开源大模型對閉源大模型的衝擊,變得非常猛烈。
今年3月,Meta發布了Llama(羊駝),很快成爲AI社區內最強大的开源大模型,也是許多模型的基座模型。有人戲稱,當前的大模型集群,就是一堆各種花色的“羊駝”。
而就在前些天,Meta又推出了免費可商用版本的“羊駝2號”——Llama2,據說性能比肩GPT-3.5。

這在整個大模型圈都是非常炸裂的。
我們知道,各個互聯網、科技公司都在競相訓練、推出自己的大模型,投入了大量的計算資源和成本,如果不能有效的完成商業化,那么這些大模型就很難回收成本,後續的迭代、更新、升級都成問題,不僅研發企業會虧個底掉,更苦惱的大概就是“前功盡棄”的用戶了。
而現在有了自由开放強大的开源大模型,誰還愿意給閉源大模型送錢呢?
還真的有。
开源是大勢所趨,但閉源大模型依然有其存在意義和商業價值。按照目前的AI產業落地經驗來看,用好大模型,還是得靠閉源。
今天我們就來聊聊這個問題,到底是誰,需要閉源大模型?
到產業去,到產業去
大模型的商業化終點是產業,想必已經是不用過多解釋的共識了。
前不久,我參加某一個國產大模型的內部溝通會,對方高層就明確表示,自己全部用的是閉源代碼,並且堅持走閉源路线,就是考慮到訓練大模型與行業夥伴合作,其中很多隱私數據是不方便开源的。
見一斑可窺全豹,至少在短期內,大模型走向產業,落地還是要靠閉源。
模型方面,閉源大模型的質量更高。
就拿目前最能打的Llama 2爲例,Meta 將 Llama 2 70B 的結果,與閉源模型進行了比較,結果在 MMLU 和 GSM8K 上接近 GPT-3.5,但在編碼基准上,還存在顯著差距,不少數據在多樣性和質量方面有所欠缺。
當然,开源大模型的優化迭代速度很快。但开源的本質和“有性繁殖”很像,就是通過大量繁殖和變異,如同开篇那張“羊駝集群”一樣,面對不確定的未來,借助進化的“優勝劣汰”,讓最優質的後代持續湧現。所以,开源軟件的分支多,對用戶來說,這個選擇的成本是很高的,加上开發人員衆多,版本控制是一個問題。
安全性方面,閉源大模型的可靠性更高。
开源大模型要遵守开源協議,商業使用需要獲得授權,海外开源大模型也要受到屬地管轄,github就曾封禁俄羅斯开發者账號。使用海外开源大模型开發產品,供應鏈的風險,是客觀存在的。
那么,使用國產开源大模型呢?安全性得到保障,但從商業角度看,很多客戶,如大型政企,也非常看重大模型在業務上的可靠性,採購時往往需要大公司的品牌背書。一方面研發投入更大,口碑更高;另一方面,萬一大模型生成不當,導致商業損失或商譽問題,使用閉源大模型可以問責服務商,使用开源大模型總不能找全球开發者算账吧?
