來源:半導體行業觀察
摘要
對於一個30億參數的LLM,一個帶有16個IBM AIU NorthPole處理器的研究原型推理設備提供了巨大的28,356token/秒的系統吞吐量和低於1 ms /token(每用戶)延遲,而16個NorthPole卡在一個緊湊的2U外形上僅消耗672 W。專注於低延遲和高能效,當NorthPole (12 nm)與一套GPU (7 / 5 / 4 nm)在各種功耗下進行比較時,在最低的GPU延遲下,NorthPole提供72.7個更好的能效指標(token/s/ W),同時提供更好的延遲。
介紹
大型語言模型(LLMs)已經在不同的AI任務中取得了顯著的性能基准,例如通過提供代碼建議來協助編程,在標准化測試中表現出色,以及幫助文章,博客,圖像和視頻的內容創建。
在LLMs的大規模部署中,特別是在人工智能的大規模部署中,出現了兩個主要且相互衝突的挑战,即:能源消耗和響應延遲。
首先,由於LLM在訓練和推理方面都需要大量的能源資源,因此需要一個可持續的未來計算基礎設施來實現其高效和廣泛的部署。隨着數據中心碳足跡的擴大,以及它們越來越受到能源限制,數據中心的能源效率變得越來越重要。根據世界經濟論壇的報告:
“目前,數據中心環境碳足跡主要分成兩部分:訓練佔20%,推理佔80%。隨着人工智能模型在不同領域的發展,對推理及其環境足跡的需求將會升級。”
其次,許多應用程序,如互動對話和自主工作流,需要非常低的延遲。在給定計算架構內,降低延遲可以通過降低吞吐量來實現,但這會導致能效下降。借用一句經典的系統格言進行改述:
“吞吐量問題可以通過資金解決,而延遲問題則更爲復雜,因爲光速是固定的。”(改述自[10],將“帶寬”替換爲“吞吐量”。)
GPU可以通過使用較小的批量大小來實現更低的延遲,但代價是吞吐量和能效的下降。此外,GPU分片通過在多個GPU上使用數據並行性來減少延遲,但同樣犧牲了能效。無論是否分片,GPU似乎都遇到了延遲下限的硬性限制。GPU在能效與延遲之間的權衡如圖1所示。
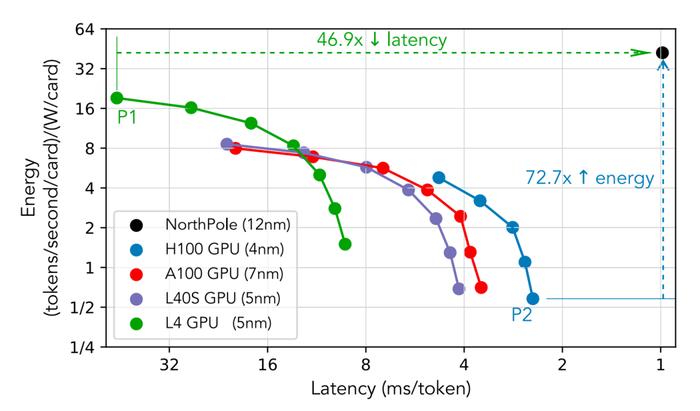
圖1:NorthPole(12 nm)在能量和系統延遲指標上相對於當前最先進的GPU(7 / 5 / 4 nm)的性能,其中系統延遲是每個用戶所經歷的總延遲。在最低的GPU延遲(H100,點P2)時,NorthPole提供了72.7倍的更好能效指標(tokens / second / W)。在最佳的GPU能效指標(L4,點P1)時,NorthPole則提供了46.9倍更低的延遲。
因此,本文所探討的一個關鍵研究問題是如何同時實現低延遲與高能效這兩個相互衝突的目標。
NorthPole是一個推理加速器芯片和軟件生態系統,從第一性原理共同設計,爲神經網絡推理提供卓越的效率。盡管NorthPole並不是專門爲LLM設計的,但令人驚訝的是,本文證明了新型NorthPole架構可以實現低延遲、高能效的LLM推理(圖1、圖2和表1)。
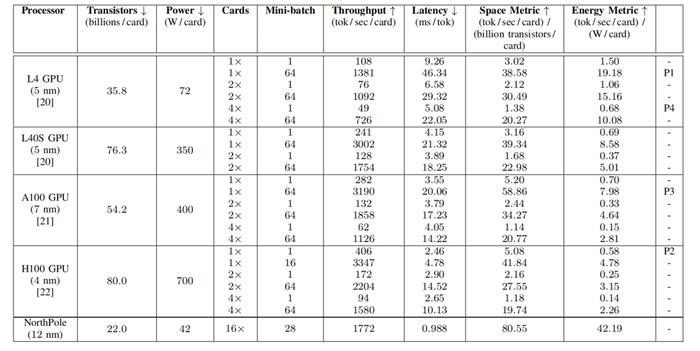
表 I:性能測量結果
測量了NorthPole和GPU系統的性能,按每卡計算。對於每個指標,#表示越低越好,而"表示越高越好。對於NorthPole 16卡設備,功耗按每卡測量,總系統吞吐量按16張卡進行劃分。NorthPole延遲通過所有16張卡進行測量。P1、P2、P3、P4分別指代圖1和圖2中標記的點,表示最高GPU能效指標、最低整體GPU延遲、最高GPU空間指標和最低能效GPU延遲。
本文的主要研究結果如下:
對於一個參數量爲30億的大型語言模型(LLM),其模型結構源自IBM Granite-8B-Code-Base模型,並與Llama 3 8B和Mistral 7B[14]保持一致,本文展示了一種配備16個NorthPole處理器的研究原型推理設備。
