近期有關中國是否將復刻日本的“資產負債表衰退”的言論不絕於耳,筆者認爲渲染這方面言論的自媒體完全是危言聳聽。
中國的人均GDP才剛剛跨過一萬美元的門檻,進入中等收入國家的行列。我國還沒有發展到類似發達國家經濟滯脹的階段。
事實上,我國目前正處於跨越中等技術陷阱的周期階段,所謂中等技術陷阱,是指發展中國家承接了部分發達國家的成熟產業轉移,而後沒有發展出可以媲美發達國家的核心技術,這樣此發展中國家便會進入相對停滯的經濟發展階段。
那我國該如何避免中等技術陷阱呢?
AI大模型作爲新技術的奇點將揭示其中的答案。
01
“數字中國”雛形已成
在當前疫情衝擊、國際局勢多變、全球經濟放緩的環境下,我們所處的是一個被形容爲“烏卡(VUCA)時代”的世界。這一術語源自20世紀80年代沃倫·本尼斯和伯特·納努斯的領導理論,代表着易變(Volatile)、不確定(Uncertain)、復雜(Complex)和模糊(Ambiguous)四個方面的特徵。
在VUCA時代,復雜性問題幾乎出現在各個行業。這對無論是企業還是國家,都是一個共同面臨的挑战。如何在這樣的環境中求生存、尋發展,是我們需要共同思考和解決的問題。
而“數字中國”的建設正是最具有確定性、可以擺脫烏卡時代的經濟新動能。從三個方面來看,我國已具有得天獨厚的優勢。
首先,我國有關數字經濟相關政策法律的頒布越來越完善。
2020年4月,中共中央、國務院發布《關於構建更加完善的要素市場化配置體制機制的意見》,明確將數據市場與土地市場、勞動力市場、資本市場、技術市場並列爲加快培育的五大核心生產要素市場之一,數據要素步入市場化階段。
2022年,國務院頒布“數據二十條”,提出二十條政策舉措以建立“三權分置”的數據產權制度框架與多層次數據交易市場體系。
2023年3月1日,中共中央、國務院印發了《數字中國建設整體布局規劃》,自此數字中國形成了完整的政策框架體系。
其次,我國的網絡基礎建設世界領先。
在數字經濟發展的全球藍圖中,中國的優勢十分明顯。其中市場規模是不可比擬的優勢。截至2022年底,我國網民規模已從十年前的5.64億增加到10.67億,居世界第一,互聯網普及率達75.6%,農村地區互聯網普及率爲61.9%。在數字經濟時代,人多意味着產生的數據多,可供分析挖掘的價值多,這是最大的財富。
在網絡強國战略指引下,我國數字經濟規模達50.2萬億元,穩居世界第二;移動支付年交易規模527萬億元,居全球第一;5G基站達284.4萬個,已建成全球最大規模的光纖寬帶和5G網絡。
“數字中國”的建設進一步加速了我國在新技術上的突破。
生成式人工智能的崛起源於深度學習技術的突破和數字內容供應的快速增長,其卓越性能使AI在需求驅動下迅速向數字經濟各領域滲透。
生成式AI不僅創造了新業態、新模式,而且其低成本、高效率、個性化服務也對同領域現有業務模式構成了衝擊,官方爲此也及時出台相關的文件進行合理監管。
2023年7月13日,國家網信辦等七部門聯合公布《生成式人工智能服務管理暫行辦法》(以下簡稱《辦法》),自2023年8月15日起施行。國家網信辦表示,出台《辦法》,既是促進生成式人工智能健康發展的重要要求,也是防範生成式人工智能服務風險的現實需要。
如今用“百模大战”來形容當下人工智能大模型的火熱程度一點也不誇張。數據顯示,國內公开發布的大模型已達80多個,大模型已經進入了去僞存真的階段。
02
低代碼時代使所有數字化轉型不再是口號