比如大模型創業公司Huging Face,爲客戶提供AI咨詢,是开源社區的台柱子,表示有大量客戶希望把自己的私有數據/專業數據用來訓模型,並不想把這些數據給到 OpenAl。

產業化方面,閉源大模型的長期服務能力更強、更可用。
大模型落地,並不是接入API、塞進數據、調參優化就結束了。作爲一種新興技術,大模型與業務場景的融合,還有非常多挑战。比如大模型需要通過蒸餾壓縮,減小模型規模,才能在端側部署,很多企業根本沒有這類專業人才。
再比如,大模型與業務結合,需要產品、運營、測試工程師等多種角色共同參與,這些服務能力是以coder爲主的开源團隊,所很難提供的。此外,大模型的長期應用,算力、存儲、網絡等配套都要跟上,开源社區無法幫助用戶“一站式”解決這些細節問題。
還有數據隱私顧慮,大模型是不能直接爲產業所用的,還要通過專有場景數據進行優化,而這些數據訓練完的模型會被开源开放出去,讓企業顧慮重重。
我們曾採訪過一個智慧醫療研發團隊,對方表示,大量醫療數據分布在各大醫院、研究機構,又涉及患者隱私,大家對於把數據拿出來共同訓練一個行業模型,都存在顧慮。一方面是安全得不到保障,另一方面是自己的數據質量高,但從中得不到恰當的回報,和其他數據質量低的機構一樣,很難協調。在开源大模型的共建中,如何得到數據、把握配方、確定各方貢獻,還存在很多難題。
开源大模型需要平衡技術創新自由和版權收益之間的衝突,而使用閉源大模型就沒有這方面的麻煩,數據和模型的所有權、使用權都很清晰,牢牢掌握在企業自己手裏。
可以說,目前开源大模型還無法達到實際的業務需求。而开源大模型使用者和ISV集成商,是需要獲得商業回報的,如果开源大模型不可商用、效果不好、很難賺錢,那么即使免費,企業也會慎重考慮要不要投入人來开發。
所以,未來一段時間,閉源依然是大模型落地產業的熱門選擇。
到群衆去,到群衆去
可能有人不理解了,开源免費商用,大家都能用上白菜價的大模型了,對开發者和企業用戶多友好,你怎么還說閉源好?是不是爲一門心思賺錢的大廠站台?
非也。
但凡了解开源,都會支持开源。但凡支持开源,都會關注开源的商業化。
中國科學院梅宏院士曾說過,开源以理想主義爲源起,以商業化爲蓬勃助力,是开放創新的典範。沒有商業化,不可能有开源。
所以,开源也好,閉源也好,誰能更早“可商用”,誰就更有未來。這一點上,閉源大模型可能更佔優勢,畢竟有底氣閉源的廠商,還是有兩把刷子和研發家底兒的。
那么,开源大模型的優勢在哪裏呢?如果說閉源大模型要到產業去,那么开源大模型就要到群衆中去,主打一個人多力量大。

(LeCun認爲Llama-v2會改變LLM的市場格局)
开源大模型不同於傳統开源軟件,把源代碼放上去,然後全球开發者來貢獻代碼就完了。大模型的協同共建,更多體現在社區繁榮,大家一起把模型做優化、數據做豐富、工具做完善、應用做全面……
這時候,开源模式能夠帶來幾個好處:
1.技術創新。开源社區可以匯聚廣大科技企業、研究機構和开發者,對模型進行優化、改進、加速迭代,讓模型技術和配套數據集、應用工具等,變得豐富、高質,從而保持領先。
2.人才爭奪。大模型作爲新興技術,人才緊缺,通過开源社區吸引全球優秀人才做貢獻,加速大模型升級,能夠拉开差距。有競爭才有壓力,所以LLama 2發布之後,很快傳出OpenAI也开始考慮半年內开源GPT-3.5的消息,开發者們有福了。
3.生態合攏。目前各行各業的IT解決方案和數字化轉型,大量使用开源技術和應用,建設大模型开源生態,讓IT人才和企業使用相關技術,對於後期的商業化非常有幫助。比如OpenAI 的合作夥伴/投資方微軟,這次也選擇成爲Llama 2 的首要合作夥伴,支持個人开發者和中小公司以最低成本調用Llama 2,這對azure無疑是一大利好。
不是所有开源大模型都能成功,生態是關鍵的護城河。
夾心餅幹,向何處去?
就像手機操作系統的 iOS 與 Andriod,开源與閉源的競爭,並不是某一個領域打的“你死我活”,而是各自走出一條差異化的道路,迎來自己的天地。大模型也是如此。
閉源大模型开門迎客,开源大模型紅紅火火,大家都有光明的未來。
既然如此,爲什么還有專家認爲,Llama 2开源對开源來說是一個巨大的飛躍,但對閉源的大模型公司是一個巨大打擊?
