“過去的表現並不能保證將來的結果。”這是大多數金融理財模型的小字。
在產品業務內部,這被稱之爲模型漂移、衰退或過時。事情會發生變化,模型性能會隨着時間的推移而下降。最終的衡量標准是模型質量指標,可以是准確率、平均錯誤率,也可以是一些下遊業務的KPI,比如點擊率。
沒有任何模型可以永遠有效,但衰退的速度各不相同。有些產品可以使用多年而無需更新,例如某些計算機視覺或語言模型,或者是在隔離、穩定環境中的任何決策系統,比如常見的實驗條件下。
想要保證模型精度,就需要每天對新數據進行訓練,這是機器學習模型的範式缺陷,也使得人工智能部署,不能像軟件部署一樣可以一勞永逸。後者被創造了幾十年,目前最先進的AI產品,依然使用着早年的軟件技術。只要仍然有用,即時技術已經過時,它們依然可以長存於每一個字節中。
不過被稱爲人工智能最前沿的產品,以ChatGPT爲代表的大模型,在遭遇人氣衰減後,迎來是否正在過時和衰老的質疑。
無風不起浪。用戶在ChatGPT上花費的時間越來越少,從3月份的8.7分鐘降至8月份的7分鐘。側面反映出,當大模型工具的供給側迅猛增長,僅僅只是生產力工具的ChatGPT似乎並不足以成爲主流使用人群Z世代的心頭好。
一時的人氣不足以動搖致力於成爲AI時代應用商店的OpenAI霸主地位。更核心的問題是,ChatGPT生產力的老化,才是不少老用戶信任度下降的主因。自5月份开始,OpenAI論壇裏討論GPT-4性能不如以前的帖子,就一直在發酵。
那么ChatGPT過時了嗎?以ChatGPT爲代表的大模型會像過去的機器學習模型一樣衰老嗎?不理解這些問題,就不能在層出不窮的大模型熱潮之下,找到人與機器的可持續發展之道。
ChatGPT過時了嗎?
來自Salesforce AI軟件服務商最新的一份數據顯示,有67%的大模型使用者是Z世代或者千禧一代;很少使用生成AI或在這方面落伍的人群中,68%以上的人是X一代或嬰兒潮一代。
代際差異說明Z世代正在成爲擁抱大模型的主流人群。Salesforce產品營銷人員Kelly Eliyahu表示:“Z世代實際上是AI一代,他們構成了超級用戶群體。70%的Z世代正在使用生成式AI,至少有一半的人每周或更長時間使用它。”
不過作爲大模型產品的領軍者,ChatGPT在Z世代人群中的表現並不出色。

根據市場調研機構Similarweb 7月份的數據顯示,ChatGPT在Z世代人群中的使用佔比爲27%,低於4月份的30%。作爲對比,另外一款可以讓用戶自己設計人工智能角色的大模型產品,Character.ai在18-24歲年齡段的人群中滲透率爲60%。
得益於Z世代的追捧,Character.ai的iOS和Android應用程序目前在美國的月活躍用戶數爲420萬,距離移動端ChatGPT的600萬月活,日益接近。
和ChatGPT的對話式AI不一樣,Character.AI在此基礎上加入個性化、UGC兩大核心功能,使其有了比前者更豐富的使用場景。
一方面,用戶可以根據個人需求自定義AI角色,滿足Z世代個性化定制的需求。同時這些用戶自主創建的AI角色,也可以被平台所有用戶使用,構建AI社區氛圍。比如此前在社交媒體平台傳播出圈的蘇格拉底、God等虛擬人物,以及官方自主創建的馬斯克等商業名人的AI形象。
