
Google 大語言模型 Gemini 1.0 一問世就技驚四座。表現方面,無論文字、圖像、音訊理解,或 57 種領域文本及數學問題推理,幾乎都超過自然語言界霸主 GPT-4,Google Gemini 官網還有一句話是「Gemini 是第一個 MMLU(大量多任務語言理解)超過人類專家的模型」。
為什麼Google Gemini這麼厲害?其實最核心原因來自訓練Google Gemini兩種伺服器端推理晶片TPU v4和TPU v5e,雖然從結果看,TPU跟GPU都用於訓練和推理,但兩方「解題思路」相距甚遠。
Google在TPU v4採用光學迴路開關(optical circuit switch,OCS),顧名思義,就是伺服器群組以光傳遞訊息。上方是注入模組,使用850奈米雷射二極體,發射850奈米的顯示光。中間是用來分割或合併光的二向色分光器;下方是用來反射的2D MEMS陣列;左右兩端是用來投射O波段訊號光的2D透鏡陣列和光纖準直器陣列。
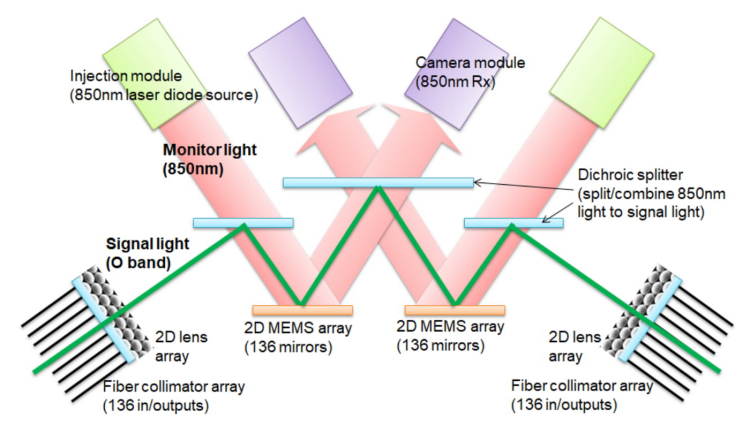
▲ 簡易版OCS原理。
傳統伺服器群組用的是銅線導電,透過規定時間內銅線上電子傳輸的數量來傳遞訊息,但是任何介質、就算是不計成本的採用金或銀,依然有電阻的存在,必然會減慢電子在這之間傳遞的速度。沒有任何的光電轉換環節,全都是由光來運送訊息,沒有中間商賺差價。
我們不妨比較一下市面上最常見,也是Open AI目前的解決方案,輝達H100所使用的Infiniband技術。這個技術使用交換結構拓樸。所有傳輸都在通道配接器處開始或結束。每個處理器都包含一個主機通道配接器(HCA ),每個週邊都有一個目標通道配接器(TCA)。
說的直白一點,H100就跟過去的驛站差不多。驛站會取代權利中心接收訊息,讓管理者可以直接去驛站來查看自己未來的任務。但TPU v4則是直接燒狼煙,不僅快,而且跳過中間所有的消息轉達設施,一步到位。根據Google的說法,OCS系統和底層光學組件成本價格不到TPU v4系統成本的5%,其功耗不到整個系統的5%,又便宜又好用。
說到這,不得不提一個Google創造的概念,叫做MFU。全稱為模型FLOPs利用率(Model FLOPs Utilization),這是一個不同於其他衡量計算利用率的方法,不包含任何反向傳遞期間的作業,這意味著MFU衡量的效率直接轉換為端到端的訓練速度。也就是說,MFU最大上限一定是100%,同時數字越高代表訓練速度越快。
Google想透過MFU這個概念,來評估TPU v4的負載能力以及運作效率,以此得出到底可以給Google Gemini多少強度。對一系列純解碼器變壓器變壓器語言模型(下圖以GPT為例)配置進行了深入的基準測試,這些配置的參數從數十億到數萬億不等。測試規定,模型大小(參數單位十億)是晶片數的二分之一。
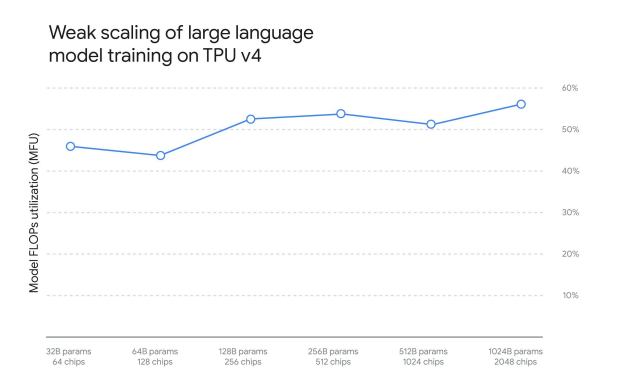
▲ TPU v4在不同場景下的MFU。
在Google的基準測試活動中,TPU v4實現了44-56%的MFU。根據下圖的比較可以明顯看到,尤其是多個TPU v4串聯的情況。而這也正是OCS的神奇之處,同時Google 也希望藉助OCS向世人們傳達一個道理:要相信光。