在絕對性能方面,該設備提供28,356 tokens/sec的系統吞吐量,單用戶延遲低於1毫秒,同時在2U機型下,16個NorthPole卡的功耗爲672瓦。
在相對性能方面,將12納米的NorthPole與一系列GPU(分別爲7 / 5 / 5 / 4納米的A100 / L4 / L40S / H100)在不同功耗下進行比較,可以從圖2(a)和圖2(c)中看出:在最低的GPU延遲(點P2)時,NorthPole提供了72.7倍更好的能效指標(tokens / second / W)和15.9倍更好的空間指標(tokens / second / transistor),同時延遲仍低於2.5倍;在最佳GPU能效指標(點P1)時,NorthPole提供了46.9倍更低的延遲和2.1倍更好的空間指標,同時仍提供2.2倍更好的能效指標;在最佳GPU空間指標(點P3)時,NorthPole提供了20.3倍更低的延遲和5.3倍更好的能效指標,同時仍提供1.4倍更好的空間指標。
特別是,當將12納米的NorthPole與5納米的L4 GPU進行可比功耗比較時,從圖2(e)中可以看出,在最高的L4吞吐量(低於50毫秒每token,點P1)時,NorthPole提供了46.9倍更低的延遲,同時吞吐量提高了1.3倍;而在最低的L4延遲(點P4)時,NorthPole提供了36.0倍更高的吞吐量(tokens / second / card),同時延遲仍低於5.1倍。
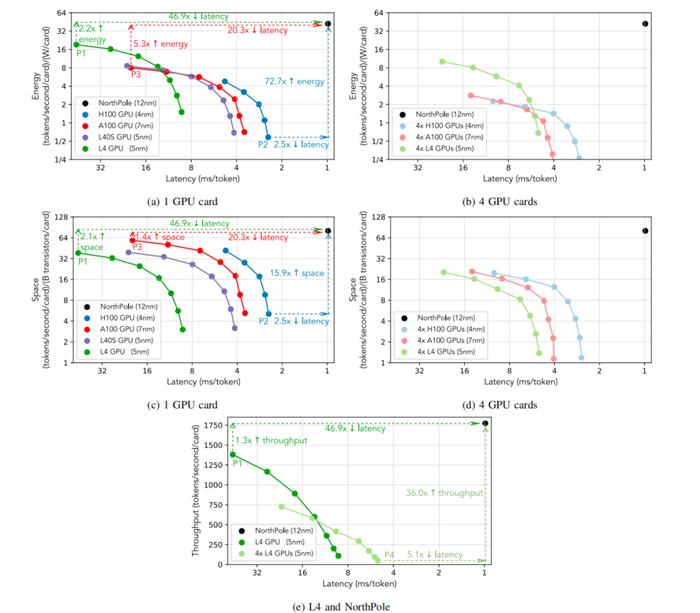
圖2:(a)–(d)面板顯示了12納米的NorthPole在能效、空間和系統延遲指標上相對於當前最先進的GPU(7 / 5 / 4納米)的性能,其中系統延遲是每個用戶所經歷的總延遲。
面板(a)與圖1相同,增加了點P3的標注。面板(a)和(c)使用單個GPU,而面板(b)和(d)使用分片技術,這可能降低延遲,但僅以犧牲能效和空間效率爲代價。在最低的GPU延遲(H100,點P2)時,NorthPole提供了72.7倍更好的能效指標(tokens / second / W)和15.9倍更好的空間指標(tokens / second / transistor),同時延遲仍低於2.5倍;在最佳GPU能效指標(L4,點P1)時,NorthPole提供了46.9倍更低的延遲和2.1倍更好的空間指標,同時仍提供2.2倍更好的能效指標;在最佳GPU空間指標(A100,點P3)時,NorthPole提供了20.3倍更低的延遲和5.3倍更好的能效指標,同時仍提供1.4倍更好的空間指標。
面板(e)顯示了12納米的NorthPole在吞吐量(tokens / second / card)和系統延遲指標上相對於5納米的L4 GPU的性能。在最低的L4延遲(點P4)時,NorthPole提供了36.0倍更高的吞吐量;在最高的L4吞吐量(低於50毫秒每token,點P1)時,NorthPole提供了46.9倍更低的延遲。用於計算每個能效指標的GPU功耗見表I。由於沒有可用的儀器來測量不同批量大小的實際功耗,因此對所有批量大小使用相同的功率,這可能會低估能效指標,但定性的結果仍然成立。
NorthPole架構
如圖3所示,NorthPole處理器採用12納米工藝技術制造,擁有220億個晶體管,面積爲795平方毫米。其架構受到大腦的啓發,經過針對硅的優化,源於十個互補的設計公理,涵蓋計算、存儲、通信和控制,使NorthPole在標准AI推理任務中顯著超越其他架構,即使是與更先進工藝技術制造的處理器相比也表現優異。