另一方面,個性化的深度定制+群聊功能,也使得用戶對於平台產生情感智能依賴。很多社交媒體平台的用戶公开評價顯示,因爲聊天體驗過於逼真,就像“自己創作的角色擁有生命,就像在與真人交談”,“是迄今爲止最接近假想朋友、守護天使的東西”。
可能是來自Character.AI的壓力,2023年8月16日OpenAI在官網發布了一則簡短聲明,宣布收購美國初創企業Global Illumination,並將整個團隊納入麾下。這家僅有兩年歷史八位員工的小公司,主營業務是利用人工智能創建巧妙工具、數字基建和數字體驗。
收購行爲的背後,很可能意味着OpenAI將致力以豐富的方式,改善目前的大模型數字體驗。
人工智能的衰老化
ChatGPT在大模型數字體驗層面的老化,影響了其殺時間的效果。作爲生產力工具,其生成結果准確性的飄忽不定,也正在影響其用戶黏性。
此前根據Salesforce的調查顯示,有近六成的大模型使用者認爲,他們正在通過累計時間的訓練掌握這項技術。不過目前這種技術的掌握,正在隨着時間的遷移發生變化。
早在5月份,就有大模型老用戶在OpenAI論壇上开始抱怨GPT-4,“在以前表現良好的事物上表現出困難”。據《Business Insider》7月份報道稱,很多老用戶將GPT-4與其以前的推理能力和其他輸出相比,形容爲“懶惰”和“愚笨”。
由於官方並未對此作出回應,人們开始對GPT-4性能下降的原因進行推測,會不會是因爲此前OpenAI的現金流問題?主流猜測集中在成本優化導致的性能下降方面。一些研究者稱,OpenAI可能在API後面使用了規模較小的模型,以降低運行ChatGPT的成本。
不過這個可能性隨後被OpenAI的產品副總裁Peter Welinder否認。他在社交媒體上表示:“我們沒有讓GPT-4變得更笨,目前的一個假設是,當你更加頻繁地使用它時,會开始注意到之前沒有注意到的問題。”
更多的人、更長時間的使用,暴露了ChatGPT的局限性。對於這種假設,研究者試圖通過更嚴謹的實驗呈現“ChatGPT性能和時間關系的變化”。
來自斯坦福大學和加州大學伯克利分校在7月份提交的一篇題爲《How is ChatGPT's behavior changing over time?》的研究論文顯示:同一個版本的大模型,確實可以在相對較短的時間內發生巨大變化。
從3月份到6月份,研究者測試了GPT-3.5和GPT-4兩個版本,採集了四個常見的基准任務數學問題、回答敏感問題、代碼生成和視覺推理的生成結果,並進行評估。結果顯示,無論是GPT-3.5還是GPT-4,二者的性能和生成結果,都有可能隨時間而變化。
數學能力方面,GPT-4(2023年3月)在識別質數與合數方面表現得相當不錯(84%准確率),但是GPT-4(2023年6月)在相同問題上的表現不佳(51%准確率)。有趣的是,CPT-3.5在這個任務上6月份的表現要比3月份好得多。
不過在敏感問題方面,GPT-4在6月份回答敏感性問題的意愿較3月份下降;代碼能力方面,GPT-4和GPT-3.5,都在6月份表現出比3月份更多的錯誤。研究者認爲,雖然ChatGPT的性能和時間沒有明顯的线性關系,但是准確性確實會飄忽不定。
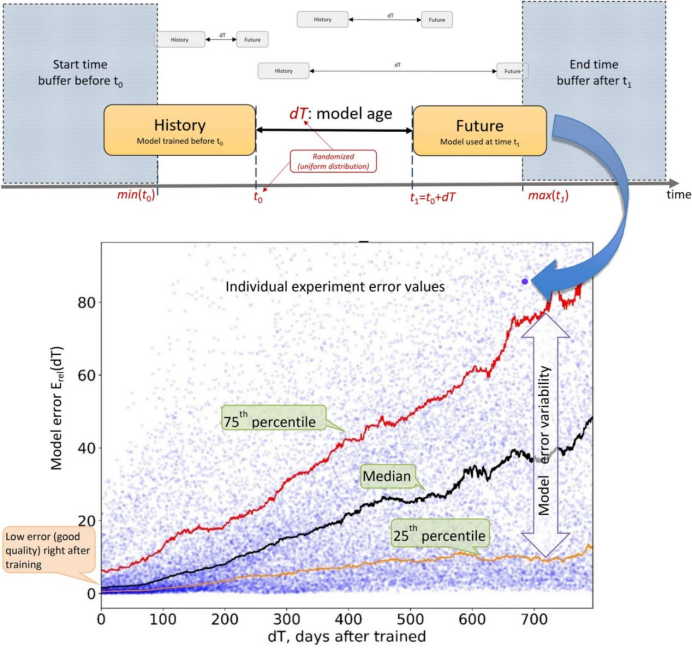
這不僅是ChatGPT自己的問題,也是此前所有AI模型的通病。根據麻省理工學院、哈佛大學、蒙特雷大學和劍橋大學2022年的一項研究表明,91%的機器學習模型都會隨着時間的推移而退化,研究者將這種現象稱爲“人工智能老化”。
