技術更先進了,數據庫大了好幾個數量級,大模型可以更方便獲取信息嗎?
文心一言是百度系列產品中除了生活服務之外的所有信息產品的綜合和升級版,從它發布的那一天开始,公司裏大模型和搜索等產品的內部之战也就开始了。
首先猛一看啊,文心一言挺像百度的。

01瀏覽依然重要
大模型出來的第一個產品取名叫ChatGPT,意思是聊天形式的AI機器人,通過與AI問答對話獲取信息和問題答案。
我們先看OpenAI公司的ChatGPT是怎么开始用的:(圖1)
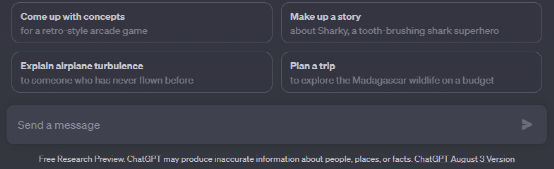
在它的對話框上方有4條隨機出現的提示,每次刷新內容有變化。點擊後會進入這個提示信息和機器人對話的結果。
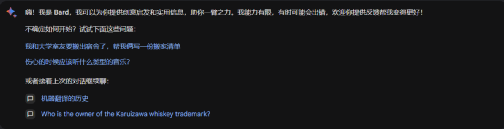
在谷歌的大模型產品Bard,提示信息更爲簡潔,變爲隨機出現兩條,引導用戶理解和使用。(圖2)
微軟必應的聊天機器人也類似,三條提示。(圖3)
在文心一言(手機版)這裏,在對話框主界面之外,增加了兩個功能頁面:社區和發現。
“社區”是帶着用戶名稱和一點點社交屬性的UGC內容頁面,展示用戶用文心一言制作的內容、比如一張圖或者是看圖說話等。剛發布的文心一言,產品的用戶畫像還很初級和粗淺,內容的顯示、規劃邏輯就不那么強烈。
“社區”裏主打的是看內容,用戶邊看內容的同時也許還會模仿着做。這個產品非常類似百度搜索之後的一個战略產品“貼吧”,也是UGC內容的社區。同時也像移動互聯網時代的战略產品“百度百家”,吸引更多用戶和專業機構來自己平台生產內容,以增加信息量和留住用戶。
文心一言應該也期待把貼吧裏強烈活躍的用戶屬性、百度百家的內容生產力搬到自己院子裏來。
“發現”則是一個非常豐富和詳細的幫助工具,和上述ChatGPT、Bard和New Bing三個大模型打开頁面裏的提示語性質類似,但是“發現”的功能頁中有17個分類子目錄,讓用戶則可以在其中找到自己關注的話題(比如“馬斯克”)或者想輕AI幫助自己做的某項工作(比如寫一份“論文大綱”),進入這些需求的對話頁面,就能看到模板案例給出的具體答案了。
在文心一言的網頁版上,對話框頁面之外主要是功能幫助頁“一言百寶箱”,並沒有主打瀏覽的“社區”。原因應該是PC用戶以工作爲主,手機用戶消遣更多、兼顧娛樂和工作。
無論是“社區”還是“發現”,運營方進行內容強推薦、帶有多層目錄索引,這些都非常中國特色、非常百度。
02你會提問嗎?
原因是,搜索產品比瀏覽產品的門檻高。
爲了最多的用戶,需要把產品的門檻做到最低。百度至今把2004年用5000萬元的價格收購的Hao123導航頁放在自己產品目錄的重要位置,同時也會花不少成本把這個頁面鎖定到用戶各種終端的各種瀏覽器的打开頁面上,以方便用戶找到和點擊自己。左劃、下劃、上劃頁面比點擊鏈接更簡單,點擊鏈接比輸入文字更簡單、輸入字詞比輸入句子更簡單,軟件使用習慣劃定了用戶人群的基數和主要特徵。
在一個早期對搜索引擎用戶的習慣統計中,發現輸入一個詞的用戶佔90%以上,輸入兩個關鍵詞或者句子的劇減到10%以內。百度用戶的這個特點應該是公司早期的第一大認知,於是,百度貼吧、新聞、文庫、百家、經驗等一批重量級的分類內容產品,出現在百度的各個產品的各種層級的頁面裏。
與此同時,也養就了更懶惰和挑剔的用戶。以主動搜索、查詢和挑選內容的搜索引擎產品,變成了更方便更不用動腦的瀏覽式內容產品。用戶對內容的依賴度,反過來平台對用戶的影響力,也越來越重了。
和搜索引擎不同,文心一言是聊天機器人,比搜索引擎需要更多的輸入,使用難度未必增加了多少,但使用習慣顯然是不一樣了。大模型的使用門檻高於搜索引擎,搜索引擎高於瀏覽型內容,瀏覽型內容高於平台主動推送的投喂式產品。
爲什么後來百度受到很多批評?有一個原因是百度有意建設了一批中國人日常所需的信息庫,度娘才是很多人最大的老師。巨大的信息庫肯定存在內容的偏頗甚至錯誤問題,隨着用戶量增大也受到越來越多的關注,批評也隨之增加。
無論如何,百度在建設中國人的知識體系的進程中是留了深深烙印的,愛也好恨也好,總之是分不开了。