究竟打擊了誰?
答案應該是,既不甘心只做應用層、又沒能力卷過大廠的基礎大模型廠商。
谷歌研究人員曾發文說,因爲有开源社區,我們(Google和OpenAI)沒有護城河。但是,OpenAI還有GPT-4這樣的閉源大模型作爲殺手鐗,只有被开源逼急了的情況下,才考慮把GPT-3.5开源,這裏面是有技術代差的。而且GPT-3.5开源只透露了口風,具體進展還是未知數。
所以,這類頭部科技廠商和雲巨頭,如海外的谷歌、OpenAI,國內的BATH,卡、錢、人才、數據、市場認知度、客戶基礎都有優勢,走閉源路线來完成大模型商業化、產業化是有一定先發優勢和壁壘的。
這就苦了那些一心想訓基礎通用大模型的二三线廠商了。
此前,全球大小科技公司和各類科研機構,一擁而上訓基礎大模型,比如某些機器視覺AI獨角獸,不小心就成了基礎層和應用層之間的“夾心餅幹”。
實力上打不過GPT,成本上打不過Llama,訓出來的基礎通用大模型,還沒等到正式开放商用,就已經過時了,注定是明日黃花。市場上拼不過巨頭,开放度不如开源社區,幾乎不可能收回高昂的开發成本。
趁早放棄死磕大模型,或許才是明智選擇。
比如國內某AI公司的大模型,此前私有化報價是一年30萬,隨後就宣布對學術研究完全开放,獲得授權可免費商用。做大模型开源社區,也有商業化的可能(如Linux/ Android/紅帽),同時也能避免跟頭部的通用大模型的“硬碰硬”。
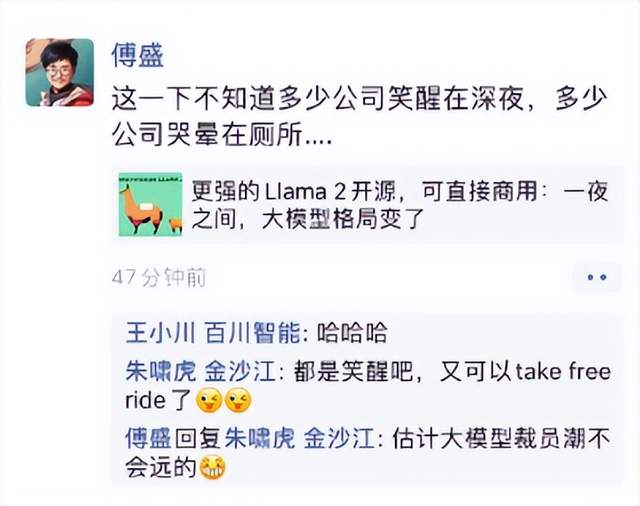
(知名投資人關於Llama2开源的討論截圖/來自網絡)
對於應用層开發者和ISV集成商企業來說,用好產業接受度高的閉源大模型,可以更快讓客戶接受,更適合私有化定制部署的業務需求,更快完成商業落地和收入增長。
對於AI創業公司來說,开源直接就能用,避免重復造輪子,可能是更理想、低成本試錯的商業化手段,“報團取暖”貢獻大模型开源項目,推動大模型开源社區的發展,也會獲得社區回饋和商業回饋。
中國大模型發展到高水平,既要有全球領先的閉源大模型打頭陣,也要有具備世界影響力的大模型开源社區。
道阻且長,行則將至。不妨用建設性心態,來看待开源閉源之爭,給國產閉源大模型一些信心,也給國內开源社區一些鼓勵和支持。
原文標題 : 大模型,开源幹不掉閉源
標題:大模型,开源幹不掉閉源
地址:https://www.utechfun.com/post/242489.html