有關NorthPole架構的詳細公理,請參見[11],[12]。簡而言之,NorthPole將256個模塊化核心排列在16×16的二維陣列中。每個核心包含一個向量-矩陣乘法器(VMM),在INT8、INT4和INT2精度下,每個核心每個周期分別執行2048、4096和8192次操作。核心計算還包括一個4路、32切片的FP16向量單元和一個32切片的激活函數單元。核心陣列總共有192 MB的SRAM,每個核心配備0.75 MB的SRAM。片上存儲器與計算單元和控制邏輯緊密耦合,核心存儲器與計算之間的總帶寬爲13 TB/s。此外,每個核心都有4096根導线在水平和垂直方向交叉,用於通過四個專用片上網絡(NoCs)傳遞參數、指令、激活值和部分和。爲了防止停頓,片上幀緩衝區配備32 MB的SRAM,將輸入和輸出數據的片外通信與核心陣列的片上計算解耦。
圖3:NorthPole處理器:硅片(左),裸片(中),封裝模塊(右)。
設備
NorthPole已經在一個PCIe Gen3 × 8卡中進行了原型設計,如圖4所示,其中16個卡安裝在一台現成的2U服務器中,組成了一個研究原型推理設備,如圖5所示。該服務器包含兩顆Intel Xeon Gold 6438M處理器,每顆處理器具有32個核心和60 MB緩存,主頻爲2.2 GHz。系統還配備了512 GB的4800 MHz DDR5內存。每個服務器處理器連接有兩條PCIe Gen5 × 16總线,提供總共256 GB/s的PCIe帶寬(雙向)。這四條總线通過PCIe橋接器擴展至系統的16個PCIe插槽,每個插槽上都安裝了一個NorthPole卡。這16個NorthPole卡最大使用可用的256 GB/s PCIe帶寬的一半。
 圖4:NorthPole PCIe卡。
圖4:NorthPole PCIe卡。

圖5:研究原型設備的分解視圖,展示了16個NorthPole PCIe卡的安裝。NorthPole卡可以通過標准的PCIe端點模型與主機進行通信,或者通過每個卡上的附加硬件功能直接、更加高效地彼此通信。
該系統運行Red Hat Enterprise 8.9,NorthPole使用內置的VFIO內核驅動,以便用戶空間的軟件能夠管理硬件。系統使用IOMMU進行地址轉換管理,並啓用設備隔離和虛擬化等安全功能,以便使用虛擬機或容器技術運行應用程序。
每個NorthPole卡通過駐留在每個卡上的DMA引擎接收和傳輸數據。這些DMA引擎獨立工作,可以以多種方式同時接收和傳輸張量。第一種方法是標准的PCIe端點模型,主機程序通過DMA引擎從主機內存中讀取輸入,並在計算完成後將張量寫回主機內存。第二種方法利用每個卡上的附加硬件功能,使NorthPole卡可以通過PCIe直接相互通信,而無需進行主機內存之間的傳輸或在運行時進行額外的軟件管理。通過直接的NorthPole間通信,可以使更大的模型跨越多個NorthPole芯片,同時減少通信延遲和由純軟件管理系統帶來的开銷。
將LLMs映射到NorthPole設備
映射LLMs的策略,如圖6所示,受到了三個關鍵觀察的啓發。首先,對於足夠大的模型,整個變換器層可以使用INT4格式的權重、激活值和KV緩存完全適配在單個NorthPole芯片的內存中(“w4a4”),而輸出層則可以適配在兩個芯片上。其次,如果權重和KV緩存完全駐留在芯片上,運行時只需在層間傳輸小型嵌入張量,這在PCIe Gen3 × 8的帶寬範圍內。第三,可以通過在現成服務器中安裝16個NorthPole PCIe卡,輕松組裝原型NorthPole設備。
這暗示了一種策略,將每個變換器層映射到各自的NorthPole卡上,採用GPipe風格的流水线並行性,並將輸出層跨兩個NorthPole卡拆分,使用張量並行性,通過PCIe Gen3 × 8將層之間的嵌入張量發送。在推理過程中,一個用戶請求的小批量(例如N個請求)被分成M個相等的微批量,並通過16個NorthPole卡進行流水线處理。