例如,Google Health曾經开發了一種深度學習模型,可以通過患者的眼睛掃描來檢測視網膜疾病。該模型在訓練階段的准確率達到90%,但在現實生活中卻無法提供准確的結果。主要是因爲在實驗室,採用高質量的訓練數據,但是現實世界的眼睛掃描質量較低。
受制於機器學習模型老化的情況,過去走出實驗室的AI技術,以單一的語音識別技術爲主,智能音箱等產品因此最先普及。根據美國人口普查局2018年對58.3萬家美國公司的調查,只有2.8%使用機器學習模型來爲其運營帶來優勢。
不過伴隨着大模型智能湧現能力的突破,機器學習模型的老化速度明顯減弱,逐漸走出實驗室面向更廣泛的受衆。不過,湧現能力的黑盒下仍有不可預測性,讓不少人對於ChatGPT能否長期保持AI性能的不斷提升提出質疑。
黑盒下的抗衰老性
人工智能老化的本質,其實是機器學習模型的範式缺陷。
過往,機器學習模型是按照具體任務和具體數據的對應關系進行訓練。通過大量的例子,先教給模型,那個領域中什么是好,什么是壞,再調節一下模型的權重,從而輸出恰當的結果。這種思路下,每做一些新的事情,或者數據分布有明顯變化,都要重新訓練一遍模型。
新事情和新數據無窮無盡,模型就只能刷新。但是模型的刷新也會導致過去做得好的事情突然做不好了,進一步限制應用。總結來看,傳統的機器學習模型中,數據飛輪本質是爲了迭代模型,用新模型解決新問題的範式。
不過以ChatGPT爲代表的大模型,湧現出自主學習能力,突破了這種範式。過往的機器學習,是先“喫”數據,之後“模仿”,基於的是對應關系;ChatGPT類的大模型,是“教”數據,之後“理解”,基於的是“內在邏輯”。
這種情況下,大模型本身不發生變化,理論上可以永葆青春。不過也有從業人士表示,正如大模型的智能湧現一樣,是非线性發展、不可預測的,是突然就有的。對於大模型是否會隨着時間發生衰老,湧現出難以預測的不可確定性也是未知的。
換句話說,ChatGPT在湧現出難以理論化推導的智能性能後,也开始湧現出難以預測的不可確定性。
對於“湧現”的黑盒性,9月6日在百川智能Baichuan2开源大模型發布會上,中國科學院院士、清華大學人工智能研究院名譽院長張鈸表示:“到現在爲止,全世界對大模型的理論工作原理、所產生的現象都是一頭霧水,所有的結論都推導產生了湧現現象。所謂湧現就是給自己一個退路,解釋不清楚的情況下就說它是湧現。實際上反映了我們對它一點不清楚。”
在其看來,大模型爲什么會產生幻覺這個問題,涉及到ChatGPT跟人類自然語言生成原理的不一樣。最根本的區別在於,ChatGPT生成的語言是外部驅動的,而人類的語言是在自己意圖的情況下驅動的,所以ChatGPT內容的正確性和合理性不能保證。
在經歷過一系列概念炒作跟風上車之後,對於致力於开發生產力基礎模型的人來說,面臨的挑战將是如何確保其產品持續輸出結果的可靠性和准確性。
不過對於大模型相關的娛樂產品而言,正如Character.AI 聯合創始人Noam Shazeer在《紐約時報》上所說:“這些系統並不是爲真相而設計的。它們是爲合理的對話而設計的。”換句話說,它們是自信的廢話藝術家。大模型的巨浪已然开始分流。
參考資料:
Gizmodo-Is ChatGPT Getting Worse?