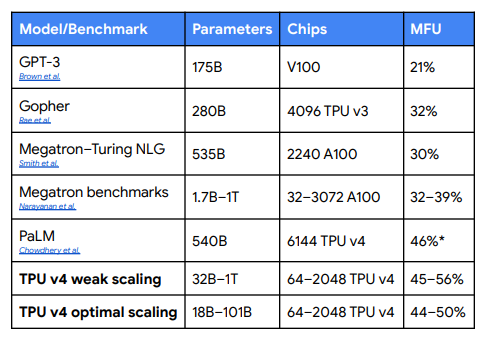
▲ 不同晶片的MFU對比。
既然TPU v4都這麼厲害了,那麼TPU v5e做為迭代產品,效果只會更好。事實上Google之所以將這個模型命名為Gemini,也是因為這兩個TPU。Gemini的本意是雙子座,代表的是希臘神話中的天神宙斯與斯巴達王後勒達所生的雙胞胎卡斯托耳和波魯克斯。TPU v4和TPU v5e某種意義上也是雙胞胎,因此命名為Gemini。當然,另外有一種可能是開發者特別喜歡《聖鬥士星矢》,裡面黃金十二宮篇大BOSS就是雙子座的撒加,絕招是銀河星爆。不過筆者覺得後者的可能性低一點。
還有一點,伺服器最大的成本來自於營運和維護。但是在這種規模下,使用傳統的定期對持久集群儲存進行權重檢查點操作的方法,是不可能保持高吞吐量的,畢竟要週期地關閉重啟某個機組。所以對於Gemini,Google使用模型狀態的冗餘記憶體副本,並且在任何計劃外的硬體故障時,可以直接從完整的模型副本中快速恢復。與PaLM和PaLM-2比,儘管使用了大量的訓練資源,但這大大加快了恢復時間。結果,最大規模的培訓工作的總體產出從85%增加到97%。
Google Gemini背後的伺服器群組也是第一款支援嵌入的硬體的超級電腦。嵌入是一種比較貼近Google業務的演算法。嵌入本身是一種相對低維度的空間,模型可以將高維度向量轉換為這種低維度空間。藉助嵌入,可以更輕鬆地對表示字詞的稀疏向量等大型資料輸入進行機器學習。理想情況下,嵌入會將語義上相似的輸入置於嵌入空間中彼此靠近的位置,以捕獲輸入的一些語義。
嵌入是廣告、搜尋排名、YouTube和Google Play中使用的深度學習推薦模型(DLRM)的關鍵組成部分。每個TPU v4都包含第三代稀疏核心資料流處理器,可將依賴嵌入的模型加速5至7倍,但僅使用5%的晶片面積和功耗。
嵌入處理需要大量的端到端通信,因為嵌入分布在在模型上協同工作的TPU晶片周圍。這種模式強調共享記憶體互連的頻寬。這就是TPU v4使用3D環面互連的原因(相對於TPU v2和v3使用2D環面)。TPU v4的3D環面提供了更高的二等分帶寬,即跨越互連中間從一半晶片到另一半的頻寬,以幫助支援更多數量的晶片和更好地展現稀疏核心性能。
無疑問,Google是一家軟體公司,GoogleGemini是一款軟體產品,但是Google勝就勝在硬體上。Google強調Gemini是功能強大的多模態模型(Multimodal Model)。多模態指的是結合了多種感官輸入形式來做出更明智的決策,相當於模型可以用複雜、多樣和非結構化的資料來求解。
一個短視訊(360p到1080p)的資料量大約幾十mb到幾百mb,一條語音的資料量約為幾百kb,一行文字的資料量約為幾b。對於傳統的大語言模型,如果只處理文字訊息,那麼對伺服器的負載要求不會很高,畢竟資料量小。可是一旦將影片、圖片等一併處理,那麼伺服器的載重就會成指數倍增長。事實上不是其他模型不能弄多模態,是其他伺服器扛不住這麼大資料量,硬體拖了軟體的後腿。Google 之所以敢弄,更多的原因是TPU v4和TPU v5e在大規模串聯的場景下,高載荷高MFU無疑是Google的絕招。
