作者:前台積電建廠專家 Leslie Wu
你可能不知道,問世超過20年的DUV光刻機,還在發光發熱。
使用浸潤式DUV光刻機+多重曝光技術生產5nm芯片完全可行,不計代價的情況下甚至能做到3nm。
盡管理論上可行,且在7nm節點上已被部分晶圓廠驗證過,但這需要諸多條件同時滿足,比如多重曝光中關鍵的“套刻精度”——多次曝光之間圖形對准的精度。
此外,也還涉及到許許多多的制程手段,比如相移光罩、模型光學臨近效應修正、過蝕刻、反演光刻等,甚至基於最新的定向自組裝光刻技術,在不依賴更高分辨率光刻的情況下,也有生產5nm芯片的可能。

當然,這么做需要付出高昂的成本,一般晶圓廠不會採用這種極端的手段來量產先進工藝芯片,畢竟主流的方案都是經過市場優勝劣汰,篩選出來的最符合商業邏輯的制造方式。
我們先從一個基礎知識講起,但如果你對工藝節點有系統的認知,可跳過第一部分。
5nm是文字遊戲?
想要搞清楚浸潤式光刻機+多重曝光到底能否做到5nm之前,需要先釐清什么是5nm。正好這兩天,也有人把這個話題又拿出來吵,說ASML揭了晶圓廠的老底。
在展开說线寬的話題之前,我們需要知道,晶體管的作用,线寬在這裏面扮演的價值。
晶體管通過柵極(Gate)來控制電路的導通和截止,導通代表1,截止代表0,以此來實現二進制計算。柵極長度(Gate length)越小,電流通過晶體管的源極(Source)、漏極(Drain)的速度就越快,即芯片的性能越強。
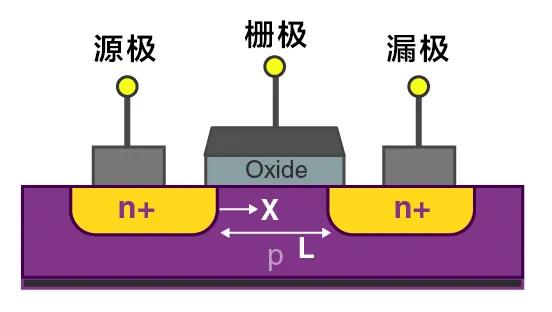 圖1:MOSFET場效晶體管平面結構示意圖
圖1:MOSFET場效晶體管平面結構示意圖
過去,晶體管的柵極長度被定義爲线寬,和工藝節點名保持一致,光刻、沉積、刻蝕、擴散都是縮小线寬的核心制程。
隨着FinFET、Nanasheet這些立體的晶體管結構的問世,半導體行業开始着重突出等效性能的概念——雖然叫14nm,但它的柵極長度遠不止14nm。例如,英特爾的14nm工藝,柵極長度是24nm,台積電的7nm工藝,柵極長度是22nm。
另一方面,线寬並不能作爲衡量晶體管密度的特徵參數,這是因爲即便线寬很小,但如果柵極之間的間距很大,單位面積內容納的晶體管數量依然無法提升。這個時候,如果要表示元件的微縮程度,就需要引出另一個關鍵指標——周距(Pitch,也有節距的叫法),如下圖。比如,過去1個單位面積下有9個晶體管,通過縮小周距,可容納10個晶體管。