TechCrunch-AlappCharacter.aiiscatchinguptoChatGPTintheUS
Machine Learning Monitoring- Why You Should Care About Data and Concept Drift
M小姐沿習錄-關於ChatGPT的五個最重要問題
清華大學人工智能國際治理研究院-對大模型的研究很迫切,不能解釋不清楚就說“湧現”
“過去的表現並不能保證將來的結果。”這是大多數金融理財模型的小字。
在產品業務內部,這被稱之爲模型漂移、衰退或過時。事情會發生變化,模型性能會隨着時間的推移而下降。最終的衡量標准是模型質量指標,可以是准確率、平均錯誤率,也可以是一些下遊業務的KPI,比如點擊率。
沒有任何模型可以永遠有效,但衰退的速度各不相同。有些產品可以使用多年而無需更新,例如某些計算機視覺或語言模型,或者是在隔離、穩定環境中的任何決策系統,比如常見的實驗條件下。
想要保證模型精度,就需要每天對新數據進行訓練,這是機器學習模型的範式缺陷,也使得人工智能部署,不能像軟件部署一樣可以一勞永逸。後者被創造了幾十年,目前最先進的AI產品,依然使用着早年的軟件技術。只要仍然有用,即時技術已經過時,它們依然可以長存於每一個字節中。
不過被稱爲人工智能最前沿的產品,以ChatGPT爲代表的大模型,在遭遇人氣衰減後,迎來是否正在過時和衰老的質疑。
無風不起浪。用戶在ChatGPT上花費的時間越來越少,從3月份的8.7分鐘降至8月份的7分鐘。側面反映出,當大模型工具的供給側迅猛增長,僅僅只是生產力工具的ChatGPT似乎並不足以成爲主流使用人群Z世代的心頭好。
一時的人氣不足以動搖致力於成爲AI時代應用商店的OpenAI霸主地位。更核心的問題是,ChatGPT生產力的老化,才是不少老用戶信任度下降的主因。自5月份开始,OpenAI論壇裏討論GPT-4性能不如以前的帖子,就一直在發酵。
那么ChatGPT過時了嗎?以ChatGPT爲代表的大模型會像過去的機器學習模型一樣衰老嗎?不理解這些問題,就不能在層出不窮的大模型熱潮之下,找到人與機器的可持續發展之道。
ChatGPT過時了嗎?
來自Salesforce AI軟件服務商最新的一份數據顯示,有67%的大模型使用者是Z世代或者千禧一代;很少使用生成AI或在這方面落伍的人群中,68%以上的人是X一代或嬰兒潮一代。
代際差異說明Z世代正在成爲擁抱大模型的主流人群。Salesforce產品營銷人員Kelly Eliyahu表示:“Z世代實際上是AI一代,他們構成了超級用戶群體。70%的Z世代正在使用生成式AI,至少有一半的人每周或更長時間使用它。”
不過作爲大模型產品的領軍者,ChatGPT在Z世代人群中的表現並不出色。

根據市場調研機構Similarweb 7月份的數據顯示,ChatGPT在Z世代人群中的使用佔比爲27%,低於4月份的30%。作爲對比,另外一款可以讓用戶自己設計人工智能角色的大模型產品,Character.ai在18-24歲年齡段的人群中滲透率爲60%。
得益於Z世代的追捧,Character.ai的iOS和Android應用程序目前在美國的月活躍用戶數爲420萬,距離移動端ChatGPT的600萬月活,日益接近。
和ChatGPT的對話式AI不一樣,Character.AI在此基礎上加入個性化、UGC兩大核心功能,使其有了比前者更豐富的使用場景。
一方面,用戶可以根據個人需求自定義AI角色,滿足Z世代個性化定制的需求。同時這些用戶自主創建的AI角色,也可以被平台所有用戶使用,構建AI社區氛圍。比如此前在社交媒體平台傳播出圈的蘇格拉底、God等虛擬人物,以及官方自主創建的馬斯克等商業名人的AI形象。