然而Google並不能高興太早,首先英偉達的張量計算GPU H200再過些日子就要發售了。像Open AI這樣的大客戶估計是第一時間就能拿到手。到時候GPT無論是推理還是訓練,都可能會來到一個非常誇張的量級。
其次,微軟也出手了。2019年時,微軟啟動了一個名為雅典娜的計畫。透過設計和開發客製化人工智慧晶片,以滿足訓練大型語言模型和驅動人工智慧應用的獨特需求。而且雅典娜和TPU相似,也是內部項目,能夠減少對輝達等第三方硬體供應商的依賴。雅典娜是一個極其神祕的項目,它的性能是多少、外觀怎樣,外界一概不知。唯一能夠了解的,是有些幸運的Open AI員工已經開始對雅典娜測試了。
雖然不清楚H200和雅典娜具體能為Open AI帶來哪些變化,不過可以確定的是,Google以及Google Gemini壓力都挺大的。
TPU對Google意味什麼?
說到Google的TPU還有一個小故事,TPU的全名為Tensor Processing Unit,中文是張量處理單元,是Google開發的專用積體電路(ASIC),專門用於加速機器學習。雖然在公眾視野中,Google是2016年5月的I/O大會上宣布使用TPU,但實際在2015年的時候TPU就已經問世。
神經網路翻譯技術從2014年9月提出,百度2015年5月上線首個網路NMT系統(神經網路機器翻譯系統)。NMT技術克服了傳統方法將句子分割為不同片段進行翻譯的缺點,而是充分利用上下文訊息,對句子進行整體的編碼和解碼,進而產生更為流暢的譯文。
但以當時的技術,神經翻譯對伺服器造成的負載壓力非常大,主要當時硬體沒那麼強大,也沒有H100、A100這樣的產品。從發表的論文和GoogleBlog來看,Google其實已經在當時具備了這樣的技術,沒有使用的核心原因就是硬體遭不住。經過大約半年的測試,TPU已經可以完美適應到伺服器中,做為演算法加速器使用。那到了I/O大會那天,Google 一咬牙一跺腳,「我們也有NMT了!」
Google的TPU最早是不對外開放的,直到2018年才開始有雲端TPU業務。就是用戶可以在雲端購買TPU,來快速解決需要張量運算的業務。2022年的時候,Google雲端更新了TPU v4業務,這意味著現在用戶也可以購買並使用上文提到的各種技術來享受更高的推理和訓練能力。
Google和Open AI最大的不同在於,前者有很強的業務要求,Google Gemini不會是一個賺錢的工具,它對絕大多數人來說更像是個新鮮的高科技玩具。但雲端TPU v4就不一樣了,截至3月31日的季度,Google雲端業務的營收為74億美元,營運利潤為1.91億美元,利潤率為2.5%。Google雲端業務實現首次獲利,但是利潤率還是太低,尤其是比較亞馬遜雲端28%的利潤。所以雲端TPU就成為了Google業務的一個大型成長點,一旦Google Gemini的效果反應良好,那麼對Google雲端TPU業務的推廣來說,無疑是絕招。
(本文由 授權轉載;首圖來源:)
延伸閱讀:

標題:Gemini 背後,Google 真正可怕之處不是模型本身
地址:https://www.utechfun.com/post/302604.html