雖然流水线並行性已在LLMs訓練中得到利用(沒有延遲限制),但在推理中的使用受限於減少每個流水线階段的空闲時間或流水线氣泡所需的大小批量。例如,有研究發現,高效訓練要求微批量數M大約是流水线階段數的四倍。小批量大小N受到以下因素的限制:(a)系統所需的每個token延遲,以及(b)用於存儲整個小批量的KV緩存的可用內存。低延遲計算和13 TB/s的片上內存帶寬使NorthPole能夠實現極低的每個token延遲,因此選擇N時的限制因素是用於在芯片上存儲整個KV緩存的內存。此外,我們發現微批量數M等於流水线階段數足以使流水线空闲時間可忽略不計。
在本文報告的實驗中,我們選擇了N = 28的小批量大小,分爲M = 14個相等的微批量,從而使每個NorthPole卡計算的微批量大小爲2。我們在如此小的批量大小下進行高效計算的架構設計選擇是實現圖1和表I中所示效率的關鍵。
LLM模型與訓練方法
A
LLM模型
用於測試我們系統的模型基於开源的IBM Granite-8B-Code-Base模型,這是一個具有80億參數的變換器解碼器,包含36個變換器層,隱藏層大小爲4096,FFN中間層大小爲14,336,注意力頭數爲32,使用分組查詢注意力(GQA)的鍵值頭數爲8,詞匯表大小爲49,152。爲了適應帶有16個NorthPole卡的單個服務器,我們使用了該模型的30億參數版本,包含14個變換器層和一個輸出層,量化爲w4a4精度,但其他結構保持不變。
值得注意的是,這種模型配置在每層的基礎上與Llama 3 8B[13]和Mistral 7B[14]相匹配,僅在層數、模型詞匯表大小和使用的訓練數據上有所不同。
B
完全精度准確性的訓練
爲了在量化後恢復原始模型的任務准確性,採用了以下程序來創建模型權重。首先,基於116種語言的1萬億個代碼token,從頭开始訓練一個基线模型,使用全FP16精度,遵循[4]的配方。接下來,對基线模型的輸出層權重和輸入,以及SiLU激活進行了INT8量化,而所有其他權重、线性層輸入和矩陣乘法輸入則進行了INT4量化。最後,通過對來自訓練數據的Python語言子集的進一步85億個token進行量化感知訓練,恢復後量化准確性,學習率爲8×10⁻⁵,批量大小爲128,採用LSQ算法。激活量化器的步長使用熱啓動進行訓練,在訓練的前250步中將學習率提升200倍,以幫助快速適應數據。
在GPU上運行的基准FP16模型和在NorthPole上運行的量化模型在HumanEvalSynthesize-Python上的精度爲pass@10,誤差在0.01以內(0.3001 GPU vs. 0.2922 NorthPole。與Granite-8B-Code-Base模型相比,整體訓練被簡化爲專注於硬件性能表徵,而不是推動任務准確性的界限。
運行時應用
在推理過程中,如圖6所示,token由在主機CPU上運行的高度流水线化用戶應用生成,該應用通過使用分詞器和嵌入層將文本預處理爲輸入張量,將輸入張量放入設備中的第一個NorthPole卡,從設備的最後一個NorthPole卡接收結果輸出張量,使用解碼器和反分詞器對輸出張量進行後處理,並將生成的token循環作爲下一個輸入。用戶應用還負責用戶界面以及提示預填充等更高級的優化。
爲了將神經網絡工作負載卸載到NorthPole,用戶應用調用具有簡單API的用戶空間運行時庫,在初始化時配置NorthPole卡的層權重和KV緩存,並在運行時發送和接收輸入與輸出張量。權重和KV緩存配置後保留在片上內存中,運行時無需從片外流式傳輸。運行時庫還管理片上幀緩衝區,以防止NorthPole核心因缺乏輸入數據或輸出數據接收方而停滯。中間張量在卡之間傳遞,無需主機幹預,如第四節所述。