 圖2:线寬/柵極長度、周距與半周距的關系
圖2:线寬/柵極長度、周距與半周距的關系
90年代,0.35μm以前,工藝節點、半周距(Half pitch,即周距的一半)與柵極長度均一致,但在這之後,半周距、柵極長度與節點的對應關系出現分歧。從下面的圖表我們可以清楚看出節點,半周距與柵極長度的關系與演變。
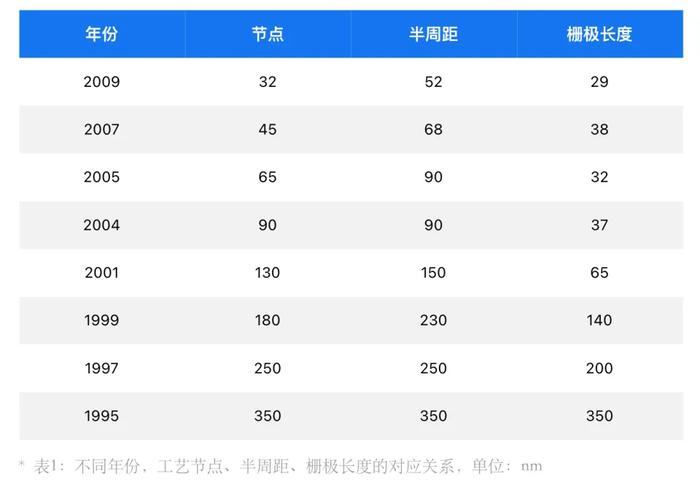
回到最开始的話題,當我們在說5nm的時候,其實只是在說它的制程節點,而並不是實際的线寬。
許多朋友喜歡說,現在各家半導體大廠宣稱的多少nm工藝都是營銷話術,嚴格意義上,20年前所有工藝節點都是如此。10年前,行業進入14nm的FinFET立體結構時代,則徹底地打破節點、周距、柵極長度與线寬的關聯。
沒有統一的標准自然會被企業拿來玩文字遊戲模糊概念,三星在其14nm節點首开先河,台積電爲了不落人後馬上跟進,但保守的定義爲16nm,只有自詡爲“摩爾定律”堅定追隨者的英特爾,當時還在死磕傳統线寬的命名方式,直到2021年才全面修改節點命名,跟隨競爭對手的節奏。
但這有問題嗎?其實一點問題都沒有。
晶體管早就從平面變爲立體結構,如果我們把线寬的概念轉化爲單位晶體管密度(MTr/mm2,即每平方毫米百萬晶體管數),會發現摩爾定律並沒有消亡,只是以一種不同的形態繼續生效——晶體管單位密度仍一直在增加——原本摩爾定律規定的就是“晶體管數量每18個月提升一倍”。
晶體管密度江湖裏的搏殺
針對晶體管的各種特徵尺寸多而復雜,每個廠商都有不同的定義設計,不同廠商相同制程工藝的產品也不完全具有可比性。
目前直觀比較各家制程差異的唯一辦法,就是回歸摩爾定律的本質,對比晶體管密度,即單位面積內的晶體管數量。
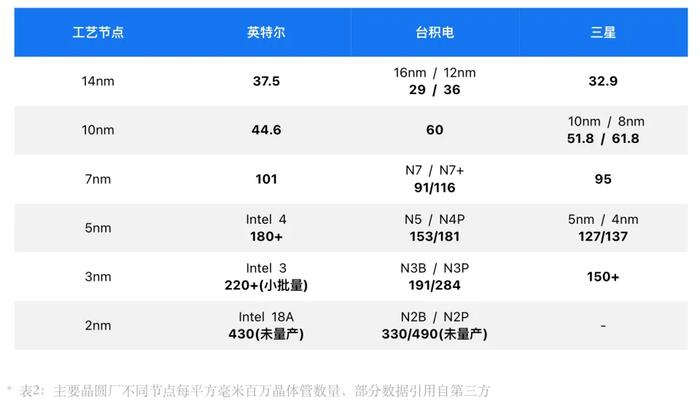
根據上表的數據,在14nm節點英特爾、台積電、三星單位晶體管數量都是每平方毫米0.3億顆左右。
10nm开始,英特爾將14nm+++改爲Intel 10,名字是跟上了,但晶體管數量卻成了倒數第一,而三星則是在10nm的優化版,即三星的8nm節點,才提升至與台積電大致水平。
2018年台積電利用浸潤式光刻機1980Ci,配合四重曝光技術率先量產7nm,三星在隔年以更先進的EUV光刻機應战,但失去了先機,加上對EUV光刻機的熟悉不足,結果良率低下,最後以自家三星手機放棄獵戶座芯片,轉而搭載高通芯片以及开出比台積電低30%的代工費用,勉強留下大客戶高通,英特爾這時候還在擠14nm+++的牙膏,7nm一役台積電大殺四方。
