧體學習並模仿。這從零樣本開始,即時取得利用資訊的能力,非常接近人類積累和提煉知識的方式。
此研究可視為邁向人工通用智慧(AGI)的一大步,如此重要的發現,DeepMind又是從玩遊戲開始的。DeepMind曾用另一種遊戲以零樣本完成訓練,不過是超越自己,那個遊戲就是圍棋。2016年3月12日李世乭投子認輸,代表人類完敗,而AlphaGO只是幾個月內以16萬局棋譜訓練完畢,卻不能真正坐在棋盤對面下子的程式碼。
然後AlphaGO被打敗了。
打敗AlphaGO的是AlphaGO Zero,沒有看過任何棋譜,僅從圍棋基本規則開始學起的AI。擊敗李世乭的AlphaGO之後稱為AlphaGO Lee,AlphaGO Zero以100:0戰績完全擊敗AlphaGO Lee,而前者僅訓練三天。AlphaGO Zero就如藍智慧體在GoalCycle3D的模式,沒有無監督學習,沒有用到任何人類經驗,卻能追上甚至超越前輩。
2016年以實習生進入DeepMind的Richard Everett也是團隊18人之一。玩遊戲時人類和看似智慧的電腦互動讓他著迷,使他進入人工智慧領域,這次「AI學習文化傳播」正是他最喜歡的計畫。
「在世界最大的糖果店當個小孩」,Richard Everett這樣描述DeepMind的工作。這篇論文要歸功於藝術家、設計師、倫理學家、專案經理、QA測試員及科學家、軟體工程師、研究工程師超過兩年密切合作。
AlphaGO Zero的成功讓DeepMind在AGI這條路上堅持深度強化學習,才有這次GoalCycle3D出現。而AGI大型遊戲實驗仍在繼續,Google DeepMind的官方X最新發文是:
歡迎Gemini。
(本文由 授權轉載;首圖來源:)

標題:DeepMind 新研究:人類最後淨土要失守了?
地址:https://www.utechfun.com/post/303501.html