另一方面,個性化的深度定制+群聊功能,也使得用戶對於平台產生情感智能依賴。很多社交媒體平台的用戶公开評價顯示,因爲聊天體驗過於逼真,就像“自己創作的角色擁有生命,就像在與真人交談”,“是迄今爲止最接近假想朋友、守護天使的東西”。
可能是來自Character.AI的壓力,2023年8月16日OpenAI在官網發布了一則簡短聲明,宣布收購美國初創企業Global Illumination,並將整個團隊納入麾下。這家僅有兩年歷史八位員工的小公司,主營業務是利用人工智能創建巧妙工具、數字基建和數字體驗。
收購行爲的背後,很可能意味着OpenAI將致力以豐富的方式,改善目前的大模型數字體驗。
人工智能的衰老化
ChatGPT在大模型數字體驗層面的老化,影響了其殺時間的效果。作爲生產力工具,其生成結果准確性的飄忽不定,也正在影響其用戶黏性。
此前根據Salesforce的調查顯示,有近六成的大模型使用者認爲,他們正在通過累計時間的訓練掌握這項技術。不過目前這種技術的掌握,正在隨着時間的遷移發生變化。
早在5月份,就有大模型老用戶在OpenAI論壇上开始抱怨GPT-4,“在以前表現良好的事物上表現出困難”。據《Business Insider》7月份報道稱,很多老用戶將GPT-4與其以前的推理能力和其他輸出相比,形容爲“懶惰”和“愚笨”。
由於官方並未對此作出回應,人們开始對GPT-4性能下降的原因進行推測,會不會是因爲此前OpenAI的現金流問題?主流猜測集中在成本優化導致的性能下降方面。一些研究者稱,OpenAI可能在API後面使用了規模較小的模型,以降低運行ChatGPT的成本。
不過這個可能性隨後被OpenAI的產品副總裁Peter Welinder否認。他在社交媒體上表示:“我們沒有讓GPT-4變得更笨,目前的一個假設是,當你更加頻繁地使用它時,會开始注意到之前沒有注意到的問題。”
更多的人、更長時間的使用,暴露了ChatGPT的局限性。對於這種假設,研究者試圖通過更嚴謹的實驗呈現“ChatGPT性能和時間關系的變化”。
來自斯坦福大學和加州大學伯克利分校在7月份提交的一篇題爲《How is ChatGPT's behavior changing over time?》的研究論文顯示:同一個版本的大模型,確實可以在相對較短的時間內發生巨大變化。
從3月份到6月份,研究者測試了GPT-3.5和GPT-4兩個版本,採集了四個常見的基准任務數學問題、回答敏感問題、代碼生成和視覺推理的生成結果,並進行評估。結果顯示,無論是GPT-3.5還是GPT-4,二者的性能和生成結果,都有可能隨時間而變化。
數學能力方面,GPT-4(2023年3月)在識別質數與合數方面表現得相當不錯(84%准確率),但是GPT-4(2023年6月)在相同問題上的表現不佳(51%准確率)。有趣的是,CPT-3.5在這個任務上6月份的表現要比3月份好得多。
不過在敏感問題方面,GPT-4在6月份回答敏感性問題的意愿較3月份下降;代碼能力方面,GPT-4和GPT-3.5,都在6月份表現出比3月份更多的錯誤。研究者認爲,雖然ChatGPT的性能和時間沒有明顯的线性關系,但是准確性確實會飄忽不定。
這不僅是ChatGPT自己的問題,也是此前所有AI模型的通病。根據麻省理工學院、哈佛大學、蒙特雷大學和劍橋大學2022年的一項研究表明,91%的機器學習模型都會隨着時間的推移而退化,研究者將這種現象稱爲“人工智能老化”。
例如,Google Health曾經开發了一種深度學習模型,可以通過患者的眼睛掃描來檢測視網膜疾病。該模型在訓練階段的准確率達到90%,但在現實生活中卻無法提供准確的結果。主要是因爲在實驗室,採用高質量的訓練數據,但是現實世界的眼睛掃描質量較低。