台積電7nm從DUVi的N7、N7P,到EUV的N7+及N6共四個版本,晶體管密度從0.91提升到1.16億,三星爲0.95億,英特爾2020年才量產1億晶體管密度,而在這個節點上,台積電已先一步幫華爲生產出全球首款5nm手機芯片麒麟9000,晶體管密度達1.5億+。
2020年,三星宣布量產5nm,但晶體管密度只從7nm的0.95億小幅提升至1.27億,改良版4nm也只有1.37顆億晶體管,遠遠不如台積電初代5nm的1.5億,與台積電1.8億的5nm改良版N4P差距更大,只能算作7nm的升級版。3nm節點上,三星也存在類似的問題。
2021年英特爾宣布全面改名節點,英特爾10nm改成Intel 7,原本的7nm改成Intel 4,並把後續節點細化成了Intel 3、Intel 20A、 Intel 18A。英特爾CEO帕特·基辛格雖然提出了4年5個節點的路线圖,但實際上Intel 7本身就是已量產的10nm,Intel 4與Intel 3是同一節點的細分優化版本,所以這5年真正要攻克的是3個節點。
根據我們的了解,Intel 18A進度大概率要延後,至少得2026年或者更久,而2025年底台積電第一代的2nm可以量產,但目前蘋果3nm和2nm的案子都在跑,明年的A19是否採用台積電的2nm,將會在2025年第一季度視2nm產线的良率做最後定案,這也主要是去年蘋果A17搶發第一代3nm,但升級效果不明顯有關,畢竟N4P與N3B,晶體管密度分別爲1.8億、1.9億,提升並不明顯。
所以,今年蘋果很可能會改變打法,讓台積電繼續深挖3nm潛能,比如今年蘋果A18將採用N3P,雖說跟去年的A17都是3nm,但其晶體管密度從1.9億到2.8億。對比其他競品的3nm,目前晶體管密度都還在1.8億以下,且都是良率很低的小批量生產。
有一個現象是值得注意的——摩爾定律的節點推進時間從原本18個月到24個月,進入7nm以後則是延緩到30個月,2018年量產7nm,2020年量產5nm,2023量產3nm,2025量產2nm,大概爲2~3年左右推進一代。以目前可知技術來看,1.4nm還能保持目前速度,1nm往後節點大概率拉長到40個月以上,但這只是线寬微縮的放緩,並不影響晶體管數量的提升。