性能結果
NorthPole 16卡設備在30億參數LLM上實現了28,356token/秒的吞吐量。該LLM的序列長度配置爲2048(1024個提示長度,生成1024個token),解碼器採用貪婪採樣。
爲了與GPU進行比較,我們測量了兩款針對低功耗推理的GPU(L4 和 L40S)及兩款針對高吞吐量訓練的GPU(A100 和 H100)的單卡性能。所有系統均運行相同的LLM模型和配置,NorthPole以w4a4精度運行,而GPU則以最佳的w4a16精度運行,因爲據我們所知,沒有可用的w4a4 CUDA核心。在我們的GPU實驗中,我們利用了GPTQ量化模型,並使用vLLM(版本0.5.4)Marlin核心進行基准測試,以便與NorthPole進行比較。使用GPTQ量化通過降低權重精度,同時保持可接受的准確性,爲GPU提供了最佳的模型推理性能。此外,Marlin核心被用來優化矩陣運算,特別是在處理稀疏和密集矩陣乘法時。通過vLLM運行時的基准測試,使我們能夠評估吞吐量和延遲,確保在給定硬件配置下的最佳模型性能。在多個GPU卡的實驗中,採用與可用卡數相等的張量並行性,以有效獲得通過NVLink的最小可能延遲。我們的實驗表明,分片技術雖然減少了延遲,但導致GPU每卡的吞吐量下降。值得注意的是,NorthPole的卓越性能主要源於其巨大的片上內存帶寬,其次才是較低的精度。
表I顯示了NorthPole和GPU系統在每卡基礎上的測量性能結果。基本指標包括吞吐量、延遲、空間和能量指標,定義如下。
對於輸入提示的小批量生成的總token數爲:
其中,MMM爲微批量的數量,tok_seq_len爲單個用戶生成的輸出token數。系統吞吐量是響應輸入提示的生成token總數(tokens gen),除以處理提示所需的總時間,包括提示預填充時間(prompt time)和token生成時間(token gen time):
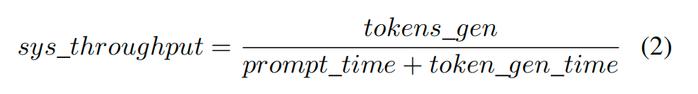
吞吐量以每卡爲單位進行比較,方法是將系統吞吐量除以系統中處理卡的數量:
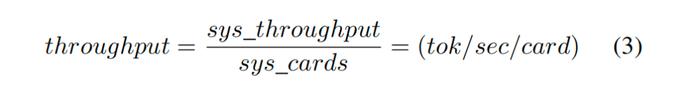
延遲是對特定用戶生成輸出token之間的平均時間的度量,它是嵌入token流經處理管道所需時間的總和,以及在生成token總數上平攤的提示預填充時間:
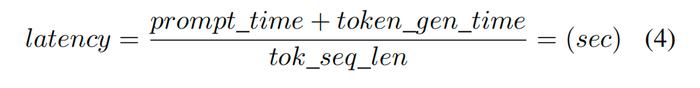
同樣地,結合式1、2、4:
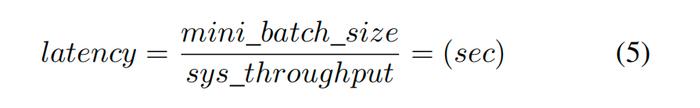
其中小批大小=小批大小注意,這是每個用戶看到的系統延遲。
通過系統中的卡片數量進行規範化,我們擴展了[11]中定義的空間和能量指標,以便能夠比較具有不同卡片數量的系統。由此產生的空間和能量指標是每張卡的吞吐量,分別由每張卡的處理器晶體管數量和每張卡的功率歸一化:

如果系統吞吐量與系統中流水线卡的數量成比例地擴展,則卡的規範化將被抵消,使空間和能量指標與系統中卡的數量保持不變。通常,由於通信和同步开銷,系統吞吐量在卡數量上呈次线性增長。
結論
我們提出以下貢獻:
我們展示了一個多卡NorthPole設備的研究原型。
我們證明了像LLM這樣的大型神經網絡模型可以有效地在多個NorthPole處理器之間拆分,擴展了我們之前的工作,後者顯示單個NorthPole處理器在視覺推理任務(ResNet50、Yolo-v4)上的表現優於其他架構。
我們證明了NorthPole獨特的架構非常適合LLM推理,使其在低延遲和高能效的雙重目標上顯著超越邊緣和數據中心GPU。
由於NorthPole設備必須作爲一個整體使用,因此它對高吞吐量應用最爲高效。