受制於機器學習模型老化的情況,過去走出實驗室的AI技術,以單一的語音識別技術爲主,智能音箱等產品因此最先普及。根據美國人口普查局2018年對58.3萬家美國公司的調查,只有2.8%使用機器學習模型來爲其運營帶來優勢。
不過伴隨着大模型智能湧現能力的突破,機器學習模型的老化速度明顯減弱,逐漸走出實驗室面向更廣泛的受衆。不過,湧現能力的黑盒下仍有不可預測性,讓不少人對於ChatGPT能否長期保持AI性能的不斷提升提出質疑。
黑盒下的抗衰老性
人工智能老化的本質,其實是機器學習模型的範式缺陷。
過往,機器學習模型是按照具體任務和具體數據的對應關系進行訓練。通過大量的例子,先教給模型,那個領域中什么是好,什么是壞,再調節一下模型的權重,從而輸出恰當的結果。這種思路下,每做一些新的事情,或者數據分布有明顯變化,都要重新訓練一遍模型。
新事情和新數據無窮無盡,模型就只能刷新。但是模型的刷新也會導致過去做得好的事情突然做不好了,進一步限制應用。總結來看,傳統的機器學習模型中,數據飛輪本質是爲了迭代模型,用新模型解決新問題的範式。
不過以ChatGPT爲代表的大模型,湧現出自主學習能力,突破了這種範式。過往的機器學習,是先“喫”數據,之後“模仿”,基於的是對應關系;ChatGPT類的大模型,是“教”數據,之後“理解”,基於的是“內在邏輯”。
這種情況下,大模型本身不發生變化,理論上可以永葆青春。不過也有從業人士表示,正如大模型的智能湧現一樣,是非线性發展、不可預測的,是突然就有的。對於大模型是否會隨着時間發生衰老,湧現出難以預測的不可確定性也是未知的。
換句話說,ChatGPT在湧現出難以理論化推導的智能性能後,也开始湧現出難以預測的不可確定性。
對於“湧現”的黑盒性,9月6日在百川智能Baichuan2开源大模型發布會上,中國科學院院士、清華大學人工智能研究院名譽院長張鈸表示:“到現在爲止,全世界對大模型的理論工作原理、所產生的現象都是一頭霧水,所有的結論都推導產生了湧現現象。所謂湧現就是給自己一個退路,解釋不清楚的情況下就說它是湧現。實際上反映了我們對它一點不清楚。”
在其看來,大模型爲什么會產生幻覺這個問題,涉及到ChatGPT跟人類自然語言生成原理的不一樣。最根本的區別在於,ChatGPT生成的語言是外部驅動的,而人類的語言是在自己意圖的情況下驅動的,所以ChatGPT內容的正確性和合理性不能保證。
在經歷過一系列概念炒作跟風上車之後,對於致力於开發生產力基礎模型的人來說,面臨的挑战將是如何確保其產品持續輸出結果的可靠性和准確性。
不過對於大模型相關的娛樂產品而言,正如Character.AI 聯合創始人Noam Shazeer在《紐約時報》上所說:“這些系統並不是爲真相而設計的。它們是爲合理的對話而設計的。”換句話說,它們是自信的廢話藝術家。大模型的巨浪已然开始分流。
參考資料:
Gizmodo-Is ChatGPT Getting Worse?
TechCrunch-AlappCharacter.aiiscatchinguptoChatGPTintheUS
Machine Learning Monitoring- Why You Should Care About Data and Concept Drift
M小姐沿習錄-關於ChatGPT的五個最重要問題
清華大學人工智能國際治理研究院-對大模型的研究很迫切,不能解釋不清楚就說“湧現”
原文標題 : ChatGPT笨了,還是老了?
標題:ChatGPT笨了,還是老了?
地址:https://www.utechfun.com/post/262911.html