在可以確定的20年內,芯片晶體管的總數將持續快速增長,甚至在單芯片功耗上超越原本的摩爾定律,比如3月份台積電的劉德音與黃漢森在IEEE發表的文章,預測未來10年內,人類就可以制造出一萬億顆晶體管的GPU單芯片,而且未來不再是通過單一的制程手段改善來提升晶體管數量,立體結構的優化、2D新材料以及先進封裝每一個技術,都能有效並持續的提升晶體管數量。
量產與良率成爲模糊地帶
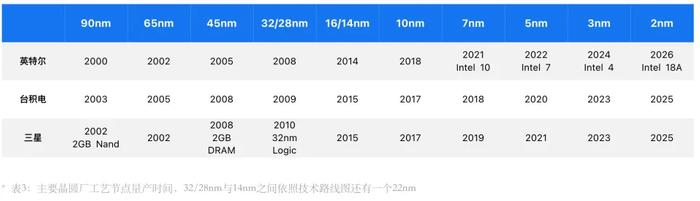
過去搶先量產,是英特爾、三星、台積電三強競爭的重要關鍵,誰先量產誰就能掌握先機。
但現在,各家對節點定義的差距巨大,比如都說自己是5nm,但晶體管密度天差地別,從這個角度來看,對台積電還有一點點威脅的是英特爾,三星已經不在競爭的行列。
三星還有個玩法就是在良率上動手腳,一個新節點多少良率才算是達到量產水平,這是最說不清的環節。按台積電的做法,有外部客戶愿意在當前良率下單,並順利產出才稱爲量產,也就是所謂的商業量產。
三星每個節點的首發客戶基本都是內部的三星電子,一般在低良率階段开啓風險試產並同時對外宣稱量產。
將研發中個位數良率拿來宣布量產,這么做只是爲了宣傳,不會有任何實質意義,因爲良率不足的壞片,慣例是由客戶承擔,同等密度情況下,客戶肯定是優先下單給良率最高的晶圓廠。在密度跟良率都落後的情況下,只有降低代工費用才能搶到零星客戶,還得承擔良率不足的壞片成本,但晶圓廠這么幹,沒有任何賺錢的可能性。
有一點需要注意,相關廠家有時候會透露自己良率已經到60%甚至80%,但這其中也有模糊地帶,一般情況下80%的良率,只是對應礦機ASIC這種簡單芯片,手機AP(Application Process,手機中的應用處理器CPU)的良率則有可能不到50%,而如果是GPU這類面積大的芯片可能只有20%出頭。
同樣的7nm工藝,生產不同產品良率截然不同,但廠家可能只告訴你最好的那個,這也是行業的貓膩之一。
晶圓廠的量產時間與良率是一個可以大做文章的模糊地帶,這種對比絕非簡單制程節點的同比,而要看單位面積的晶體管密度以及真正可以拿到商業客戶訂單的量產時間與良率,才叫商業量產。
2020年,三星宣布量產5nm芯片,看似贏了對手,但一比較兩者晶體管密度與良率,就會得出完全相反的結果。
沒有EUV,怎么做5nm?
前面的幾個部分,給大家講了過去的5nm、現在的5nm對應的概念。簡單總結,20年前如果說5nm,對應的就是线寬,晶體管的柵極長度,但是今天再說5nm,實際上就是一個工藝節點的符號,比起這個符號,單位面積下的晶體管密度才能高下立判。
