文章轉載來源:AIGC
文章來源:新智元
ChatGPT用它自己的方式來理解世界,類似的技術是否也能用來學習動物的語言?
 圖片來源:由無界 AI生成
圖片來源:由無界 AI生成
在《獅子王》、《瘋狂動物城》等以動物爲中心的作品中,作者經常會將角色擬人化,用人類的思考和交流方式來推進劇情。
不過,這類作品也會導致認知失調,當我們與動物進行交流時,可能會把自己的想法和偏見投射到動物身上,例如‘羊羔跪乳’與感恩、孝道無關,而是因爲羊特殊的胃部構造,但人類會把自身投射到羊羔的行爲上。

傳統的動物認知工作主要是建立一個詞匯表,但比如‘水’、‘喝’、‘幹燥’等概念在水生生物的世界中可能不存在或沒有意義,在動物交流中也就不存在和人類概念之間的對應;並且動物之間的交流也並不一定通過發聲,還包括手勢、動作序列或皮膚紋理的變化等。
從理論上講,機器學習模型要比人類要更擅長總結出詞匯之間松散的相關性,神經網絡的輸入不對輸入數據的性質做任何假設,只要某種模式頻繁出現,就有可能發現動物交流中蕴含的信息。
由紐約城市大學、、UC伯克利、MIT、哈佛、谷歌研究院和《國家地理》等研究機構發起的鯨語翻譯計劃(Cetacean Translation Initiative, CETI),使用自然語言處理系統分析海量抹香鯨數據,並計劃未來與野外抹香鯨直接對話。
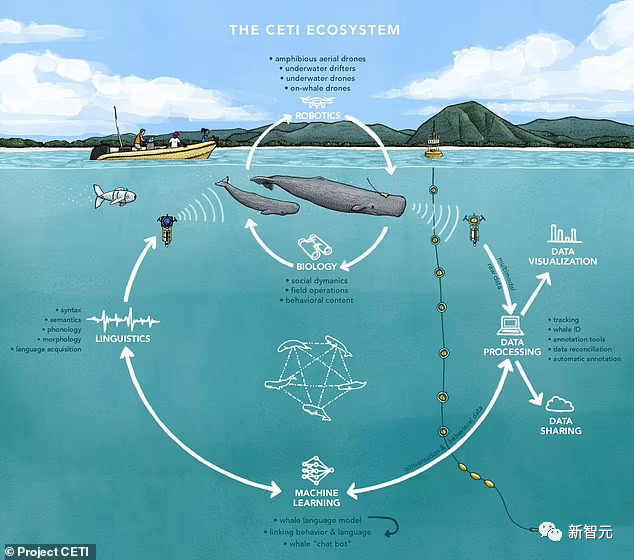
Aza Raskin等人聯合創立的地球物種項目(Earth Species Project,ESP)开源了首個動物發聲基准BEANS,可以測量機器學習算法在生物聲學數據上的性能;還开發了首個用於動物發聲的基礎模型AVES,可用於如信號檢測和分類等各種任務。
隨着生成式AI技術的進步,或許某天我們真有可能揭开動物交流背後的真正含義。
復雜的動物王國
1974年,哲學家托馬斯·內格爾發表了一篇开創性的論文,名爲《當蝙蝠是什么感覺?》(What Is It Like to Be a Bat?”),他認爲,蝙蝠的生活與人類的生活有着非常大的差異,以至於人類可能永遠無法真正知道這個問題的答案。
我們對世界的理解是由人類的概念塑造的,想要知道蝙蝠是什么樣子的唯一方法就是成爲蝙蝠,並擁有蝙蝠的概念。
不過,我們還是可以推測出蝙蝠的部分思維方式,比如蝙蝠生活在高處,可能上下的概念是顛倒的,通過回聲定位等,但我們無法擁有蝙蝠的生活體驗。
如果獅子會說話,我們也無法理解它,因爲人類的大腦無法共情獅子語言中所傳達的感受和概念。——Ludwig Wittgenstein

但並非所有動物的思維都與人類迥然不同,從心理上講,人類與其他靈長類動物的共同點比章魚和魷魚更多:人類與黑猩猩的最後一個共同祖先生活在600萬到800萬年前,而與章魚的最後一個共同祖先生活在大約6億年前的前寒武紀海洋中。
經過教導後,黑猩猩可以學會人類的手語,甚至能夠理解復雜的人類指令,並使用鍵盤符號進行交流,但也正如开頭所說的,我們可能也過度擬人化地理解了猩猩的行爲。
對於與人類關系更遠的物種,理解他們的交流方式則變得更困難,例如蜜蜂和一些鳥類可以看到可見光譜中的紫外线,蝙蝠、海豚、狗和貓能聽到超聲波等,每個物種都有其獨特性。
用AI理解動物
地球物種項目(Earth Species Project)的計算機科學家Britt Selvitelle表示,他們正在努力破譯第一種非人類語言,並且有可能在五到十年內實現。
在動物語言領域,雖然研究人員數十年來已經積累了大量知識,但世界上還並不存在一塊能夠翻譯人類語言和動物語言的‘羅塞塔石碑’,也就不存在‘動物語言’的標注金標准。
從根本上說,人工智能是一種數據驅動的工具,預訓練語言模型可以通過海量數據,以無監督的形式學習到數據的內部表徵。
從ChatGPT強大的表現來看,生成式AI技術可能有自己獨特的內部表徵方法,而非套用人類的概念,所以研究人員开始轉向AI技術來分析數據,獲取對動物有意義的術語。

