

讓記憶體內建運算單元的「記憶體內運算」(In-Memory Processing 或 Processing-In-Memory)其實很久以前就提出了,像 2D 繪圖時代一度出現三星「Windows RAM」這種擁有 EDO(Extended Data Out) 存取模式,並內建視窗加速運算電路的改良型雙存取埠 VRAM。
生成式 AI 急速發展當下,對大型語言模型來說,記憶體是巨大挑戰,因這些模型都嚴重受限於記憶體容量和頻寬。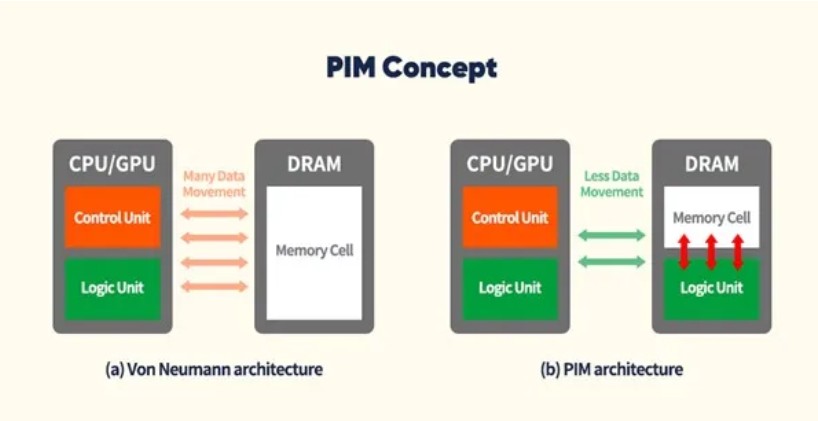
▲ 將運算單元內建至記憶體,可降低傳統程式載入型(Von Neumann)電腦的資料搬運量。
所以 SK 海力士認為,資料中心需要的不只記憶體,還有不同類型產品,包括內建計算功能的特定應用(Domain-Specific)記憶體,將大量運算工作直接於記憶體內搞定。