接下來,我們將通過一系列的講解,來告訴大家,在沒有EUV光刻機的情況下,通過哪些手段,來實現所謂的“5nm”、“3nm”,這部分內容在林本堅博士的《光學微影縮IC百萬倍》講座中也做了非常詳細的介紹,我們做了一些簡要摘錄,先從一個核心的光學分辨率公式开始(提示:這不需要太多數學基礎,往下看即能看懂):
半周距Half Pitch = k1λ/sinθ。
Half Pitch:參照文章圖2,线寬/柵極長度+线與线的間距即Pitch,再乘以1/2即Half Pitch。
k1:與工藝有關的系數,縮小Half Pitch的關鍵,是所有晶圓廠光刻工藝工程師致力縮小的目標,也是我們要討論的核心。
λ:光刻中使用光源的波長,從g-line的436nm,降到EUV的13.5nm,是光刻機制造商努力的目標。
sinθ:與鏡頭聚光至成像面的角度有關,基本由鏡頭決定,也是光刻機制造商努力的目標。
不過由於光在不同介質中,波長會改變,在考慮如何增加分辨率時,需要將透鏡與晶圓之間的介質(折射率n)一並納入考量,公式則變成了Half Pitch = k1λ/nsinθ(注:nsinθ即光刻機的數值孔徑NA)
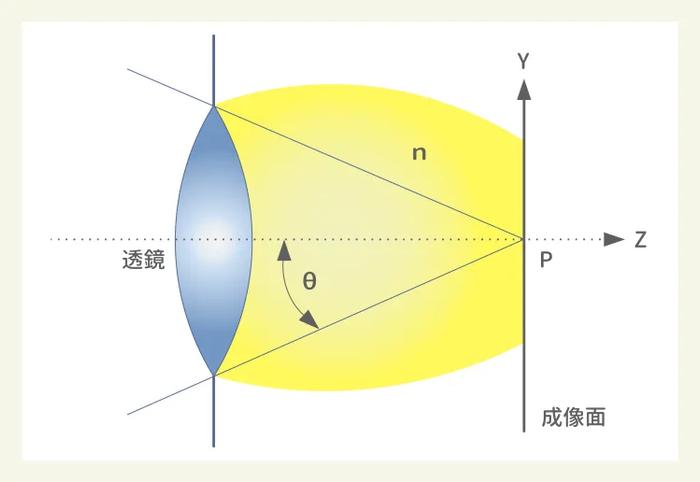 圖3:光线通過透鏡系統聚焦成像示意圖,n爲介質折射率,θ爲鏡頭的聚光角度
圖3:光线通過透鏡系統聚焦成像示意圖,n爲介質折射率,θ爲鏡頭的聚光角度
以193nm光源的浸潤式光刻機爲例,其k1爲0.28,水的折射率n爲1.44,sinθ爲0.93,其Half Pitch=(0.28×193)/(1.44×0.93)=54.04/1.3392≈40nm,即分辨率爲40nm。
所以,如果要提高光刻機的分辨率,可以調整公式中的變量,擴大分母或者縮小分子,對應有四種可能性:即增加聚光角度,提升sinθ、提高介質的折射率n、降低k1系數、採用波長更λ更短的光源。其中,降低k1系數是目前晶圓廠層面最大的突破口之一,可重點關注。
1)提升sinθ:研發巨大復雜的鏡頭
sinθ與鏡頭聚光角度有關,數值由鏡頭決定,sinθ越大,分辨率越高。光刻機所使用的鏡頭由非常多大大小小、不同厚薄及曲率的透鏡,經過精確計算後,仔細堆疊組成的,需要靠起重機來吊裝,目前光刻機的鏡頭系統接近6000萬美元,EUV鏡頭系統甚至超過一億美元。