本初步論文爲進一步研究能效優化、在相應更大NorthPole設備上映射更大LLM、新的與NorthPole架構協同優化的LLM模型,以及未來系統和芯片架構提供了一個跳板。
參考鏈接
[1] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin,S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” 2020. [Online]. Available: https://arxiv.org/abs/2005.14165
[2] J. Yang, H. Jin, R. Tang, X. Han, Q. Feng, H. Jiang, B. Yin, and X. Hu, “Harnessing the power of LLMs in practice: A survey on ChatGPT and beyond,” 2023. [Online]. Available: https://arxiv.org/abs/2304.13712
[3] M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H. Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders, C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight, M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish, I. Sutskever, and W. Zaremba, “Evaluating large language models trained on code,” 2021. [Online]. Available: https://arxiv.org/abs/2107.03374
[4] M. Mishra, M. Stallone, G. Zhang, Y. Shen, A. Prasad, A. M. Soria, M. Merler, P. Selvam, S. Surendran, S. Singh et al., “Granite code models: A family of open foundation models for code intelligence,” arXiv preprint arXiv:2405.04324, 2024.
[5] O. (2023), “GPT-4 technical report,” 2024. [Online]. Available: https://arxiv.org/abs/2303.08774
[6] D. McCandless, T. Evans, and P. Barton. (2024) The rise and rise of A.I. large language models (LLMs) & their associated bots like ChatGPT. [Online]. Available: https://informationisbeautiful.net/visualizations/therise-of-generative-ai-large-language-models-llms-like-chatgpt/
[7] B. Cottier, R. Rahman, L. Fattorini, N. Maslej, and D. Owen, “The rising costs of training frontier AI models,” arXiv preprint arXiv:2405.21015v1, 2024.