SK 海力士在 Hot Chips 2023(第 35 屆)談論 AiM(Accelerator-in-Memory),就讓我們來看看這間記憶體大廠,葫蘆裡究竟藏什麼藥。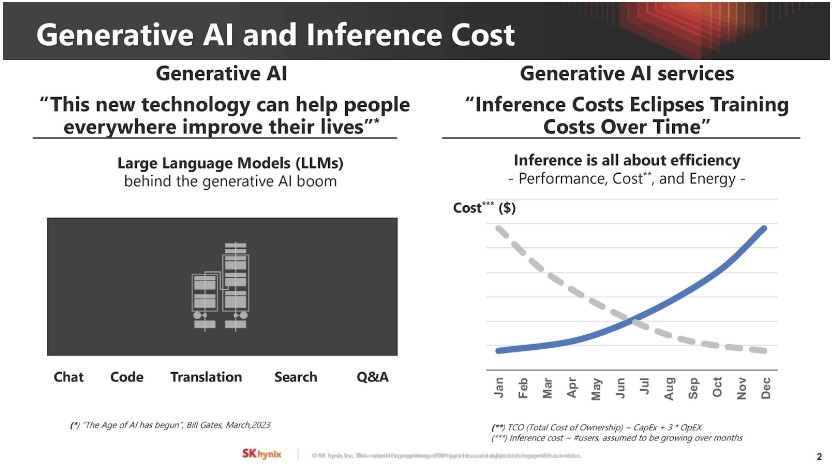
▲ 以大型語言模型為主生成式 AI 形成巨大「推理成本」。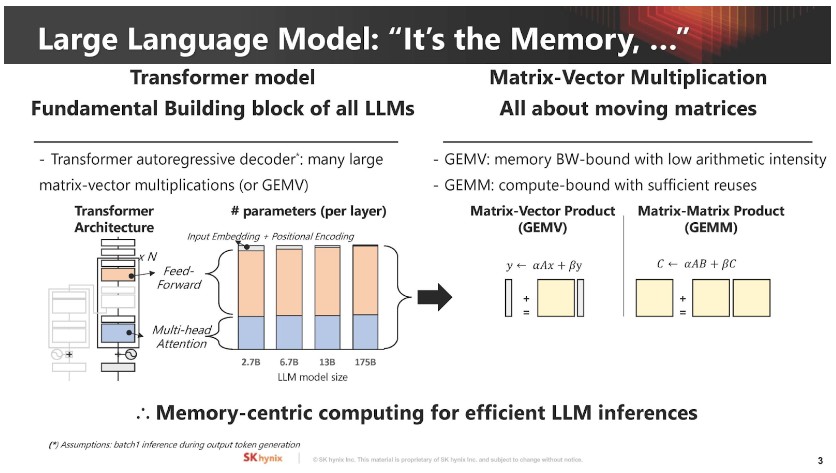
▲ 大型語言模型通常受記憶體容量和頻寬限制,假若能將大型向量矩陣乘積和運算直接交給記憶體處理,問題就可減輕大半。
▲ SK 海力士認為根據不同應用,市場需要多種類記憶體技術,一般運算 DDR5、行動裝置 LPDDR5、繪圖應用 GDDR6 和 AI 訓練 HBM3、外部記憶體儲存池 CXL,還得加上內建計算能力、適用生成式 AI 與大型語言模型的 AiM。
▲ 所以今天 SK 海力士就要談論自家 AiM 了。