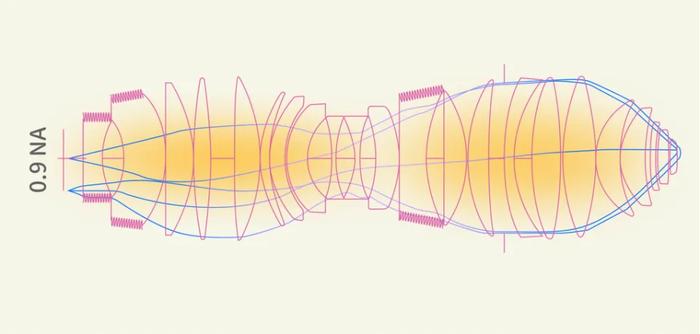 圖4:0.9NA光刻機鏡頭系統,NA(數值孔徑)= n × sin θ
圖4:0.9NA光刻機鏡頭系統,NA(數值孔徑)= n × sin θ
做得這樣復雜也是爲了盡可能將 sinθ逼近理論極值1。
目前ArF光刻機的鏡頭可將 sinθ值做到0.93,EUV光刻機目前只能達到0.33,Hyper-NA EUV的目標值是0.75,也是ASML的終極項目,如果未來沒有新技術發明出來,這很可能是芯片物理光刻技術的終結。
2)縮短波長:材料與鏡頭的精准搭配
縮短波長主要依靠光源的改變,比如g-Line,i-Line的UV(紫外光),KrF,ArF的DUV(深紫外光)再到目前13.5nm波長的EUV(極紫外光),如果波長再短就是X-ray。
改變光源可以獲得想要的波長,但鏡頭的材料也必須相應改變,材料可選項也會越少。
另一種解決方案是在鏡頭組中加入反射鏡(下圖黃色部分),這樣的鏡頭組合稱爲反射折射式光學系統。不管什么波長的光,遇到鏡面的入射角和反射角都相等,以反射鏡取代透鏡,就可以增加對光波帶寬的容忍度。
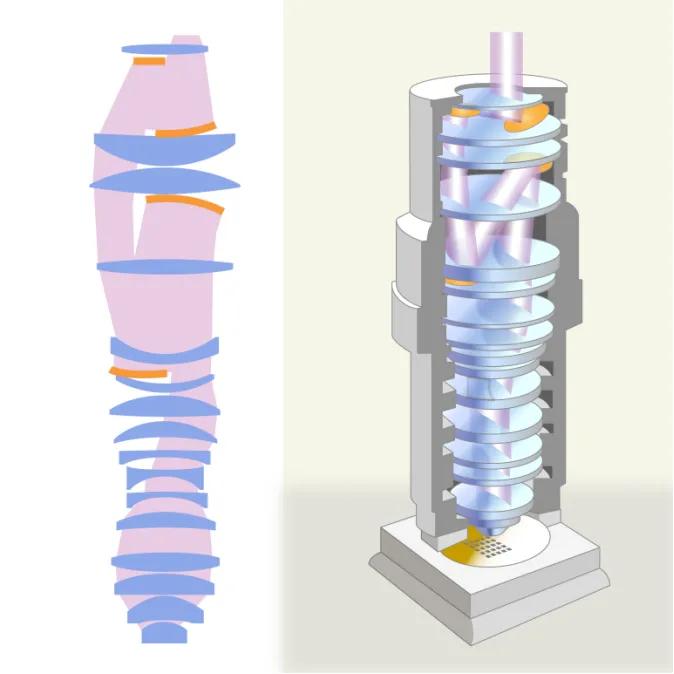 圖5:193nm的ArF光刻機所使用的鏡頭系統,從圖中可看到在透鏡組合之間加入了反射鏡。
圖5:193nm的ArF光刻機所使用的鏡頭系統,從圖中可看到在透鏡組合之間加入了反射鏡。
到了EUV的13.5nm波長時,整組鏡頭都採用反射鏡,稱爲全反射式光學系統,這種系統必須設計得讓光束相互避开,使鏡片不擋光线。此外,相較於透鏡穿透的角度,鏡面反射的角度對誤差的容忍度更低,必須非常精准。
光源改變不僅會影響鏡頭材料,也牽涉到光刻膠的材料,涵蓋化學性質、透光度、感光度等特性,這也是個浩大的工程,需要無數的材料及配方去應對不同制程的layer。其中,感光速度是節省制造成本的關鍵,每次曝光多幾秒那對芯片制造來說都是不可承受的成本。
3)提高折射率n值:浸潤式光刻技術
在增加分辨率的路上,還可以調整鏡頭與晶圓之間的介質。由前台積電研發副總林本堅提出的浸潤式技術中,將介質從折射率接近1的空氣,改成折射率1.44的水,形同193nm波長等效縮小1.44倍至134nm。
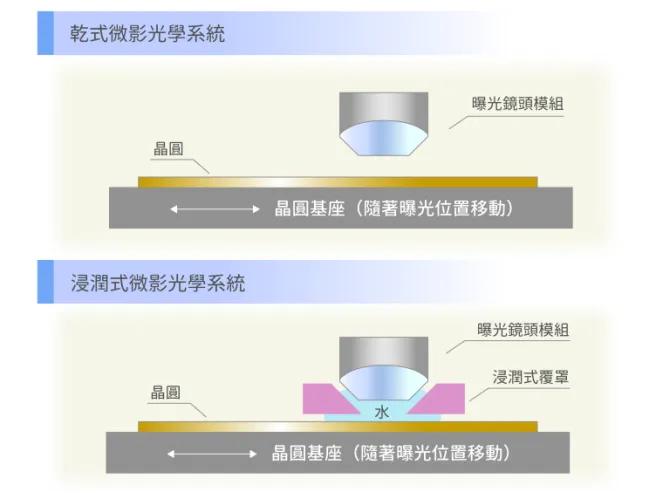 圖6:幹式光刻系統與浸潤式光刻系統的差異
圖6:幹式光刻系統與浸潤式光刻系統的差異