建設內容的基因被文心一言給繼承了,文心一言的產品也有向下兼容的特點,未來某一天它推出刷不完的短視頻也不是不可能的事。
表面上看,文心一言需要繼承百度老用戶,开發新用戶,延長用戶的使用時間。實際上還是產品定位問題,如何讓一個內核功能偏向專業、職業用戶的產品,獲得大衆用戶的接受和喜愛?既然大模型無所不能,肯定也是可以ToC的。
所以,在用戶還沒學會或者沒習慣提問的時候,文心一言已經把內容送到你眼前了。
03搜索和問答
今年7月,美國邁阿密大學的徐瑞雲和另外兩名香港的大學生發表了一篇研究論文,《ChatGPT與谷歌:搜索性能和用戶體驗的比較研究》。研究對象分成兩組,分別使用谷歌搜索和ChatGPT的完成任務,三個任務對信息的檢索由易到難:1、查詢一個女宇航員的名字和年齡;2、找兩個城市航班的訂票鏈接;3、確認對一個會議報道內容中三條描述的真僞。
研究結果:lChatGPT組在所有任務上花費的時間都更少,兩組的總體任務表現沒有顯著差異。lChatGPT對不同教育水平的用戶搜索表現進行了分級,擅長回答簡單的問題和提供通用解決方案,但在事實核查、糾正錯誤等方面做得不夠。l與谷歌搜索相比,用戶認爲ChatGPT的 回復具有更高的信息質量。同時在有用性、樂趣和滿意度方面,用戶體驗明顯更好。lChatGPT可能導致用戶過度依賴,並產生或復制錯誤信息。l對谷歌搜索的使用表現,與教育程度正相關。教育水平高意味着抽象思維能力更優秀,對搜索結果的鑑別和再次總結、輸入關鍵詞的能力更高。報告顯示,大模型首先是一個更智能化的搜索引擎:1.它能理解人的自然語言,用句子和用戶多重問答;2.還能把上下文串起來理解;3.更重要的是,可以用一個描述性的語言把搜索的結果展現說出來。
PS:這項實驗需要給一個補充說明,它的三個測試題,都是對一個真實項目相關信息的查找和確認,問題的難易程度基於項目的復雜度,並不需要深入研究和思考。和專業學習、研究以及論文寫作有根本區別。
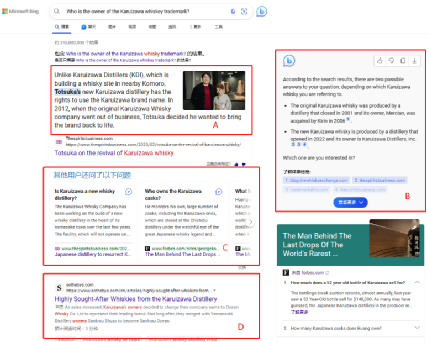
因爲大模型帶來了上述新變化,微軟的必應搜索在產品上很快給出了反饋:(右圖)1.搜索結果給出了最接近問題的內容鏈接,同時給出了內容描述(A區)2.在右側上方,給用戶提供了繼續討論這個問題的對話框(B區)3.篩選出用戶這個事件相類的提問(C區)4.提供傳統搜索引擎給出的內容鏈接列表。
上述現象,給出了現階段查找信息的典型場景:1.利用大模型提出自己的問題;2.得到大模型給出的信息;3.收到大模型對信息的初步分析框架;4.得到大模型對新的綜述文本;5.對大模型給出的信息和框架進行分析(這一步需用戶自行思考、判斷)6.利用搜索引擎再查找源頭信息進行核實、補充和確認。(這一步必須在搜索引擎下完成,以避免大模型再次胡說八道)7.最後還可以要求大模型給一個用戶需要的完整文檔的範本(通常比用戶自己寫的更好)。
必應的搜索引擎帶來的新結果頁面,必然成爲行業關注的重點,它體現了新老技術的融合,結合了大模型的綜述能力和搜索引擎的事實能力。
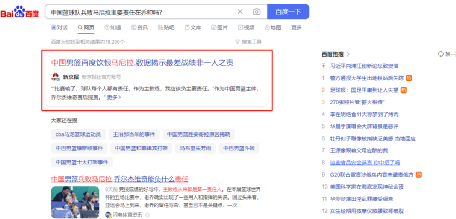
百度對搜索框裏問答式提問,也提供了一個描述性的答案放在第一位(右圖)。谷歌搜索也有類似的處理。應該說大模型和搜索引擎的產品深度融合是看得見的趨勢了。
新老技術和產品的融合,從邏輯上來講毫無問題,但是在一個公司,新老產品线牽涉到不同的員工人事及後台的計算、存儲資源;更關鍵的,是大模型和搜索引擎的融合,不能根本上影響搜索廣告產品和收入。
前者,Meta(Facebook)公司因爲搶奪計算資源和人事處理不當,造成公司收購的法國AI團隊流失大半;而後者,大模型對搜索廣告的影響,對谷歌、對百度來說都還是懸在頭上的達摩克裏斯之劍。如果革命不可避免,那還是自己來,找到更多的主動權。
原文標題 : 文心一言,是百度的葵花寶典還是涅槃重生?
標題:文心一言,是百度的葵花寶典還是涅槃重生?
地址:https://www.utechfun.com/post/261835.html