▲ 這是 SK 海力士 GDDR6 記憶體內建 16 個時脈 1GHz 運算處理單元(PU,Processing Unit)的 4Gb 顆粒試作品,可處理 BF16 資料格式,每個 Bank 都有配置專屬 PU 以達到完全 Bank 平行度,內部頻寬 512GB/s,理論計算吞吐量 512G Flops。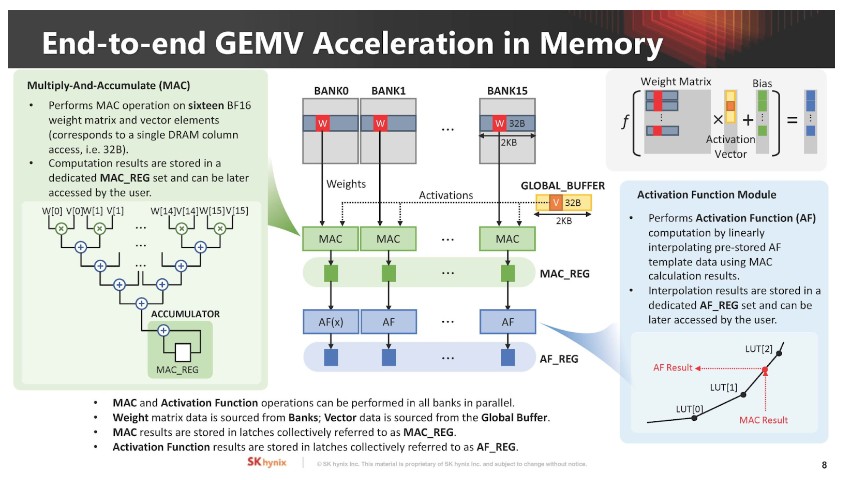
▲ SK 海力士介紹如何記憶體執行 AI GEMV 計算(16 個 BF16 格式的權重矩陣和向量元素),權重矩陣來自 Bank,向量資料則出自全局緩衝區。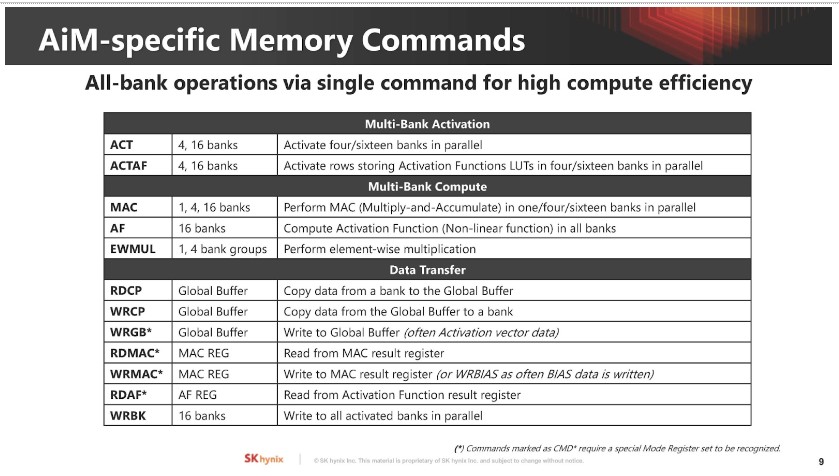
▲ 記憶體內運算的控制命令。
▲ 接著就是展示大型語言模型的記憶體擴展方式及 AiM 計算資源需求。
▲ 這是 AiM 大型語言模型橫向擴展方式,由小到大,由記憶體顆粒到整個系統。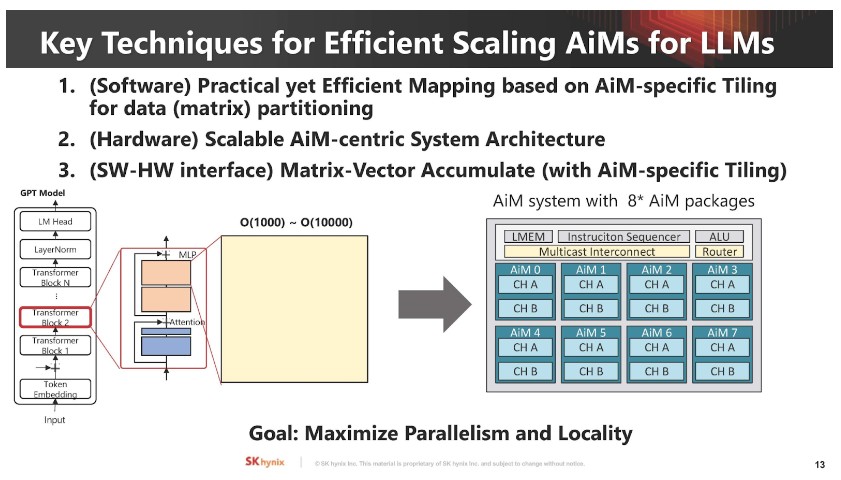