浸潤式技術讓半導體制程可以繼續使用同樣的波長和光罩,只要把水放到鏡頭底部和晶圓之間就好。理論很簡單但難點在於,例如浸液系統中的DI Water(去離子水)中的空氣會產生氣泡,必須完全清除,且要讓水快速流動使之分布均勻,保證成像效果。
我們了解過,ASML浸潤式光刻機的Alpha機,單單浸液系統,在台積電南科專門跟林本堅團隊修改了7-8回,耗時兩年多。Alpha機完成後的Beta版還得組織龐大的人力在晶圓廠消耗無數晶圓,把原本上千個缺陷,降到幾百個、幾十個,最後降到零,這是一個艱苦的過程。
4)降低 k1:分辨率增益技術(RET)
提高分辨率的最後一條路,就是降低 k1值,這是晶圓廠裏光刻工藝工程師工作的重中之重,也是離我們最近的一條路线。將k1降下來,是DUV光刻機制作5nm芯片的關鍵。
首先要解決的問題是“防振動”,就像拍照防抖一樣,在曝光時設法減少晶圓和光罩的相對振動,使曝光圖形更加精准,恢復因振動損失的分辨率;其次是“減少無用反射”,設法消除曝光時晶圓表面所產生的不必要的反射。改良上述兩項參數,實測的數據顯示,基本可以將k1控制在0.65的水平。
進一步提高分辨率還需要使用到雙光束成像,分別有偏軸式曝光及相移光罩兩種。偏軸式曝光是調整光源入射角度,讓光线斜射進入光罩。透過角度調整,這兩道光相互幹涉來成像,使分辨率增加並增加景深。相移光罩則是在光罩上進行處理,讓穿過相鄰透光區的光,有180度相位差。這兩種做法都可以讓k1減少一半,但都屬於雙光束成像的概念,不能疊加使用。到這裏,基本可以使k1控制在0.28。
再進一步降低 k1,殺手鐗是用兩個以上的光罩,也就是大家耳熟能詳的多重曝光。最通俗的解釋就是將密集的圖案分工給兩個以上圖案較寬松的光罩,輪流曝光在晶圓上(如下圖7)。
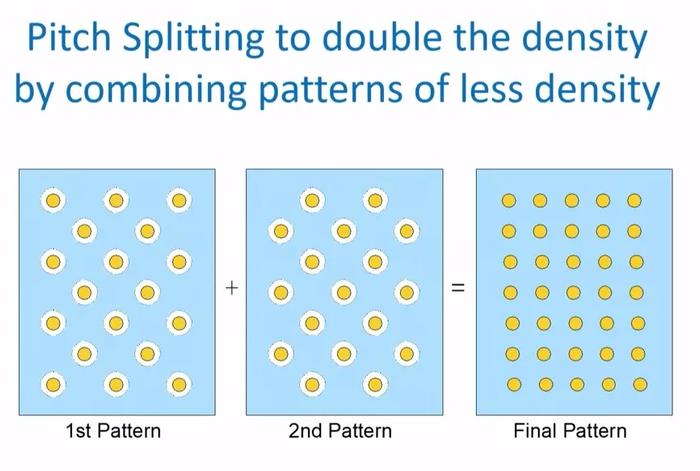
圖7:28nm光刻機使用的光罩示意圖,光透過白色孔照射在晶圓的光刻膠上呈現黃色圓點,借助2個光罩分兩次曝光,以實現分辨率的提升
不過,因爲曝光次數加倍,在WPH(晶圓片數/小時)不變的情況下,晶圓產出效率降低了一半,多次曝光也將導致良率的降低,更低的產出加上更低的良率,這對“成本即一切”的半導體行業來說是不可承受之重,而曝光次數增加導致的低產出無可避免,工程師們唯一可以挽救的唯有良率。
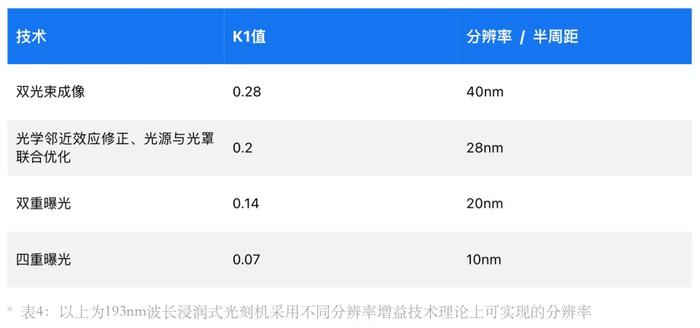