在地球物種項目中,收集的數據形式包括聲音、運動和視頻,涵蓋野外或圈養環境中的動物,數據中還附有生物學家對動物當時在做什么和在什么背景下做什么的注釋。
隨着物聯網的成熟,將廉價可靠的記錄設備(如麥克風或生物記錄儀)放在野外動物身上也越來越容易,可以提供大量數據供人工智能工具進行組織和分析,以幫助發現數據背後的意義,然後使用生成式方法進行測試,最終實現重新創建動物的聲音,進行雙向交流。
動物聲音基准BEANS
在生物聲學領域,基於機器學習技術的成功應用需要在特定任務上精心策劃出一組高質量數據,但在此之前還不存在一個涵蓋多任務、多物種的公共基准,無法以受控和標准化的方式測量機器學習技術的性能並將新提出的技術與現有技術進行基准測試。

論文鏈接:https://arxiv.org/pdf/2210.12300.pdf
數據鏈接:https://github.com/earthspecies/beans
BEANS((the BEnchmark of ANimal Sounds,動物聲音的基准)是一個生物聲學任務和公共數據集的集合,專門用於測量生物聲學領域機器學習算法的性能,包括生物聲學中的兩個常見任務:分類和檢測。
BEANS中包括12個數據集,涵蓋多個物種,包括鳥類、陸地和海洋哺乳動物、無尾兩棲動物和昆蟲。
除了數據集,文中還提出了一組標准機器學習方法的性能作爲任務性能的基线。
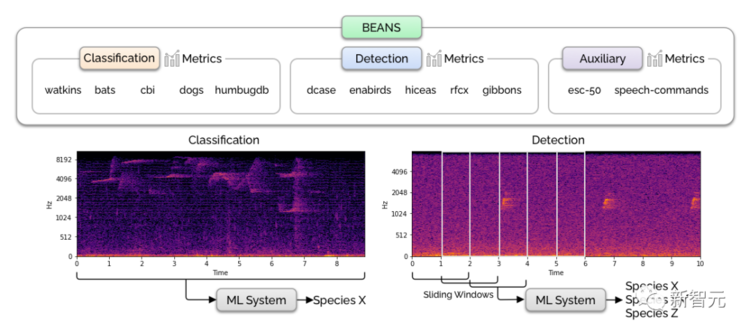
基准和基线代碼都已开源公开,研究人員希望BEANS可以爲基於機器學習的生物聲學研究建立一個新的標准數據集。
動物發聲大模型AVES
在生物聲學領域,由於缺乏標注好的訓練數據,極大阻礙了該領域以有監督方式訓練的大規模神經網絡模型的使用。
爲了利用大量未標注的音頻數據,研究人員提出了AVES(Animal Vocalization Encoder based on Self-Supervision,基於自我監督的動物發聲編碼器),一種自監督的、基於Transformer模型的音頻表徵模型,可用於編碼動物發聲。

論文鏈接:https://arxiv.org/pdf/2210.14493.pdf
模型鏈接:https://github.com/earthspecies/aves
研究人員在一組不同的無標注音頻數據集上對AVES模型進行預訓練,並針對下遊生物聲學任務對模型進行微調。
分類和檢測任務的綜合實驗表明,AVES優於所有強基线,甚至優於在帶注釋的音頻分類數據集上訓練的有監督topline模型。
實驗結果還表明,精心設計出一個與下遊任務相關的小訓練子集是訓練高質量音頻表示模型的有效方法。
倫理問題
1970年代,當西方社會第一次發現鯨魚的歌聲後,人類社會暫停了對深海鯨魚的捕殺,並促成了環境保護局(Environmental Protection Agency)的成立。

隨着地球物種項目技術路线圖的推進,我們可以更了解周圍的生物,進行更多的數據收集,开發新的基准和基礎模型,從而可以更好地保護這顆藍色星球。
Raskin認爲,在未來12-36個月內,團隊就可以實現與動物交流,比如做出一個人造鯨魚或烏鴉,能以一種無法分辨的方式與鯨魚或烏鴉交談,不過關鍵點在於,我們也需要理解模型在說什么,才能進一步對話。
Raskin團隊也在討論如何負責任地使用這些人工智能方法,目前已經規定在任何測試中都要准備好這些方法,技術路线中指出了潛在的風險,如幹擾狩獵和覓食或交配,也可能發送錯誤給動物。
人類是在10萬到30萬年前才學會如何用聲音說話和交流的,而鯨魚和海豚用聲音來傳承文化和歌曲已經有3400萬年歷史了。
如果隨意在鯨群中發送AI音頻,可能會對3400萬年的文化造成破壞。
這就是爲什么到目前爲止,地球物種項目中的大部分工作都是在收集數據和創建基礎,即推動未來進步的基准和基礎模型,與世界各地的公司和組織每天利用人工智能和機器學習所做的事情沒有什么不同,只是規模更宏大。
如果人工智能可以幫助我們理解動物在說什么,那么我們使用人工智能的能力的限制是什么?
如果人工智能可以幫助我們了解動物,那么它會教我們關於人類的什么?

Raskin 和Zacarian希望動物語言的最終翻譯成爲世界歷史上的轉折點之一,就像鯨魚的歌聲首次被發現或1990年藍點(A Pale Blue Dot)的照片一樣,這些時刻改變了我們對世界的看法和理解。
參考資料:
 海量資訊、精准解讀,盡在新浪財經APP
海量資訊、精准解讀,盡在新浪財經APP
責任編輯:張靖笛
標題:能跟「貓主子」聊天了!生成式AI帶來的全面革命:最快5年內破譯第一種動物語言
地址:https://www.utechfun.com/post/290480.html