▲ 最大難題還是「軟體要怎麼運用有計算能力的記憶體」。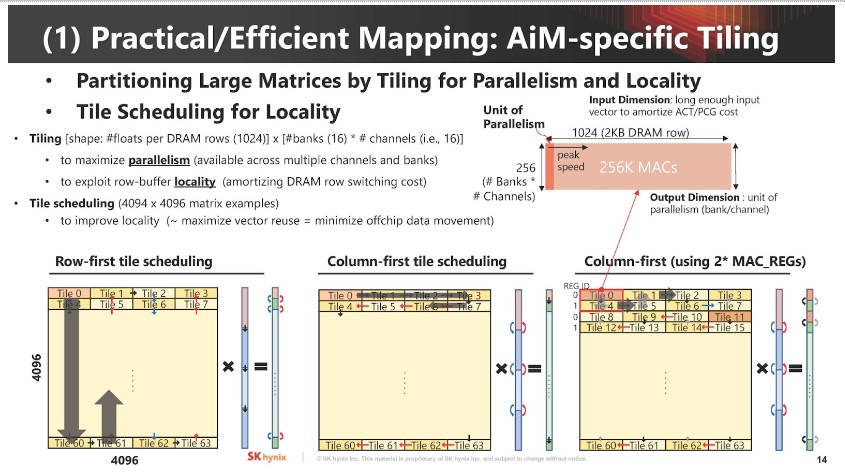
▲ 如何將運算需求「映射」到記憶體內執行單元。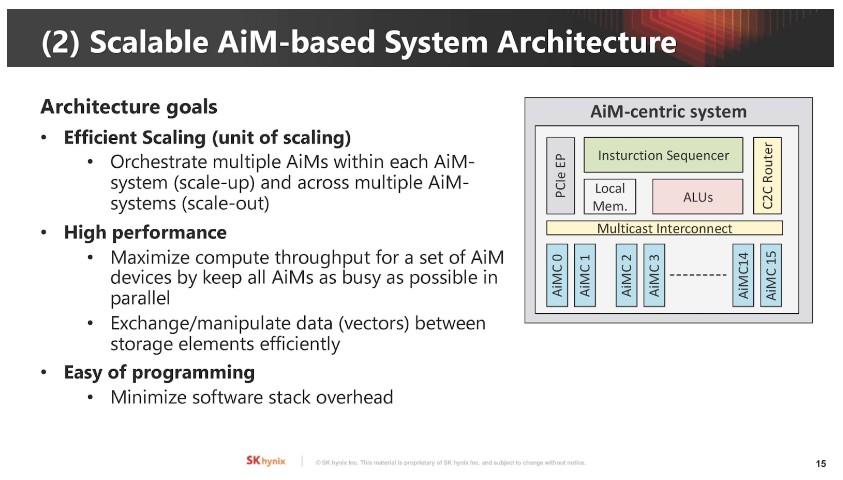
▲ 系統架構同時需要縱向(Scale-Up)和橫向擴展(Scale-Out)。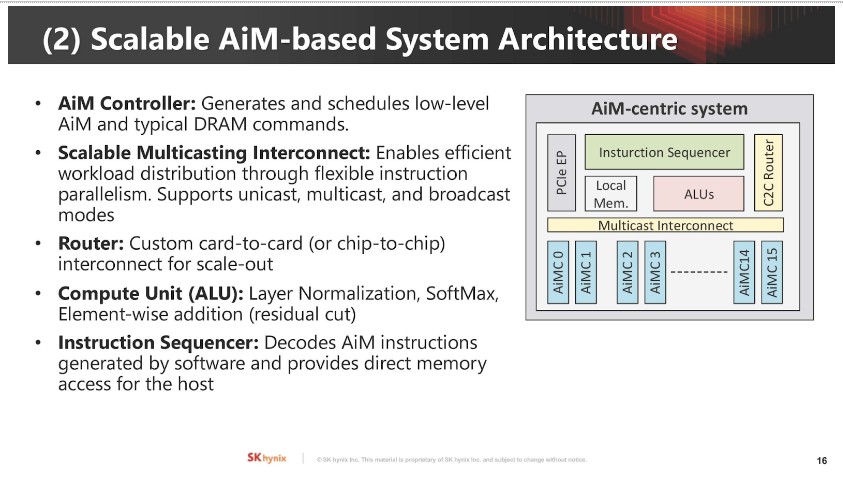
▲ AiM 架構的關鍵元件含 AiM 控制器、可擴展式多播(Multicast)互連、路由器、計算單元及指令排序器。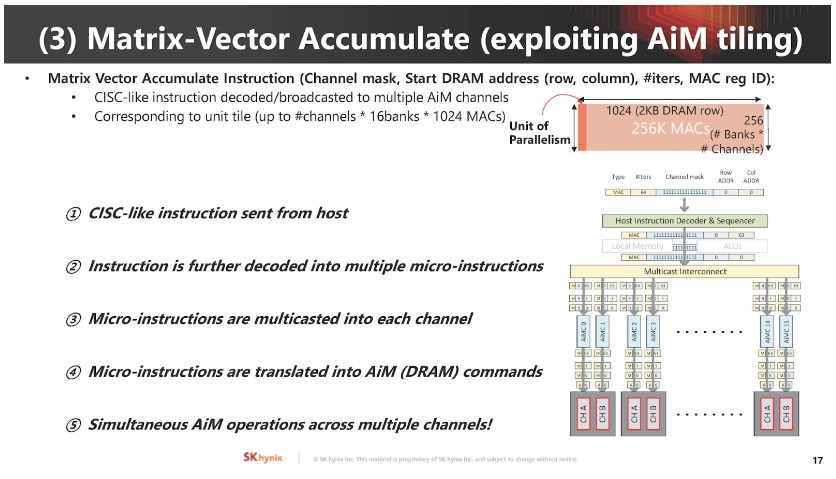
▲ 矩陣向量累加運算是 AI 工作關鍵,AiM 使用類似 CISC 指令集管理這些運作。
▲ 對新運算架構來說,通常可利用細微最佳化手段使其更好。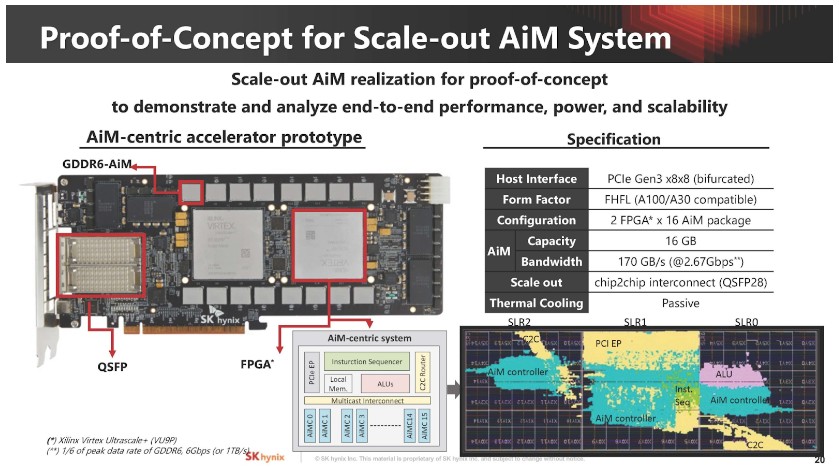