在浸潤式光刻機上,疊加使用光學鄰近效應修正、光源與光罩聯合優化等技術,可以讓k1值下探到0.2,分辨率可達28nm。採用雙重曝光,k1可以從初始的0.28降至0.14,分辨率則達到20nm。採用四重曝光則可以將k1降到0.07,分辨率達到10nm左右,甚至比EUV光刻機的11.5nm的分辨率更高,這就是浸潤式光刻機多重曝光做7nm、 5nm甚至3nm的理論依據。
雖然理論簡單,但實踐起來就沒那么容易,這其中自對准多曝光技術最爲重要,借助這項技術可以讓k1值成倍的縮小,而這項技術最關鍵的就是光刻機的套刻精度(Overlay),它決定了芯片上下層的對准精度,進而決定了多重曝光的良率。
提高套刻精度的辦法之一,就是拿到更高精度的設備,比如2100i DUV光刻機。另外,每家晶圓廠掌握的技術也不盡相同,目前能把多台套刻精度(MMO)做到無限接近單台套刻精度(DCO),全世界僅台積電一家。這是基於光刻機性能以外的know how,有兩個數據可供參考:台積電用MMO:2.5nm的1980ci光刻機+四重曝光良率超過80%,而我們大陸廠用MMO:1.5nm的2050i+四重曝光下,經過2年的不斷努力,良率接近50%。
去年,比利時微電子研究中心(IMEC)去年發布了浸潤式光刻機借助八重曝光做5nm的技術方案。
其他技術路线上,IMEC和Mentor還共同創建不需添加任何冗余金屬,沒有額外的電容SALELE(自對准-光刻-刻蝕)技術,以及跳脫了傳統使用光罩的光刻,以材料研發爲方向,先合成聚合物再加熱處理產生特殊的化學交互作用,就會自動對齊成爲比原來小四分之一結構的“定向自組裝技術”(Directed Self-Assembly,DSA)。
另外,由於EUV太容易被吸收,無法像DUV一樣用水折射增加折射率n值,ASML通過High-NA,Hyper-NA提高sinθ這種路徑最終會走到盡頭,所以晶圓廠制程端,可以大幅度降低k1的多重曝光就成了不論DUV,還是EUV都繞不开的技術,這也意味沉積與刻蝕設備更加的重要,AMAT、LAM、TEL三巨頭無不卯足了勁發展相關技術,包括更復雜的脈衝,更精細的控制,更大功率的工具,尤其是原子層沉積與刻蝕技術,都將改變原來的工藝路线。
再回到文章第二部分的晶體管密度表,未來不論節點名稱叫“3nm”還是“N+4”,這些都不是重點,重點是芯片晶體管密度是否能夠大幅度的提升。
標題:沒有EUV光刻機,怎么做5nm芯片
地址:https://www.utechfun.com/post/390695.html