[8] S. Samsi, D. Zhao, J. McDonald, B. Li, A. Michaleas, M. Jones, W. Bergeron, J. Kepner, D. Tiwari, and V. Gadepally, “From words to watts: Benchmarking the energy costs of large language model inference,” 2023. [Online]. Available: https://arxiv.org/abs/2310.03003
[9] B. Ammanath, “How to manage AI’s energy demand — today, tomorrow and in the future,” 2024. [Online].
Available:https://www.weforum.org/agenda/2024/04/how-to-manageais-energy-demand-today-tomorrow-and-in-the-future/
[10] D. A. Patterson, “Latency lags bandwidth,” Commun. ACM, vol. 47, no. 10, p. 71–75, Oct 2004. [Online]. Available: https://doi.org/10.1145/1022594.1022596
[11] D. S. Modha, F. Akopyan, A. Andreopoulos, R. Appuswamy, J. V. Arthur, A. S. Cassidy, P. Datta, M. V. DeBole, S. K. Esser, C. O. Otero et al., “Neural inference at the frontier of energy, space, and time,” Science, vol. 382, no. 6668, pp. 329–335, 2023.
[12] A. S. Cassidy, J. V. Arthur, F. Akopyan, A. Andreopoulos, R. Appuswamy, P. Datta, M. V. Debole, S. K. Esser, C. O. Otero, J. Sawada et al., “11.4 IBM NorthPole: An Architecture for Neural Network Inference with a 12nm Chip,” in 2024 IEEE International Solid-State Circuits Conference (ISSCC), vol. 67. IEEE, 2024, pp. 214–215.
[13] AI@Meta, “Llama 3 model card,” 2024. [Online]. Available: https://github.com/meta-llama/llama3/blob/main/MODEL CARD.md
[14] A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7B,” 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
[15] Y. Huang, Y. Cheng, A. Bapna, O. Firat, M. X. Chen, D. Chen, H. Lee, J. Ngiam, Q. V. Le, Y. Wu, and Z. Chen, “GPipe: Efficient training of giant neural networks using pipeline parallelism,” 2019. [Online]. Available: https://arxiv.org/abs/1811.06965
[16] N. Shazeer, Y. Cheng, N. Parmar, D. Tran, A. Vaswani, P. Koanantakool, P. Hawkins, H. Lee, M. Hong, C. Young, R. Sepassi, and B. Hechtman, “Mesh-TensorFlow: Deep learning for supercomputers,” 2018. [Online]. Available: https://arxiv.org/abs/1811.02084
[17] M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-LM: Training multi-billion parameter language models using model parallelism,” 2020. [Online]. Available: https://arxiv.org/abs/1909.08053
[18] S. K. Esser, J. L. McKinstry, D. Bablani, R. Appuswamy, and D. S. Modha, “Learned step size quantization,” in International Conference on Learning Representations, 2020.
[19] N. Muennighoff, Q. Liu, A. Zebaze, Q. Zheng, B. Hui, T. Y. Zhuo, S. Singh, X. Tang, L. Von Werra, and S. Longpre, “Octopack: Instruction tuning code large language models,” arXiv preprint arXiv:2308.07124, 2023.
[20] NVIDIA Corporation, “NVIDIA ADA GPU Architecture (V2.01),” 2023. [Online]. Available: https://images.nvidia.com/aemdam/Solutions/Data-Center/l4/nvidia-ada-gpu-architecture-whitepaperv2.1.pdf
[21] ——, “NVIDIA Ampere GA102 GPU Architecture (V2.1),” 2021. [Online]. Available: https://images.nvidia.com/aemdam/en-zz/Solutions/geforce/ampere/pdf/NVIDIA-ampere-GA102- GPU-Architecture-Whitepaper-V1.pdf
[22] ——, “NVIDIA H100 Tensor Core GPU Architecture (V1.04),” 2023. [Online]. Available: https://resources.nvidia.com/en-us-tensorcore/gtc22-whitepaper-hopper
標題:又一顆芯片,挑战GPU
地址:https://www.utechfun.com/post/428426.html