▲ SK 海力士不僅清談 AiM 和展示 4Gb GDDR6-AiM 樣品照片,還進一步使用兩個賽靈思(AMD)FPGA 建置技術驗證平台。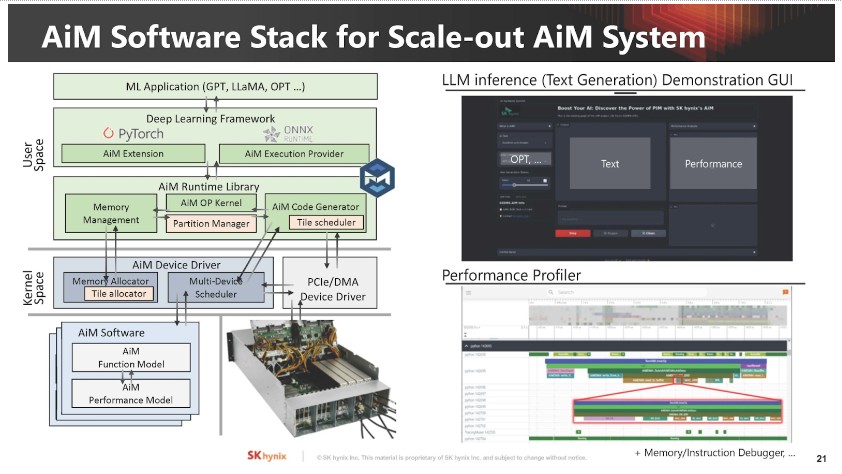
▲ AiM 的軟體堆疊架構。
▲ SK 海力士使用這些軟硬體驗證概念可行性。
▲ SK 海力士 AiM 仍處於技術評估階段,並分析適用場景和解決方案。
說到底,看在將 AI 運算功能整合至記憶體這件事,絕對可替產品「加值」的份上,SK 海力士(和三星)就有足夠動力勇敢嘗試。假以時日,假如記憶體內運算真的搭上 AI 順風車成為有高度可行性的現實,那整個計算機工業的發展將出現天翻地覆的變化。不過就先觀望到底有哪些雲端巨頭對此有興趣吧。
(首圖來源:shutterstock)

標題:Hot Chips 2023》SK 海力士的記憶體內運算技術
地址:https://www.utechfun.com/post/269189.html