隨着GPT-4的發布,其驚人的功能提升引起了廣泛關注。其中,通過一張草圖即可生成網站HTML代碼的表現更是讓人印象深刻。這一幕不僅讓看熱鬧的人驚嘆於技術的神奇轉變,也讓深諳門道的人意識到,這或許是低代碼領域的一次革命性突破。
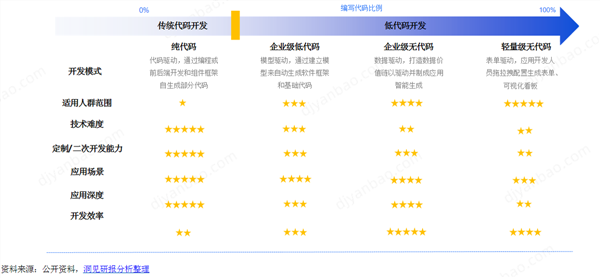
所謂低代碼,是指利用圖形化拖拽、參數化配置等方式,僅需少量代碼即可开發出應用程序或數字工具。自問世以來,低代碼憑借其开發門檻低、效率高以及滿足數字化轉型需求等優勢,備受青睞。然而,長期以來,它也飽受質疑,甚至被認爲是“僞需求”、“行業毒瘤”。
而以ChatGPT爲代表的AI大模型的出現,爲低代碼領域帶來了一线生機。這些模型在圖像識別、自然語言處理、語音識別等領域取得了顯著成果,成功解決了技術方面臨的“業務需求”問題。因此,有觀點認爲,AI大模型有望成爲消除低代碼質疑的最有力武器。
谷歌的BERT模型、Facebook的Detectron2模型等,都是基於深度學習對海量數據的訓練,總結規律和模式,從而達到非常准確的識別能力和預測能力。這些技術的成功應用,爲低代碼領域的發展提供了有力支持。
百度的文心一言全面嵌入百度內部工作平台如流、對外也上車了百度apollo等業務;釘釘也表示全面接入阿裏的 "通義千問 "大模型,增加了 10余種 AI能力、對外也表示要开放;WPS AI表示將嵌入金山辦公全线產品,科大訊飛的投資者交流會中也表示,大模型對於其根據地業務,有着很大推動意義。
根據Gartner的預測,到2025年,70%的企業數字化應用將由低代碼技術構建。甚至有專家認爲,低代碼已經成爲了“企業數字化的核心引擎”。
03
企業的數字化轉型應避免因小失大
如今許多非TMT行業的公司都躍躍欲試想要搞自己的大模型,這是因小失大的行爲。在未來,大模型或只是“數字中國”的基礎設施,價值量最高的反而是企業的數據資源,因爲質量過低的數據將直接決定了企業數字化轉型的成敗。
舉個例子來說,在金融領域中,一個信息的錯誤可能導致徵信評估出現截然相反的判斷。爲了確保高質量的輸出,訓練數據量的大小與模型的推理能力息息相關。然而,訓練數據集的多樣性同樣重要,豐富的數據能夠提高模型的泛化能力。過度擬合訓練數據的情況很容易發生,因此需要確保數據集的多樣性。
對於許多傳統企業和剛剛起步的數字化企業而言,大量語料數據是非結構化的,分散在各個部門。在這種情況下,缺乏現成領域語料數據的可用性成爲了訓練的前提條件。領域數據的記錄、盤點、採集、清洗和轉化成爲了關鍵任務,這實際上考驗着企業的大數據治理水平。如果未經篩選和處理的數據直接用於訓練大型模型,可能會嚴重影響模型的訓練效果。
在數據生產力時代,動態競爭與高頻創新已成爲最具特點的兩大趨勢。動態競爭,顧名思義,是指市場中技術創新和商業創新不斷挑战現有格局,打破市場的相對穩定性和靜止性,從而引發整體性的大幅變動。這種競爭並非短暫的現象,而是長期存在,其強度也有所差異,有的表現爲顛覆性的變革,有的則呈現漸進式的變化。在這種競爭環境中,企業必須時刻保持敏銳的市場洞察力和創新能力,以應對不斷變化的市場需求和行業格局。
總體來看,AI大模型作爲新時代的經濟新動能,將爲我國的經濟發展提供強大的支持。在這個過程中,除了有先發優勢的信息技術龍頭,傳統企業需要關注數據質量、加強大數據治理能力和保持創新能力,以實現可持續發展。
原文標題 : AI觀察:烏卡時代下,數字中國如何成爲經濟新引擎?
標題:烏卡時代下,數字中國如何成爲經濟新引擎?
地址:https://www.utechfun.com/post/240456.html